Что такое веб-архив и как им пользоваться
Содержание:
- Как проверять полученные статьи на уникальность
- Где можно найти сторис в мобильной версии ВК?
- Как найти уникальный контент для своего сайта
- Как пользоваться веб архивом
- Что такое архивация в Инстаграм
- Проблемы архивирования
- Что такое веб-архив и зачем он нужен?
- Смотрим, как выглядела страница раньше
- Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
- финансирование
- Разбираем на примере как правильно подойти к оценке первичной информации
- Как добавить современную версию сайта в веб-архив Wayback Machineи выполнить другие действия
- Как пользоваться веб-архивом?
- Компании, архивирующие интернет
- Инструкция по получению уникальных статей с вебархива
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Где можно найти сторис в мобильной версии ВК?
После того как разработчики приложения внесли опцию сохранения сторис, публикации не удаляются в автоматическом режиме безвозвратно. Сохраняются видеоролики в специальном разделе – архив. Все ваши публикации будут находиться именно в архиве.
Инструкция как открыть архив в мобильной версии ВК:
- Открываем главную страницу вашего профиля, затем кликаем на 3 точки верху экрана.
Находим три точки на профиле
- В открытом меню выбираем «Архив историй»;
Нажимаем на «Архив историй»
- Загружается список ваших историй за действующий месяц.
Архив историй
Открывая историю, можно посмотреть, кто видел их, данная информация представлена в качестве иконки в виде глаза. В одном из углов экрана будут размещены 3 точки. Если кликнуть на них появиться меню, как раз из него можно будет и сохранить историю на мобильный телефон.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».
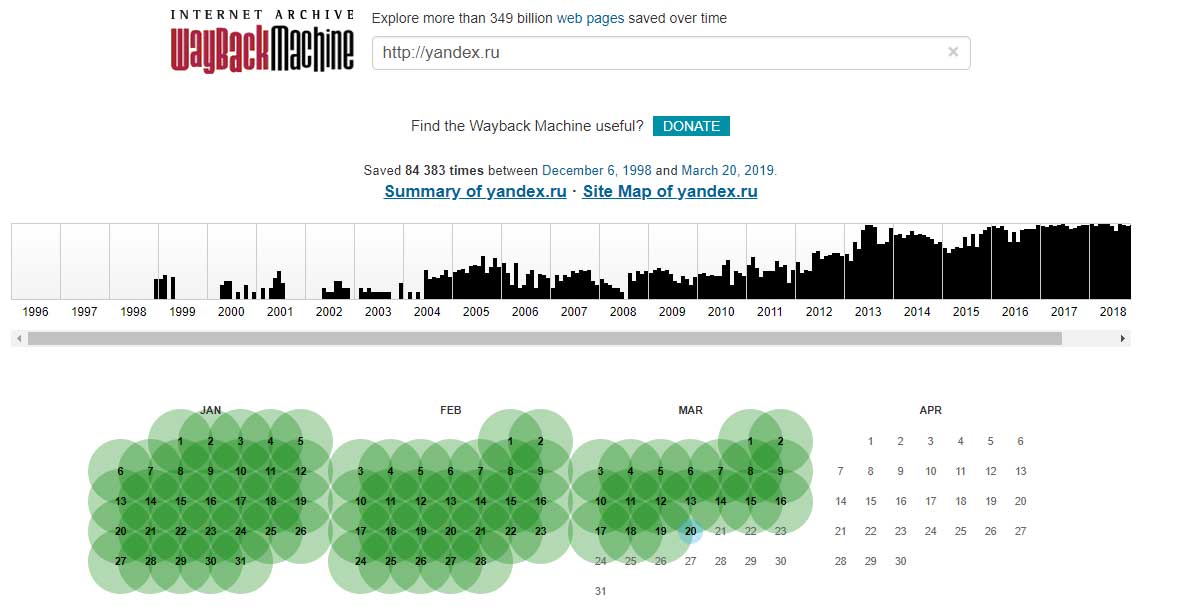
Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Что такое архивация в Инстаграм
Чтобы заархивировать публикации или Историю, пользователь должен нажать над снимком: «Отправить в Архив».
Посмотреть Архив в Инстаграме может только владелец страницы. Раздел находится в верхней панели, рядом с никнеймом учетной записи и меню «Настроек». Разделен на две категории: для Публикаций и Историй. Переходя, владелец аккаунта указывает какой тип данных ему необходим.
Основные функции архива Историй и публикаций в Инстаграм:
- скрывать фото и видео от посторонних. Отправив в Архив, владелец страницы блокирует доступ к просмотру, комментированию и оценке;
- вернуть фото для повторного размещения. При этом, дата первоначальной публикации сохранена;
- функция «Удалить». Пост из Архива можно навсегда удалить;
- добавить в Актуальное. В Историии добавляют фотографии, которые ранее были опубликованы и добавлены в Архив.
Проще: персональный раздел для владельца страницы, куда он может отправить неинтересные или неподходящие снимки. Помогает при планировании ленты и составлении постов в едином стиле.
Проблемы архивирования
Сканеры
Для веб-архивов, которые полагаются на веб-сканеры, имеются следующие проблемы:
- Сайт может запретить для просмотра часть сайта как для веб-сканера, так и для пользователей.
- Часть сайта может быть скрыта в deep Web.
- Ловушки для сборщиков (Crawler traps), например, генерируемые календари и телефонные списки, могут привести к чрезвычайно большому или бесконечному количеству страниц.
- За время обхода сайта уже обойдённые страницы могут измениться.
Однако, технологии сбора способны выдавать в результате страницы с полностью работоспособными ссылками.
Общие ограничения
Иногда администратор сайта настраивает сервер так, что тот выдает нормальные документы лишь пользователям обычных браузеров, но генерирует иные данные для ботов, архиваторов, пауков и т. п. автоматических программ. Это делается с целью обмана поисковых систем или же для увеличения пропускной способности канала, чтобы веб-сервер выдавал пригодный для просмотра материал для устройства и не скачивал ничего лишнего.
Веб-архив сталкивается и с юридическими проблемами. Сохранённый в нём документ может оказаться объектом интеллектуальной собственности, и правообладатель может потребовать удалить его. В других случаях веб-архив может подвергнуться преследованию со стороны какого-либо государства. Правовой основой (поводом) такого преследования обычно выступает законодательство об охране приватности либо о запрете распространения информации. Если архив находится в другой стране, юридическая процедура, ведущая к блокировке сайта, может пройти без ведома и участия владельца ресурса, и он теряет возможность защищаться и опротестовывать решение (если такая возможность предусмотрена).
Что такое веб-архив и зачем он нужен?

Веб-архив — история миллионов сайтов Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
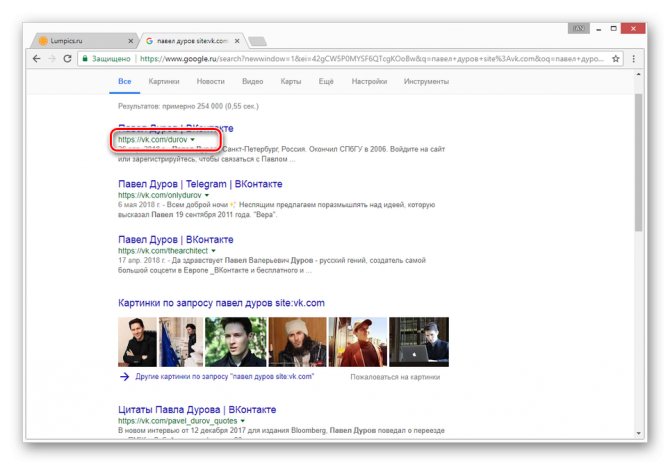
Из раскрывшегося списка выберите пункт «Сохраненная копия».
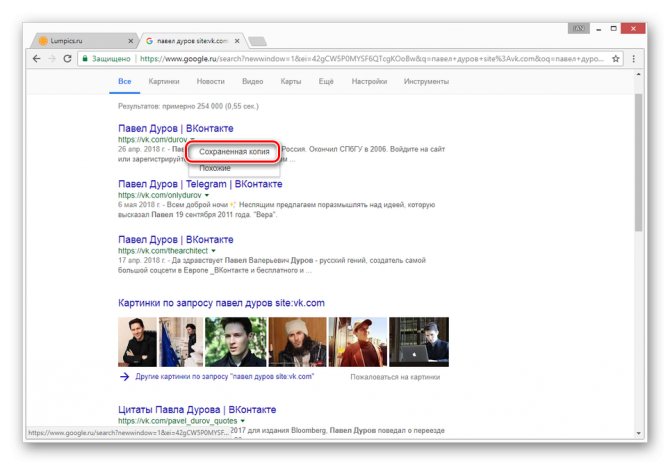
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
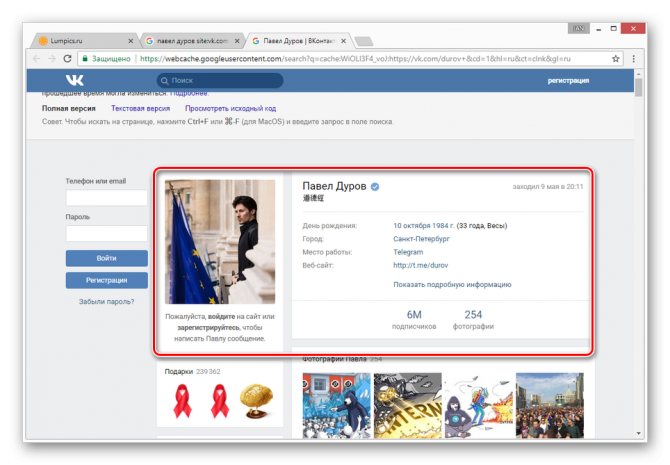
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
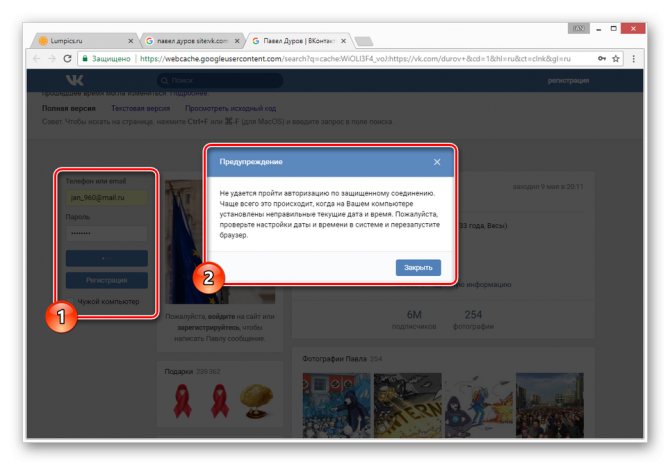
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
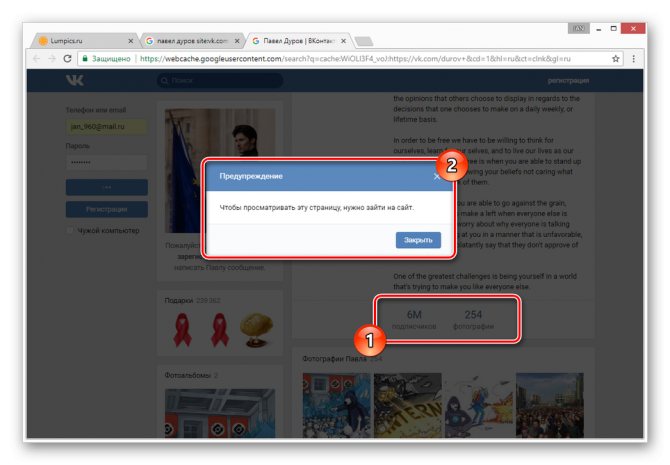
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
- После открытия ресурса по представленной выше ссылке в основное текстовое поле вставьте полный URL-адрес страницы, копию которой вам необходимо посмотреть.
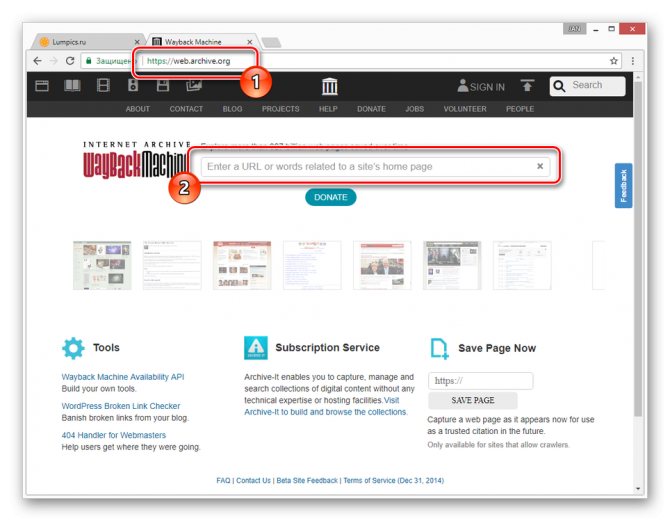
В случае успешного поиска вам будет представлена временная шкала со всеми сохраненными копиями в хронологическом порядке.
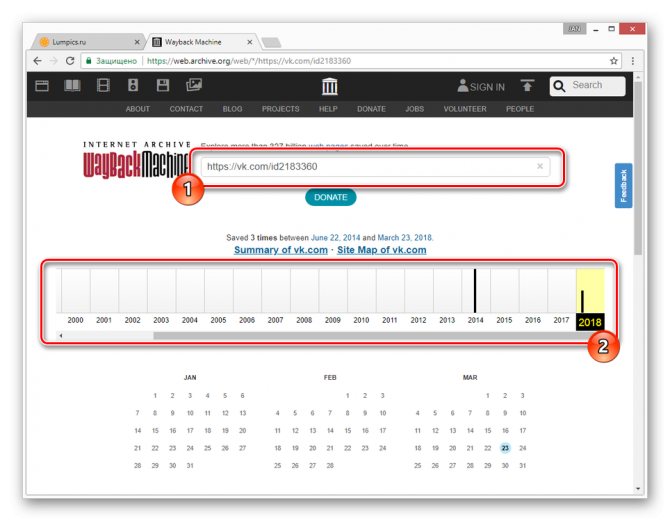
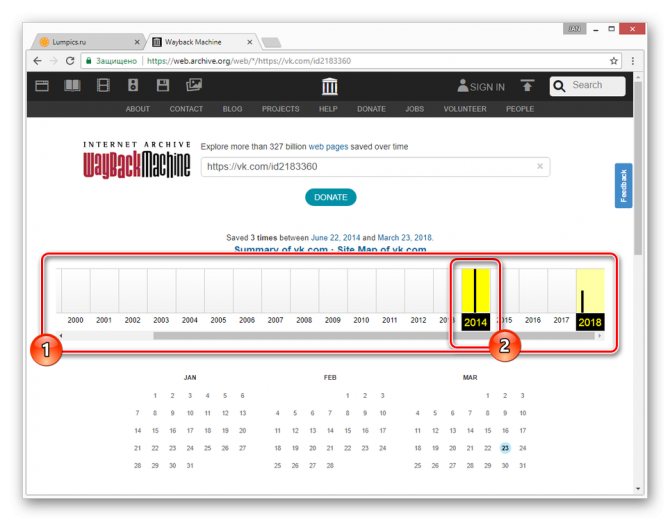
Переключитесь к нужной временной зоне, кликнув по соответствующему году.
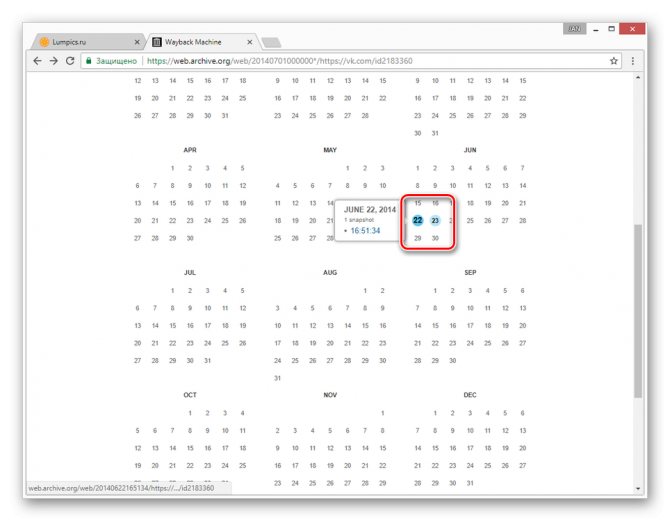
С помощью календаря найдите интересующую вас дату и наведите на нее курсор мыши. При этом кликабельными являются только подсвеченные определенным цветом числа.
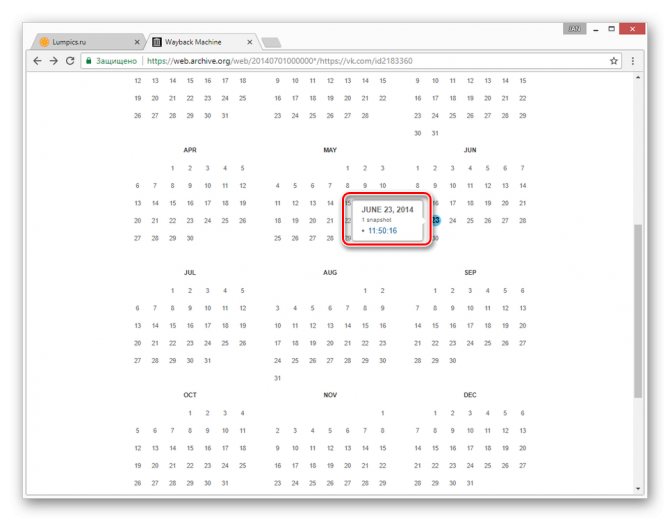
Теперь вам будет представлена страница пользователя, но лишь на английском языке.
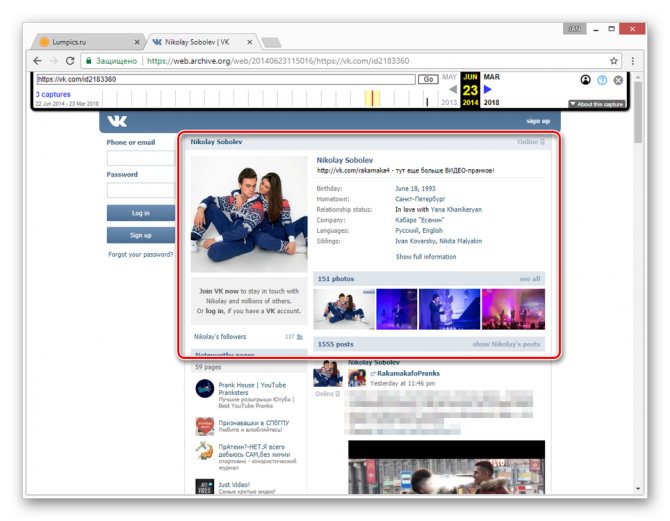
Вы можете просматривать только ту информацию, которая не была скрыта настройками приватности на момент ее архивирования. Любые кнопки и прочие возможности сайта будут недоступны.
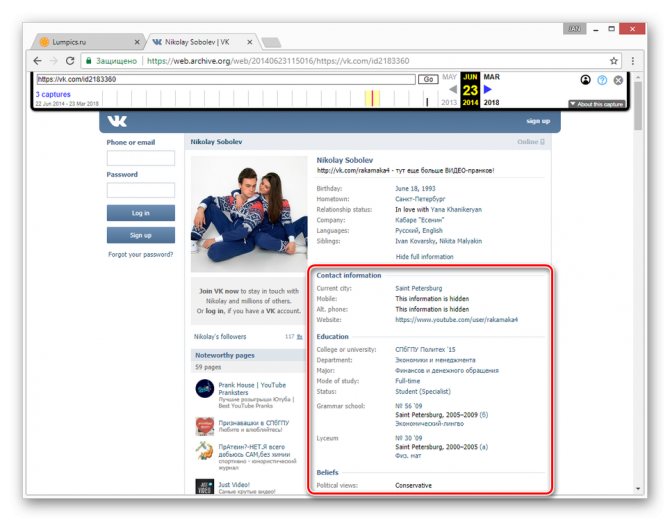
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
финансирование
Интернет-архив финансируется за счет пожертвований и грантов различных фондов, институтов и ассоциаций в области образования, исследований, науки и т. Д. В апреле 2019 года Интернет-архив указал следующих доноров: Фонд Эндрю У. Меллона , Совет по библиотеке и Информационные ресурсы , Фонд демократии Организации Объединенных Наций , Федеральная комиссия по связи универсального обслуживания программы для школ и библиотек (E-Rate) , институт музейных и библиотечных служб (IMLS) , Knight Foundation , Лаура и Джон Арнольд Фонд , Национальный гуманитарный фонд (Office цифровой гуманитарный) , Национальный научный фонд , Питер и Кармен Лусие Buck фонд , Филадельфия Фонд , Рита Аллен Фонд .
Разбираем на примере как правильно подойти к оценке первичной информации
Возьмем всем известный ресурс — cian.ru. Вводим домен в текстовое поле на нашей странице и получаем информацию представленную ниже на скриншоте. Выбираем 2010 год.

Количество HTML страниц = 630. Что это означает? Это значит, что за 2010 год веб-архив увидел 630 уникальные страницы. При этом, если главная страница менялась например 30 раз, то для нас будет уже 600 уникальных страниц. Тоесть по сути это может быть и 200 страниц, но они обновляемые и поэтому считаются как уникальные.
* При восстановлении сайта у нас, мы берем самую последнюю версию страницы, т.к. невозможно сохранить например 2 главные страницы и на них ссылаться. Поэтому сайт будет наиболее полным и ничего не потеряется. Все зависит от того сколько к себе сохранил на сервер веб-архив.
Бывают ситуации, когда в начале года был старый сайт, а в середине года изменился на новый: поменяли дизайн, структуру ссылок и т.д. В данном случае все страницы посчитаются как уникальные, и при восстановлении нужно указывать последнюю версию с тем дизайном, который вам нужен.
Так как реально оценить сколько уникальных (для пользователя) страниц не предоставляется возможным, то мы предоставляем то суммарное количество файлов больше которого точно сайт не будет. Да, это не совсем корректная оценка, но хотя бы приблизительно можно понять размеры ресурса.

492 039 HTML страниц — это сумма страниц за все годы.
Надеемся, что все вышеописанное не будет сложным для понимания и снимет множество вопросов. Если есть вопросы относящиеся к данной теме, но не описанные в статье — пишите нам на почту, с радостью ответим.
Как добавить современную версию сайта в веб-архив Wayback Machineи выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |

Как пользоваться веб-архивом?
В том, как пользоваться веб-архивом, нет ничего сложного. Для того, чтобы использовать его, достаточно перейти на соответствующий сайт archive.org и в поиске вести адрес нужного сайта. После непродолжительного времени, архив выдаст информацию об имеющихся сохранениях этого ресурса.

Например, с помощью этого можно найти информацию с сайта, который по каким-либо причинам перестал существовать. Так же веб архив поможет найти информацию со страниц, даже если она была удалена
Это особенно важно для поиска удачных примеров сторителлинга лет. Рассмотрим подробнее, как посмотреть архив.
Компании, архивирующие интернет
Архив Интернета
В 1996 году была основана некоммерческая организация «Internet Archive». Архив собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики. Размер архива на 2019 год — более 45 петабайт; еженедельно добавляется около 20 терабайт. На начало 2009 года он содержал 85 миллиардов веб-страниц., в мае 2014 года — 400 миллиардов. Сервер Архива расположен в Сан-Франциско, зеркала — в Новой Александрийской библиотеке и Амстердаме. С 2007 года Архив имеет юридический статус библиотеки. Основной веб-сервис архива — The Wayback Machine. Содержание веб-страниц фиксируется с временны́м промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует по старому адресу.
В июне 2015 года сайт был заблокирован на территории России по решению Генпрокуратуры РФ за архивы страниц, признанных содержащими экстремистскую информацию, позднее был исключён из реестра.
WebCite
«WebCite» — интернет-сервис, который выполняет архивирование веб-страниц по запросу. Впоследствии на заархивированную страницу можно сослаться через url. Пользователи имеют возможность получить архивную страницу в любой момент и без ограничений, и при этом неважен статус и состояние оригинальной веб-страницы, с которой была сделана архивная копия. В отличие от Архива Интернета, WebCite не использует веб-краулеров для автоматической архивации всех подряд веб-страниц. WebCite архивирует страницы только по прямому запросу пользователя. WebCite архивирует весь контент на странице — HTML, PDF, таблицы стилей, JavaScript и изображения. WebCite также архивирует метаданные о архивируемых ресурсах, такие как время доступа, MIME-тип и длину контента. Эти метаданные полезны для установления аутентичности и происхождения архивированных данных. Пилотный выпуск сервиса был выпущен в 1998 году, возрождён в 2003.
По состоянию на 2013 год проект испытывает финансовые трудности и проводит сбор средств, чтобы избежать вынужденного закрытия.
Peeep.us
Сервис peeep.us позволяет сохранить копию страницы по запросу пользования, в том числе и из авторизованной зоны, которая потом доступна по сокращённому URL. Реализован на Google App Engine.
Сервис peeep.us, в отличие от ряда других аналогичных сервисов, получает данные на клиентской стороне — то есть, не обращается напрямую к сайту, а сохраняет то содержимое сайта, которое видно пользователю. Это может использоваться для того, чтобы можно было поделиться с другими людьми содержимым закрытого для посторонних ресурса.
Таким образом, peeep.us не подтверждает, что по указанному адресу в указанный момент времени действительно было доступно заархивированное содержимое. Он подтверждает лишь то, что у инициировавшего архивацию по указанному адресу в указанный момент времени подгружалось заархивированное содержимое. Таким образом, Peeep.us нельзя использовать для доказательства того, что когда-то на сайте была какая-то информация, которую потом намеренно удалили (и вообще для каких-либо доказательств). Сервис может хранить данные «практически вечно», однако оставляет за собой право удалять контент, к которому никто не обращался в течение месяца.
Возможность загрузки произвольных файлов делает сервис привлекальным для хостинга вирусов, из-за чего peeep.us регулярно попадаёт в чёрные списки браузеров.
Archive.today
Сервис archive.today (ранее archive.is) позволяет сохранять основной HTML-текст веб-страницы, все изображения, стили, фреймы и используемые шрифты, в том числе страницы с Веб 2.0-сайтов, например с Твиттер.
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.

Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50

Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.