Файл robots.txt и мета-тег robots
Содержание:
- Что такое файл robots txt, зачем он нужен и за что он отвечает
- Как осуществляется проверка robots.txt в Google
- Структура robots.txt
- Синтаксис robots.txt
- Technical robots.txt syntax
- Правила настройки
- Для чего нужна проверка robots.txt
- Создание и редактирование robots.txt
- Как создать файл robots txt: подробная инструкция
- Robots.txt для Яндекса и Google
- Как редактировать и загружать robots.txt
- Заключение
Что такое файл robots txt, зачем он нужен и за что он отвечает
 Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Не зря файл robots txt называют важнейшим инструментом SEO, этот маленький файл напрямую влияет на индексацию страниц сайта и сайта в целом. И наоборот, неправильный robots txt может исключить некоторые страницы, разделы или сайт в целом из поисковой выдачи. В этом случае можно иметь и 1000 статей на блоге, а посетителей на сайте просто не будет, будут чисто случайные прохожие.
На Яндекс вебмастере есть обучающее видео, в котором Яндекс сравнивает файл роботс тхт с коробкой Ваших личных вещей, которые Вы не хотите никому показывать. Чтобы посторонние не заглядывали в эту коробку, Вы её заклеиваете скотчем и пишете на ней – «Не открывать».
Роботы, как воспитанные личности, эту коробку не открывают и другим не смогут рассказать, что там находится. Если файла robots txt нет, то робот поисковой системы считает, что все файлы доступные, он откроет коробку, всё посмотрит и другим расскажет, что лежит в коробке. Чтобы робот не лазил в этот ящик, надо запретить ему туда лазить, делается это с помощью директивы Disallow, что переводится с английского – запретить, а Allow – разрешить.
Это обычный txt файл, который составляется в обычном блокноте или программе NotePad++, файл, который предлагает роботам не индексировать определённые страницы на сайте. Для чего это нужно:
- правильно составленный файл robots txt не позволяет роботам индексировать всякий мусор и не забивать поисковую выдачу ненужным материалом, а также не плодить дубли страниц, что является очень вредным явлением;
- не позволяет роботам индексировать информацию, которая нужна для служебного пользования;
- не позволяет роботам шпионам воровать конфиденциальные данные и использования их для отправки спама.
Это не означает, что мы что-то хотим спрятать от поисковиков, что-то тайное, просто эта информация не несёт ценности ни для поисковиков, ни для посетителей. Например, страница логина, RSS ленты и т.д. Кроме того, файл robots txt указывает зеркало сайта, а также карту сайта. По умолчанию на сайте, который делается на WordPress, файла robots txt нет. Поэтому нужно создать robots txt файл и залить его в корневую папку Вашего блога, в данной статье мы рассмотрим robots txt для WordPress, его создание, корректировку и заливку на сайт. Итак, сначала мы узнаем, где находится файл robots txt?
Как осуществляется проверка robots.txt в Google
Инструмент Google Search Console позволяет вам провести проверку того, содержится ли в файле robots.txt запрет на сканирование роботом Googlebot определенных URL на вашем ресурсе. К примеру, у вас есть изображение, которое вы не хотите видеть в результатах поисковой выдачи Google по картинкам. С помощью инструмента вы узнаете, имеет ли робот Googlebot-Image доступ к этому изображению.
Для этого следует указать интересующий URL. После этого происходит обработка файла robots.txt инструментом проверки, аналогичная проверка роботом Googlebot. Это дает возможность определить, доступен ли этот адрес.
Процедура проверки:
После выбора вашего ресурса в Google Search Console перейдите к инструменту проверки, который выдаст вам содержание файла robots.txt. Выделенный текст – это ошибки в синтаксисе или логические. Их количество указывается под окном редактирования.
В нижней части страницы интерфейса вы увидите специальное окно, в которое нужно ввести URL.
Справа появится меню, из которого необходимо выбрать робота.
Нажмите на кнопку «Проверить».
Если в результате проверки выводится сообщение с текстом «доступен», это значит, что роботам Google разрешено посещать указанную страницу. Статус «недоступен» говорит о том, что доступ к ней роботам закрыт.
Если нужно, вы можете изменить меню и провести новую проверку
Внимание! Автоматического внесения изменений в файл robots.txt на вашем ресурсе не произойдет. Скопируйте изменения и внесите их в файл robots.txt на вашем веб-сервере
На что нужно обратить внимание:
- Сохранения сделанных в редакторе изменений на веб-сервере не происходит. Понадобится копирование полученного кода и вставки его в файл robots.txt.
- Получить результаты проверки файла robots.txt инструментом могут только агенты пользователя Google и роботы, относящиеся к Google (к примеру, робот Googlebot). При этом гарантии того, что интерпретация содержания вашего файла роботами других поисковых систем будет аналогичной, нет.
Вас также может заинтересовать: Шпаргалка по настройке 301 редиректа
Структура robots.txt
Строение файла выглядит просто. Он включает ряд блоков, адресованных конкретным ботам-поисковикам. В этих блоках прописываются директивы (команды) для управления ходом индексации.
Дополнительно можно проставлять комментарии. Чтобы они игнорировались поисковиком, нужно использовать знак #. Каждый комментарий начинается и заканчивается этим символом. Кроме того, не рекомендуется вставлять символ комментария внутри директивы.
Robots.txt создаётся одним из удобных для вас методов:
- вручную с использованием текстового редактора, после чего он сохраняется с расширением *. txt.
- автоматически с применением онлайн-программ.
Большинство специалистов работают с файлом вручную — процесс достаточно прост, занимает немного времени, но при этом вы будете уверены в правильности его написания.
В любом случае, автоматически сформированные файлы обязательно подлежат проверке, ведь от этого зависит, насколько хорошо будет функционировать ваш сайт.
Синтаксис robots.txt
Синтаксис файла robots довольно прост. Он состоит из директив, каждая начинается с новой строки, через двоеточие задается необходимое значение для директивы.
Директивы чувствительны к регистру и должны начинаться с заглавной буквы.
Основными являются три директивы, которые рекомендуется применять в такой последовательности:
-
User-agent: указывается название поискового робота, для которого будут применятся правила
В одном файле robots можно использовать сразу несколько User-agent, обязательно разделяя их пустой строкой, к примеру: -
Disallow: указывается относительный путь директории или файла сайта, которые нужно запретить индексировать
- Allow: указывается относительный путь директории или файла, которые нужно разрешить поисковику индексировать (не является обязательной)
Для более гибкой настройки директив можно использовать дополнительные выражения:
- * (звездочка) — перебор всех значений, любая последовательность символов;
- $ (доллар) — конец строки;
- # (решетка) — позволяет вставить комментарий. Все что идет за этим символом — робот не воспринимает до конца следующей строки;
Пример:
Примечание: Файл robots.txt не рекомендуется сильно засорять, он не должен быть слишком габаритным (Google — до 500 кб, Yandex — до 32 кб), иначе поисковик его просто проигнорирует.
Technical robots.txt syntax
Robots.txt syntax can be thought of as the “language” of robots.txt files. There are five common terms you’re likely come across in a robots file. They include:
-
User-agent: The specific web crawler to which you’re giving crawl instructions (usually a search engine). A list of most user agents can be found here.
-
Disallow: The command used to tell a user-agent not to crawl particular URL. Only one «Disallow:» line is allowed for each URL.
-
Allow (Only applicable for Googlebot): The command to tell Googlebot it can access a page or subfolder even though its parent page or subfolder may be disallowed.
-
Crawl-delay: How many seconds a crawler should wait before loading and crawling page content. Note that Googlebot does not acknowledge this command, but crawl rate can be set in Google Search Console.
-
Sitemap: Used to call out the location of any XML sitemap(s) associated with this URL. Note this command is only supported by Google, Ask, Bing, and Yahoo.
Pattern-matching
When it comes to the actual URLs to block or allow, robots.txt files can get fairly complex as they allow the use of pattern-matching to cover a range of possible URL options. Google and Bing both honor two regular expressions that can be used to identify pages or subfolders that an SEO wants excluded. These two characters are the asterisk (*) and the dollar sign ($).
- * is a wildcard that represents any sequence of characters
- $ matches the end of the URL
Google offers a great list of possible pattern-matching syntax and examples here.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые — только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки

Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.

Такой вариант, наоборот, означает полный запрет индексации для всех.

Запрет на просмотр всего содержимого определенной папки-каталога

Для блокировки одного файла нужно указать его абсолютный путь

Директивы Sitemap, Host
В файл, как правило, добавляют ссылку на «Sitemap» (карту сайта), чтобы облегчить боту ее поиск.
Для Яндекса в директиве Host принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.

Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.

Директива Crawl-delay
С помощью нее можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.

Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Создание и редактирование robots.txt
- Если у вас еще нет файла, то нужно создать его с нуля. Откройте самый простой текстовый редактор (но не MS Word, т.к. нам нужен именно простой текстовый формат), к примеру, Блокнот (Windows) или TextEdit (Mac).
Примечания:
- Если, например, сайт реализован на CMS WordPress, то по умолчанию, вы не сможете найти его в корне сайта, так как «из коробки» его наличие не предусмотрено. Поэтому для редактирования его придется создать заново.
- Регистр имени файла важен! Название robots.txt указывается исключительно строчными буквами. Также убедитесь, что вы написали корректное название, НЕ «Robots» или «robot» – это наиболее частые ошибки при создании файла.
Как создать файл robots txt: подробная инструкция
Для создания такого файла можете использовать фактически любой редактор текста, например:
- Notepad;
- Блокнот;
- Sublime и др.
В этом «документе» описывается инструкция User-agent, а также указывается правило Disallow, но есть и прочие, не такие важные, но необходимые правила/инструкции для поисковых роботов.
User-agent: кому можно, а кому нет
Наиболее важная часть «документа» — User-agent. В ней указывается, каким именно поисковым роботам следует «посмотреть» инструкцию, описанную в самом файле.
В настоящее время существует 302 робота. Чтобы в документе не прописывать каждого отдельного робота персонально, необходимо указать в файле запись:
User-agent: *

Такая пометка указывает на то, что правила в файле ориентированы на всех поисковых роботов.
У поисковой системы Google основной поисковый робот Googlebot. Чтобы правила были рассчитаны только на него, необходимо в файле прописать:
User-agent: Googlebot_

При наличии такой записи в файле прочие поисковые роботы будут оценивать материалы сайта по своим основным директивам, предусматривающим обработку пустого robots.txt.
У Яндекс основной поисковый робот Yandex и для него запись в файле будет выглядеть следующим образом:
User-agent: Yandex

При наличии такой записи в файле прочие поисковые роботы будут оценивать материалы сайта по своим основным директивам, предусматривающим обработку пустого robots.txt.
Прочие специальные поисковые роботы
- Googlebot-News — используется для сканирования новостных записей;
- Mediapartners-Google — специально разработан для сервиса Google AdSense;
- AdsBot-Google — оценивает общее качество конкретной целевой страницы;
- YandexImages — проводит индексацию картинок Яндекс;
- Googlebot-Image — для сканирования изображений;
- YandexMetrika — робот сервиса Яндекс Метрика;
- YandexMedia — робот, индексирующий мультимедиа;
- YaDirectFetcher — робот Яндекс Директ;
- Googlebot-Video — для индексирования видео;
- Googlebot-Mobile — создан специально для мобильной версии сайтов;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, он проводит сканирование не только постов, но даже комментарие;
- YandexDirect — разработан для того, чтобы анализировать наполнение партнерский сайтов Рекламной сети. Это позволяет определить тематику каждого сайта и более эффективно подбирать релевантную рекламу;
- YandexPagechecker — валидатор микроразметки.
Перечислять прочих роботов не будем, но их, повторимся, всего насчитывается более 300-т. Каждый из них ориентирован на те или иные параметры.
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как редактировать и загружать robots.txt
Есть несколько способов создать файл robots.txt — либо сделать его вручную в текстовом редакторе и разместить в корневом каталоге (папка самого верхнего уровня на сервере), либо воспользоваться специальными плагинами для настройки файла.
Как создать robots.txt в Блокноте
Самый простой способ создать файл robots.txt — написать его в блокноте и загрузить на сервер в корневой каталог.
Лучше не использовать стандартное приложение — воспользуйтесь специальными редакторы текста, например, Notepad++ или Sublime Text, которые поддерживают сохранение файла в конкретной кодировке. Дело в том, что поисковые роботы, например, Яндекс и Google, читают только файлы в UTF-8 с определенными переносами строк — стандартный Блокнот Windows может добавлять ненужные символы или использовать неподдерживаемые переносы.
Говорят, что это давно не так, но чтобы быть уверенным на 100%, используйте специализированные приложения.
Рассмотрим создание robots.txt на примере Sublime Text. Откройте редактор и создайте новый файл. Внесите туда нужные настройки, например:
Где mysite.ru — домен вашего сайта.
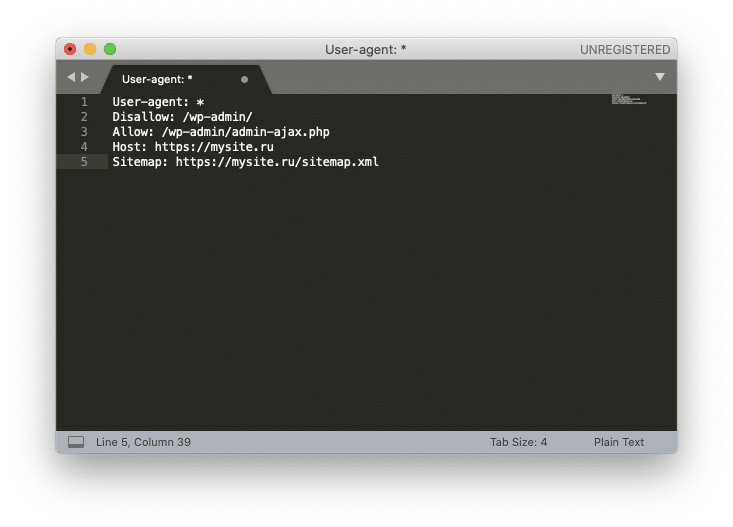
После того, как вы записали настройки, выберите в меню File ⟶ Save with Encoding… ⟶ UTF-8 (или Файл ⟶ Сохранить с кодировкой… ⟶ UTF-8).
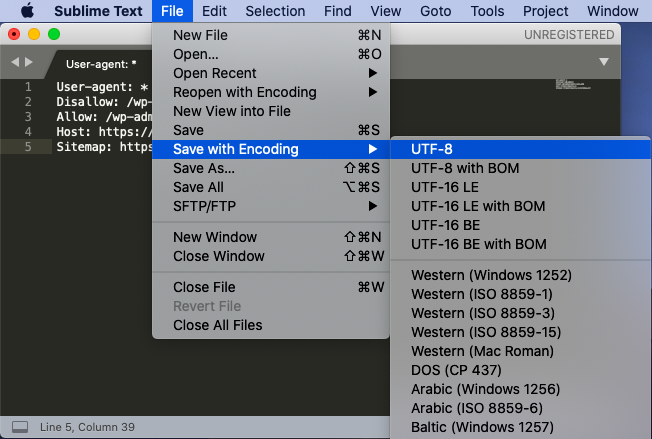
Назовите файл “robots.txt” (обязательно с маленькой буквы).
Файл готов к загрузке.
Загрузить robots.txt через FTP
Для того, чтобы загрузить созданный robots.txt на сервер через FTP, нужно для начала включить доступ через FTP в настройках хостинга.

После этого скопируйте настройки доступа по FTP: сервер, порт, IP-адрес, логин и пароль (не совпадают с логином и паролем для доступа на хостинг, будьте внимательны!).
Чтобы загрузить файл robots.txt вы можете воспользоваться специальным файловым менеджером, например, FileZilla или WinSCP, или же сделать это просто в стандартном Проводнике Windows. Введите в поле поиска “ftp://адрес_FTP_сервера”.

После этого Проводник попросит вас ввести логин и пароль.

Введите данные, которые вы получили от хостинг-провайдера на странице настроек доступа FTP. После этого в Проводнике откроются файлы и папки, расположенные на сервере. Скопируйте файл robots.txt в корневую папку. Готово.
Загрузить или создать robots.txt на хостинге
Если у вас уже есть готовый файл robots.txt, вы можете просто загрузить его на хостинг. Зайдите в файловый менеджер панели управления вашим хостингом, нажмите на кнопку «Загрузить» и следуйте инструкциям (подробности можно узнать в поддержке у вашего хостера.

Многие хостинги позволяют создавать текстовые файлы прямо в панели управления хостингом. Для этого нажмите на кнопку «Создать файл» и назовите его “robots.txt” (с маленькой буквы).

После этого откройте его во встроенном текстовом редакторе хостера. Если вам предложит выбрать кодировку для открытия файла — выбирайте UTF-8.

Добавьте нужные директивы и сохраните изменения.

Заключение
Итак, в данной статье мы рассмотрели вопрос, что собой представляет файл robots txt, выяснили, что этот файл является очень важным для сайта. Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Из статьи стало понятно, что новичкам, на первых порах, лучше использовать готовый и правильный robots txt, но надо не забыть заменить в нем в директории Host домен на свой, а также прописать адрес своего блога в картах сайта. Скачать мой файл robots txt можно здесь. Теперь, после исправления, можете использовать файл на своем блоге.
Отдельно по файлу robots txt есть сайт Вы можете зайти на него и узнать более подробную информацию. Надеюсь, у Вас всё получится и блог будет хорошо индексироваться. Удачи Вам!
P.S. Для правильного продвижения блога надо правильно писать о оптимизировать статьи на блоге, тогда на нём будет высокая посещаемость и рейтинги. В этом Вам помогут мои инфопродукты, в которые вложен мой трёхлетний опыт. Можете получить следующие продукты:
- пошаговый алгоритм написания мощных статей для блога;
- платная книга Как написать статью для блога;
- интеллект карта Пошаговый алгоритм создания блога (сайта) для новичков;
- платный видео-курс «Как написать и оптимизировать статью для блога. Продвижение блога статьями«.
Просмотров: 12484