Программы для распознавания текста из pdf-документов
Содержание:
- Суть процедуры
- Каковы применения изображения в текст?
- Экспериментальные Материалы
- CAPTCHA,
- Как разобрать текст по фотографии
- Объединение полученных областей для окончательного результата обнаружения текста
- Программы
- Суть процедуры
- SimpleHTR модель
- Сервисы бесплатного распознавания текста с фото онлайн
- 10 лучших бесплатных программ для распознавания текста
- Особенности
- Возможности, предлагаемые Image to Text
- 1. Извлеките текст из изображений с низким разрешением.
- 2. Определите математические уравнения
- 4. Надежный и безопасный
- 5. Поддержка нескольких языков.
- 6. Извлеките текст с помощью URL.
- 7. Загрузите текстовый файл.
- 8. Скопируйте в буфер обмена.
- 9. Преобразование изображения в файл Word.
- 10. Доступен с любого устройства
- Бесплатное распознавание текста с картинки в онлайн-режиме
Суть процедуры
О каком же процессе в данном случае вообще идет речь? Обработка картинки или фото для того, чтобы текст, запечатленный на ней, автоматически был переведен в текстовый формат.
Тоесть, технически процесс происходит следующим образом: пользователь загружает картинку на сервер, либо переносит ее в программу, софт обрабатывает изображение, используя особые алгоритмы, и выдает в виде файла или в окне программы сфотографированный текст в печатном виде.
В настоящее время разработано достаточно много таких разнообразных программ.
Они отличаются по функционалу совсем незначительно, но могут существенно отличаться по качеству обработки.
Некоторые программы допускают достаточно много ошибок в распознаваемом тексте, тогда как другие – распознают все практически идеально.
Качество распознавания зависит от изначального качества фото, но при прочих равных условиях большую роль играют алгоритмы работу и обширность базы используемого приложения или онлайн-сервиса.
<Рис. 1 Особенности>
Важно! Такие программы могут быть представлены самостоятельным инсталлируемым софтом, простыми мобильными утилитами, способными работать с карты памяти, онлайн-сервиса, приложениями для смартфона и/или планшета. Распространяется такой софт платно или бесплатно, некоторые платные программы имеют ограниченные демо-версии.
Каковы применения изображения в текст?
Сегодня инструменты OCR используются практически во всех отраслях мира. Есть несколько факторов, которые привели к внедрению декодера изображений в текстовые инструменты. Здесь мы обсудим основные применения OCR в нашей повседневной жизни.
Правоохранительные органы
Немногие отрасли производят столько же документации, как юридический сектор, поэтому OCR имеет несколько приложений в этой области. Считыватель OCR можно использовать для оцифровки, хранения и поиска заявлений, представленных материалов, судебных решений, завещаний, письменных показаний под присягой и всех типов других документов.
Банковские и финансовые учреждения
Банковский сектор является основным потребителем OCR наряду с другими финансовыми отраслями, такими как ценные бумаги и страхование. Наиболее распространенное применение OCR в банковском деле — извлечение текста из чеков . Банки и другие финансовые учреждения используют эту технологию для извлечения текста из рукописных чеков и проверки подписей владельца. Распечатанные чеки также обрабатываются с использованием OCR.
Здравоохранение
OCR процветает в отрасли здравоохранения из-за деликатного характера этой области. Диагностика, страхование, история болезни и лечения пациентов можно получить из их больничных записей, которые можно сохранить в одном месте.
Благодаря тому, что все медицинские записи хранятся в цифровом виде, эпидемиологическое и логистическое развитие является большим стимулом. Этими записями пользуются несколько больниц, предлагающих огромную базу данных о здравоохранении, расходных материалах и законодательстве.
Помимо этих приложений, OCR можно использовать в:
- Электронные библиотеки
- Оптическое распознавание музыки
Экспериментальные Материалы
Все модели были реализованы с использованием Python и deep learning библиотеки Tensorflow. Tensorflow позволяет прозрачно использование высоко оптимизированных математических операций на графических процессорах с помощью Python. Вычислительный граф определяется в скрипте Python для определения всех операций, необходимых для конкретных вычислений. Графики для отчета были сгенерированы с помощью библиотеки matplotlib для Python, а иллюстрации созданы с помощью Inkscape-программы векторной графики, аналогичной Adobe Photoshop. Эксперименты проводились на машине с 2-кратным » Intel Процессоры Xeon(R) E-5-2680”, 4x » NVIDIA Tesla k20x” и 100 ГБ памяти RAM. Использование графического процессора сократило время обучения моделей примерно в 3 раза, однако это ускорение не было тщательно отслежено на протяжении всего проекта,поэтому оно могло варьироваться.
CAPTCHA,
Поскольку в Интернете полно роботов, обычная практика отличать их от реальных людей — это зрительные задачи, в частности чтение текста, или CAPTCHA. Многие из этих текстов являются случайными и искаженными, что затрудняет чтение на компьютере. Я не уверен, кто бы ни разрабатывал CAPTCHA, он предсказал достижения в области компьютерного зрения, однако большинство современных текстовых CAPTCHA не очень трудно решить, особенно если мы не пытаемся решить все из них сразу.
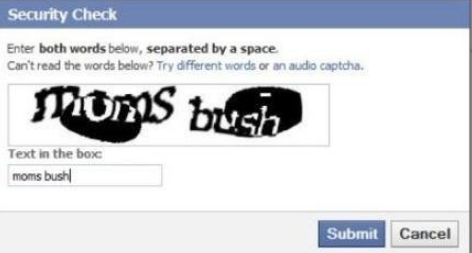
Facebook знает, как делать сложные капчи
Адам Geitgey обеспечиваетхороший учебникк решению некоторых CAPTCHA с глубоким обучением, которое включает в себя синтез искусственных данных еще раз.
Как разобрать текст по фотографии
Чтобы распознавание текста с помощью камеры проходило быстро, желательно предоставлять чистые документы, написанные понятным почерком без исправлений, а также использовать качественный сканер
Также важно правильно выбрать приложение для преобразования рукописей, гарантирующее точность полученных символов
Для чего вам может понадобится данная функция? Она достаточно часто упрощает жизнь студентов. Например, вам не хочется долго и муторно набирать текст, который нужно набрать вручную и в инете негде скопировать? Отлично! Самое время воспользоваться данным приложением. Также применяется в разных сферах деятельности, может пригодится уже и в дальнейшем на работе, например, юристу. Это здорово экономит время. Любая рукопись быстро оцифровывается, после чего в текст можно вносить любые изменения.
Для того, чтобы воспользоваться данной услугой, вам всего лишь нужно установить на свой смартфон приложение. Они доступны в магазинах Google Play и App Store. Можно воспользоваться и онлайн-сервисами, но учтите, что их функции несколько ограничены. Далее расскажем о нескольких популярных программах.
Объединение полученных областей для окончательного результата обнаружения текста
На данный момент, все результаты обнаружения состоят из отдельных текстовых символов. Чтобы использовать эти результаты для задач распознавания, отдельные символы текста должны быть объединены в слова или строки. Это позволяет распознавать слова в изображении, которые несут более значимую информацию, чем просто отдельные буквы.
Для того чтобы, объединить отдельные регионы в слова или строки текста, необходимо сначала найти текст из соседних регионов, а затем сформировать рамку вокруг этих регионов. Чтобы найти соседние регионы нужно расширить рамки, вычисленные ранее regionprops.
% Get bounding boxes for all the regions
bboxes = vertcat(mserStats.BoundingBox);
% Convert from the bounding box format to the format for convenience.
xmin = bboxes(:,1);
ymin = bboxes(:,2);
xmax = xmin + bboxes(:,3) - 1;
ymax = ymin + bboxes(:,4) - 1;
% Expand the bounding boxes by a small amount.
expansionAmount = 0.02;
xmin = (1-expansionAmount) * xmin;
ymin = (1-expansionAmount) * ymin;
xmax = (1+expansionAmount) * xmax;
ymax = (1+expansionAmount) * ymax;
% Clip the bounding boxes to be within the image bounds
xmin = max(xmin, 1);
ymin = max(ymin, 1);
xmax = min(xmax, size(I,2));
ymax = min(ymax, size(I,1));
% Show the expanded bounding boxes
expandedBBoxes = ;
IExpandedBBoxes = insertShape(colorImage,'Rectangle',expandedBBoxes,'LineWidth',3);
figure
imshow(IExpandedBBoxes)
title('Expanded Bounding Boxes Text')

Теперь, перекрывающиеся рамки могут быть объединены вместе, чтобы сформировать один ограничивающий прямоугольник вокруг отдельных слов или строк текста. Для этого вычисляют коэффициент перекрытия между всеми парами ограничивающего прямоугольника. Это определяет расстояние между всеми парами текстовых регионов, так чтобы в нем можно найти группы из соседних регионов имеющие ненулевые коэффициенты перекрытия. После попарного перекрытия используя graph вычисляются коэффициенты, чтобы найти все текстовые регионов «связанные» с ненулевыми коэффициентами перекрытия.
Мы будем использовать функцию bboxOverlapRatio, для вычисления парных коэффициентов перекрытия для всех расширенных рамок, а затем воспользуемся graph для поиска всех подключенных регионов.
% Compute the overlap ratio overlapRatio = bboxOverlapRatio(expandedBBoxes, expandedBBoxes); % Set the overlap ratio between a bounding box and itself to zero to % simplify the graph representation. n = size(overlapRatio,1); overlapRatio(1:n+1:n^2) = 0; % Create the graph g = graph(overlapRatio); % Find the connected text regions within the graph componentIndices = conncomp(g);
Выходные данные conncomp являются индекса регионов содержащих текст ограниченные рамками. Используя эти показатели, мы можем объединить несколько соседних рамок, в единую рамку путем вычисления минимального и максимального из индивидуальных ограничительных блоков, которые составляют каждую компоненту связности.
% Merge the boxes based on the minimum and maximum dimensions. xmin = accumarray(componentIndices', xmin, [], @min); ymin = accumarray(componentIndices', ymin, [], @min); xmax = accumarray(componentIndices', xmax, [], @max); ymax = accumarray(componentIndices', ymax, [], @max); % Compose the merged bounding boxes using the format. textBBoxes = ;
Наконец, прежде чем показывать окончательные результаты обнаружения, необходимо избавиться от плохо обнаруженного текста.
% Remove bounding boxes that only contain one text region
numRegionsInGroup = histcounts(componentIndices);
textBBoxes(numRegionsInGroup == 1, :) = [];
% Show the final text detection result.
ITextRegion = insertShape(colorImage, 'Rectangle', textBBoxes,'LineWidth',3);
figure
imshow(ITextRegion)
title('Detected Text')

Программы
Какие же программы используются для распознавания?
Они делятся на две группы: платные и бесплатные установочные программы, платные и бесплатные мобильные утилиты.
<Рис. 7 FineReader>
Требующие установки
Такой софт подойдет тем, кто постоянно работает с изображениями с текстом.
Кроме того, такой софт, обычно, наиболее функциональный.
| Программа | Тип лицензии | Функционал | Особенности | Рейтинг |
|---|---|---|---|---|
| ABBYY FineReader | Платно | Полный | Подходит для профессионального распознавания текста | 4,0 |
| CuneiForm | Бесплатно | Суженный | Неплохой функционал, но меньший, чем в платных аналогах | 2,9 |
| ABBYY PDF Transformer | Платно | Расширенный | Программа предназначена для выполнения широкого спектра работ с файлами PDF, в том числе и с распознаванием текста со сканов | 3,4 |
| Readiris Pro | Платно | Более узкий, по сравнению с другими платными аналогами | Довольно неудобное меню и управление, из-за которого программа не пользуется популярностью | 3,0 |
Суть процедуры
О каком же процессе в данном случае вообще идет речь? Обработка картинки или фото для того, чтобы текст, запечатленный на ней, автоматически был переведен в текстовый формат.
Тоесть, технически процесс происходит следующим образом: пользователь загружает картинку на сервер, либо переносит ее в программу, софт обрабатывает изображение, используя особые алгоритмы, и выдает в виде файла или в окне программы сфотографированный текст в печатном виде.
В настоящее время разработано достаточно много таких разнообразных программ.
Они отличаются по функционалу совсем незначительно, но могут существенно отличаться по качеству обработки.
Некоторые программы допускают достаточно много ошибок в распознаваемом тексте, тогда как другие – распознают все практически идеально.
Качество распознавания зависит от изначального качества фото, но при прочих равных условиях большую роль играют алгоритмы работу и обширность базы используемого приложения или онлайн-сервиса.

<Рис. 1 Особенности>
Важно! Такие программы могут быть представлены самостоятельным инсталлируемым софтом, простыми мобильными утилитами, способными работать с карты памяти, онлайн-сервиса, приложениями для смартфона и/или планшета. Распространяется такой софт платно или бесплатно, некоторые платные программы имеют ограниченные демо-версии.
SimpleHTR модель
Предлагаемая система использует ANN, при этом для извлечения объектов используются многочисленные слои CNN с входной фотографии. Затем выход этих слоев подается в RNN. RNN распространяет информацию через последовательность. Вывод RNN содержит вероятности для каждого символа в последовательности. Для прогнозирования конечного текста реализуются алгоритмы декодирования в выход RNN. Функции CTC отвечают за декодирование вероятностей в окончательный текст. Для повышения точности распознавания декодирование может также использовать языковую модель. CTC используется для получения знаний; выход RNN представляет собой матрицу, содержащую вероятности символов для каждого временного шага. Алгоритм декодирования CTC преобразует эти символические вероятности в окончательный текст. Затем, чтобы повысить точность, используется алгоритм, который продолжает поиск слов в словаре. Однако время, необходимое для поиска фраз, зависит от размеров словаря, и он не может декодировать произвольные символьные строки, включая числа.
Операции: CNN: входные изображения подаются на слои CNN. Эти слои отвечают за извлечение объектов. Есть 5х5 фильтры в первом и втором слоях и фильтры 3х3 в последних трех слоях. Они также содержат нелинейную функцию RELU и максимальный объединяющий слой, который суммирует изображения и делает их меньше, чем входные данные. Хотя высота изображения уменьшается в 2 раза в каждом слое, карты объектов (каналы) добавляются таким образом, чтобы получить выходную карту объектов (или последовательность) размером от 32 до 256. RNN: последовательность признаков содержит 256 признаков или симптомов на каждом временном шаге. Соответствующая информация распространяется РНН через эти серии. LSTM-это один из известных алгоритмов RNN, который переносит информацию на большие расстояния и более эффективное обучение, чем типичные РНН. Выходная последовательность RNN сопоставляется с матрицей 32х80.
CTC: получает выходную матрицу RNN и прогнозируемый текст в процессе обучения нейронной сети, а также определяет величину потерь. CTC получает только матрицу после обработки и декодирует ее в окончательный текст. Длина основного текста и известного текста не должна превышать 32 символов
Модель SimpleHTR, где зеленые значки — это операции, а розовые- потоки данных
Данные: Входные данные: это файл серого цвета размером от 128 до 32. Изображения в наборе данных обычно не имеют точно такого размера, поэтому их исходный размер изменяется (без искажений) до тех пор, пока они не станут 128 в ширину и 32 в высоту. Затем изображение копируется в целевой образ размером от 128 до 32. Затем значения серого цвета стандартизируются, что упрощает процесс нейронной сети.
Сервисы бесплатного распознавания текста с фото онлайн
Хочу заменить, что качество, получаемое при считывании текста с картинки, зависит от следующих факторов:
- качества исходника;
- размера элементов и четкости символов на отсканированном материале;
- формата файла.
Вашему вниманию представляю подборку сервисов, позволяющих преобразовать картинку в текст онлайн. Большинство из них бесплатные, а об имеющихся ограничениях, я упомяну в отдельной таблице. Большинство сайтов на английском языке.
Сравнение онлайн распознавателей текста с фото или PDF смотрите в таблице ниже:
Сервис от Гугл
Чтобы перевести с текст с фото в ворд понадобится электронная почта gmail. С ее помощью вы получите доступ ко многим сервисам от Google. Ограничений по количеству файлов нет, как и по их объему.
После этого кликаете по нему правой кнопкой и выбираете в меню открыть с помощью “Google Документы”:
Результат перевода текста с картинки в ворд будет помещен в Google Документы и откроется на соседней вкладке. Далее вы можете его там редактировать или скопировать на компьютер в одном из форматов:
Abbyy Finereader Online
Это онлайн распознаватель текста с pdf или изображения в word, аналог одноименной программы для ПК. Файн ридер онлайн позволяет бесплатно распознать до 5 страниц в месяц и то только после регистрации. Плюс бонусом предоставляется 10 страниц после подтверждения имейла. Стоимость платного пакета услуг — 129 € / год на 5000 страниц.
Как использовать сервис показано на скрине — всего 5 шагов к получению текста с фото или pdf в ворд онлайн:
Ссылка для перехода finereaderonline.com
Online OCR
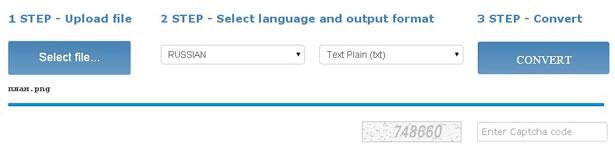
Отличный сервис распознавания текста с фото или из pdf с приемлемыми ограничениями в формате гостевого доступа, т.е. без регистрации на сайте. Позволяет произвести преобразование картинки в текст онлайн в количестве до 15 штук в час или 15 страниц в многостраничном PDF файле
Обратите внимание, что для работы с PDF документами понадобится регистрация
Ссылка на сам сервис OnlineOCR.net
Как вытащить текст из картинки в word этим сервисом смотрите ниже на скрине:
Отличительная особенность — в получаемых результатах изображения сохраняются с текстом. В других сервисах, что будут описаны ниже такого нет.
Free Online OCR
Довольно неплохой бесплатный и не имеющий ограничений по количеству файлов переводчик текста с картинки онлайн. Один его недостаток — сохранение результата без изображений с источника.
Для открытия сайта кликните newocr.com
Выбираем файл, ниже уже будет добавлено 2 языка, при необходимости добавьте другие. Кликните по кнопке «Upload & OCR»:
Изображение будет автоматически загружено и распознано. Результаты можно сохранить в документ или скопировать прямо из сайта:
Есть возможность выделить участок на изображении для распознавания. А также несколько разных языков.
OCR Convert
Распознавание текста с картинки онлайн сервисом OCR Convert происходит не мгновенно! Вам предлагают оставить имейл, на который придет оповещении об удачном завершении распознавания. И скачать готовый файл можно в течении 24 часов, дальше он будет удален автоматически. Это главный минус данного сайта!
Работать просто, выберите файл, язык и кликните по кнопке «Convert»:
Soda PDF OCR
Многофункциональный сервис для работы с PDF документами. Полный список возможностей представлен на скрине ниже, но нас в первую очередь интересует распознавание текста из pdf в word онлайн.
Загрузите файл и получите расшифрованный документ.
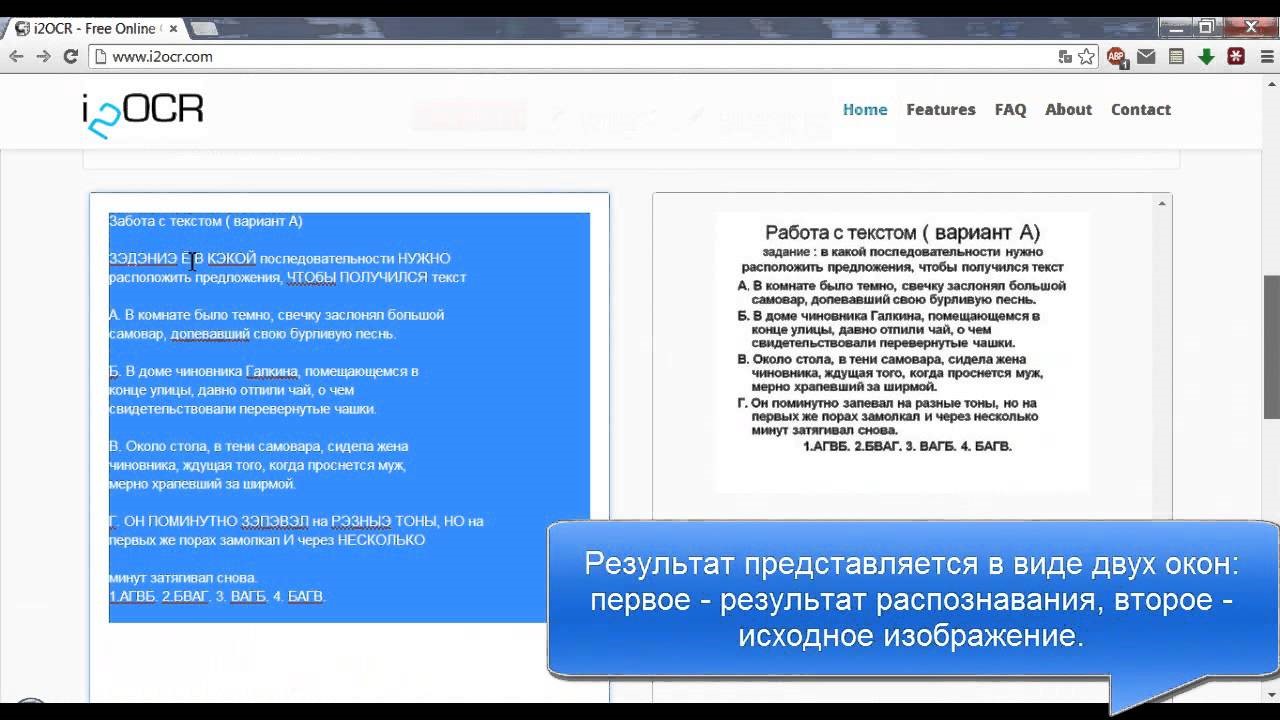
I2OCR
Работать с сайтом просто, всего 4 действия, чтобы преобразовать фото в текст:
- Выбираем язык.
- Загружаем файл.
- Подтверждаем, что мы не робот.
- Кликаем по кнопке «Extract».
Ожидаем минутку и появляется возможность скопировать текст с картинки онлайн на свой компьютер в одном из форматов по кнопке «Download».
OCR от Яндекс
Его назначение — перевод текста из подгруженного изображения, но с задачей сканировать текст с фотографии онлайн он успешно справляется. Работает без регистрации и каких-либо ограничений.
Вот таким не хитрым способом, используя яндекс переводчик не по назначению нам удалось скопировать текст с картинки онлайн.
10 лучших бесплатных программ для распознавания текста
1. PDFelement
PDFelement обеспечивает удобную работу с отсканированными PDF-документами благодаря передовой технологии оптического распознавания символов. Эта функция позволяет распознавать текст отсканированных PDF-файлов, чтобы сделать текст и файл редактируемыми. Кроме того, с его помощью вы можете конвертировать ваши отсканированные PDF-файлы в другие редактируемые форматы, включая Excel, Word, PPT, Text и другие. Качество вашего оригинального документа будет полностью сохранено.
PDFelement оснащен мощными инструментами редактирования, которые позволяют вставлять, удалять или изменять текст, изображения и страницы. Вы также можете заполнять интерактивные и неинтерактивные формы и создавать новые формы с различными вариантами их заполнения.
Руководство:Как Скопировать Текст из Изображения
2. FreeOCR
Полностью бесплатный онлайн-инструмент для распознавания текста, который не требует регистрации или указания адреса электронной почты. Работает с различными файлами изображений, включая GIF, JPG, BMP, TIFF или PDF с многостолбцовым текстом. Распознает более 30 различных языков. Размер загрузки ограничен до 2 МБ или 5000 пикселей, можно загружать не более 10 изображений в час.
4. Online OCR
Online OCR позволяет конвертировать фотографии и цифровые изображения в текст. Распознает тексты на 32 языках и конвертирует отсканированные PDF-файлы в Word, RTF и текстовые форматы. С помощью данной программы можно также извлекать текст из изображений в форматах JPG, JPEG, BMP, TIFF и GIF и преобразовывать его в редактируемые документы Word, TXT, PDF, Excel или HTML. Конвертирование до 15 изображений в час.
5. Free Online OCR
Free Online OCR позволяет конвертировать скриншоты, отсканированные документы, факсы и фотографии в форматы текст с возможностью поиска и редактирования, например, TXT, DOC, RTF и PDF. Программа поддерживает такие форматы, как BMP, PDF, PNG, TIFF, JPG(JPEG), и GIF.
6. Cvisiontech
Cvisiontech также поддерживает одновременную загрузку нескольких файлов TIFF, PDF, BMP и JPG. Перед загрузкой необходимо убедиться, что размер любого из загруженных файлов менее 100 МБ. Программа позволяет сжимать файлы и оптимизировать их для веб-сайта.
7. SuperGeek Free Document OCR
SuperGeek Free Document OCR – удобная и мощная программа для конверирования изображений и распознавания текста (OCR), подходящая как для профессионального, так и для домашнего использования. Позволяет читать текст из JPG, JPEG, TIF, TIFF, PNG, BMP, PSD, GIF, EMF, WMF, J2K, DCX, PCX, JP2 и т.д. и конвертировать файлы данных типов в редактируемые документы MSWord и TXT всего за несколько кликов.
8. onOCR
Программа onOCR справляется с различными отсканированными PDF или файлами изображений независимо от их размера. Free OCR помогает преобразовывать нередактируемые документы в тексты с возможностью копирования и редактирования. Вы можете обрабатывать как крупные, так и мелкие изображения и преобразовывать их в редактируемый текст.
9. Investintech
Able2Extract от Investintech – это инструмент для работы PDF с возможностью конвертирования отсканированных PDF в один из более чем 10 различных типов редактируемых файлов. С его помощью вы можете преобразовывать файлы практически любого типа в защищенные PDF, просматривать и редактировать PDF и преобразованные файлы, а также извлекать текст из отсканированных документов.
10. OCRgeek
OCRGeek.com позволяет вам выполнять распознавать тексты онлайн в пакетном режиме. Вы можете без проблем загружать по несколько файлов одновременно. Процесс распознавания происходит быстро и просто. Загруженные вами документы будут организованы и одновременно преобразованы в формат TXT. Форматы ввода, которые поддерживает OCRgeek: JPG, PNG, TIFF, PDF, DJVU, GIF и BMP.
Особенности
Каждая программа способна работать только с теми символами, которые были занесены в ее базу, только их она распознает.
В программу может быть внесено несколько алфавитов, как уже писалось выше, поэтому, при выборе подходящего софта проверьте, что бы он работал с языком, на котором напечатан текст на вашей картинке.
Если речь идет о не слишком популярных и визуально нестандартных языках, то найти подходящий софт может быть непросто.
Чем сложнее форматирование или расположение букв на фотографии, тем сложнее программе правильно распознать текст, и тем больше будет ошибок.
Ведь иногда в таком случае неточности могут возникнуть уже на стадии определения местоположения печатных символов на картинке.
Распознавание текста, напечатанного на нестандартном языке, происходит с ошибками. Причем, часто чем сложнее этот текст, тем больше ошибок может быть, так как алгоритмы распознавания могут в этом случае работать неточно.
При определении буквы программа использует определенный «алгоритм» сравнений с ее основными чертами – расположением и размером элементов (некоторые утилиты также учитывают соседние распознанные буквы и лексическую сочетаемость).
Благодаря этой особенности, даже если небольшая часть буквы стерлась или изменена, она все еще может быть распознана.
Единственный минус данного способа в том, что когда букву не удается распознать, задействуются все алфавиты из базы для определения, и в результате может быть обнаружено больше сходств с буквой, например, английского алфавита, хотя текст напечатан на русском.
Перед началом процесса распознавания, обратите внимание на качество фото. Лучше всего определяется текст с отсканированных изображений документов, скриншотов
Лучше всего определяется текст с отсканированных изображений документов, скриншотов.
Более или менее нормально может быть определен и сфотографированный на камеру текст.
Хуже всего распознаются материалы с фото плохого качества, сделанного под углом, особенно если имеет место сложное форматирование.
Художественные шрифты не распознаются.
<Рис. 3 Онлайн-сервис>
Возможности, предлагаемые Image to Text
Особенности преобразования изображения в текст делают его конкурентоспособным и идеальным инструментом для чтения и получения текста из изображений.
Спрос на извлечение текста из изображений растет из-за растущей тенденции использования мультимедиа в образовании, электронной коммерции , финансах и других сферах деятельности.
Мы разработали уникальные и востребованные функции, которые позволяют нашим пользователям выполнять поиск по фотографиям и получать по ним текст.
Давайте рассмотрим некоторые из классических функций этого приложения для преобразования изображений в текст.
1. Извлеките текст из изображений с низким разрешением.
Студенты часто делают фотографии книжных страниц и заметок во время занятий в классе, чтобы подготовиться к экзаменам. В большинстве случаев эти изображения получаются размытыми или с низким разрешением из-за плохого качества камеры.
Есть вероятность, что вы неправильно поймете текст на этих изображениях, и его переписывание может потратить много времени.
Средство извлечения текста также может извлекать текст из размытых изображений с низким разрешением. Не нужно тратить время на набор текста с картинок самостоятельно.
Это изображение в текстовом редакторе заставляет вас делать умную работу вместо тяжелой работы.
2. Определите математические уравнения
Вы любите решать математические уравнения?
Если да, возможно, у вас есть с собой картинки с алгебраическими или геометрическими формулами. Хорошая новость в том, что этот инструмент не только получает простой текст, но и извлекает сложные математические уравнения как профессионал.
Вы можете попробовать любое изображение, содержащее уравнения, прямо сейчас, если хотите.
Обеспокоены ограничениями загрузки? Тебе это не нужно.
Вы можете загружать отсканированные заметки, книги, изображения и фотографии в любом количестве. Наше бесплатное программное обеспечение будет предоставлять точные результаты каждый раз, не требуя от вас выполнения многих или каких-либо альтернативных шагов.
4. Надежный и безопасный
С нами вы в безопасности. Мы всегда стремимся и обещаем сохранить ваши данные в безопасности. Мы придерживаемся нашей политики, согласно которой мы не будем передавать ваши данные третьим лицам и не будем хранить их в нашей базе данных.
5. Поддержка нескольких языков.
Инструмент преобразования изображения в текст предлагает поддержку нескольких языков. Он может переводить изображения в текст на более чем шести языках.
Изображения, содержащие текст на языках, отличных от английского, можно очень легко преобразовать в текст с помощью нашего инструмента. Некоторые из поддерживаемых языков включают:
- английский
- Español
- Deutsche
- Русский
- португальский
6. Извлеките текст с помощью URL.
Помимо параметров загрузки, изображение можно преобразовать в текст, вставив URL-адрес изображения в поле URL-адреса. Эта функция очень полезна, когда вы путешествуете по Интернету и сталкиваетесь с изображением, содержащим текст.
Вы можете скопировать URL-адрес этого изображения и вставить его в заданное поле ввода, чтобы напрямую вытащить текст из него.
7. Загрузите текстовый файл.
Данные могут быть потеряны или потеряны, если не сохранены должным образом. Вы можете напрямую загрузить преобразованный текст в виде файла вместо копирования текста.
Эта функция экономит время и важные данные в локальном хранилище вашего устройства.
8. Скопируйте в буфер обмена.
Если вы хотите сохранить результаты как временные данные или вам не нужно загружать файл, скопируйте в буфер обмена — это быстрый способ скопировать преобразованный текст.
Вы можете скопировать его в буфер обмена и позже вставить в нужный файл или каталог.
9. Преобразование изображения в файл Word.
После преобразования изображения в текст вы можете сохранить результат непосредственно в файл с помощью функции «Сохранить как документ».
Таким образом, вы можете преобразовывать изображения в текст в Microsoft Word и использовать его для дальнейших целей.
10. Доступен с любого устройства
Мы в курсе последних тенденций и технологий, а удобство использования — наш главный приоритет. Инструмент Google для преобразования изображений в текст можно использовать на мобильных устройствах, и он отлично выполняет преобразование изображений в текст.
Теперь вы можете рисовать текст с любого изображения из любого места с помощью мобильного телефона.
Бесплатное распознавание текста с картинки в онлайн-режиме
Файловый хостинг Google Диск. Доступ к сервису осуществляется с общей учетной записи Google. Если ее нет, необходимо зарегистрироваться, чтобы воспользоваться инструментом.
Пользователи могут загружать изображения в разных форматах: PNG, JPG и GIF. Их размер не должен превышать двух мегабайт. Помимо этого, есть возможность распознавать данные с документов в формате PDF, но с некоторыми ограничениями. Так, если загрузить файл PDF с несколькими десятками страниц, то обработаются только первые десять листов. Результат сохраняется во все популярные форматы файлов.
OCR Convert. Онлайн-сервис предоставляет полностью бесплатные услуги по преобразованию картинок в электронный редактируемый формат. Изначально сайт был для англоязычных пользователей, но сейчас доступен на многих европейских и восточных языках. Чтобы воспользоваться инструментом, не нужно регистрировать учетную запись. Существует несколько способов загрузить исходный материал:
- Через нажатие кнопки «Выбрать файлы». Далее открывается проводник, предлагающий выбрать документ на компьютере. Можно использовать PDF, GIF, BMP и JPEG-форматы.
- Через ссылку на изображение, размещенное на сайте или в файлообменнике.
К примеру, для распознавания китайского текста с картинки в онлайн-режиме принцип работы будет следующий: после загрузки документа следует выбрать язык, на котором напечатан материал (доступно более 30 различных языков), а также формат конвертирования — только TXT. Пользователь может добавлять на сайт до пяти материалов, размером не более 5 мегабайт каждое.
NewOCR. Бесплатный сайт, не требующий регистрации. По мнению пользователей, является наиболее интересным и полезным инструментом. Связано это с тем, что веб-сервис поддерживает все популярные форматы и может распознать текст с картинки в Word. При этом можно загружать несколько изображений разных форматов одновременно. В NewOCR есть интерфейс для работы: с помощью встроенных инструментов можно увеличивать «нужное место», отделять его от неиспользуемой области.
Интерфейс представлен только на английском языке, но преобразование происходит на более чем 50 языках. Благодаря плагину Google-переводчика можно переводить на другие языки.
OCRonline. Это один из самых неудобных сайтов, поскольку требует, чтобы фотографии были высокого разрешения. И, хотя загружать можно документы с низким качеством, он довольно плохо справляется с распознаванием текста с такой картинки онлайн. Еще одним недостатком является еженедельный лимит — не более пяти страниц в семь дней. Результаты можно сохранять на ПК в популярных форматах. Чтобы получить доступ к неограниченному числу операций, необходимо купить подписку и зарегистрировать учетную запись.
Free-Ocr. Еще один бесплатный сервис, пользоваться которым можно без учетной записи. Однако получить результат можно только после ввода капчи. В отличие от OCRonline, где ограничение после пяти операций продолжается в течение недели, здесь лимит установлен на каждый час. Другими словами, пользователь может распознать текст с десяти картинки в Word, после чего придется ждать, когда по истечении времени ограничения можно будет преобразовать следующие 10 документов.