Floating-point numeric types (c# reference)
Содержание:
- Инициализация полей структуры
- Символы
- Размер основных типов данных в C++
- Математические операции в C++
- Указатели
- Арифметическое переполнение и деление на нуль
- Преобразование типов данных в C#
- Целочисленные литералы
- Типы данных в программировании
- Указание типов переменных и функций
- Общие понятия
- Допустимые имена для переменных
- Числовые типы данных
- Оператор остатка %
Инициализация полей структуры
Инициализация полей структуры может осуществляться двумя способами:
- присвоение значений элементам структуры в процессе объявления переменной, относящейся к типу структуры;
- присвоение начальных значений элементам структуры с использованием функций ввода-вывода (например, printf() и scanf()).
В первом способе инициализация осуществляется по следующей форме:
struct ИмяСтруктуры ИмяПеременной={ЗначениеЭлемента1, ЗначениеЭлемента_2, . . . , ЗначениеЭлементаn};
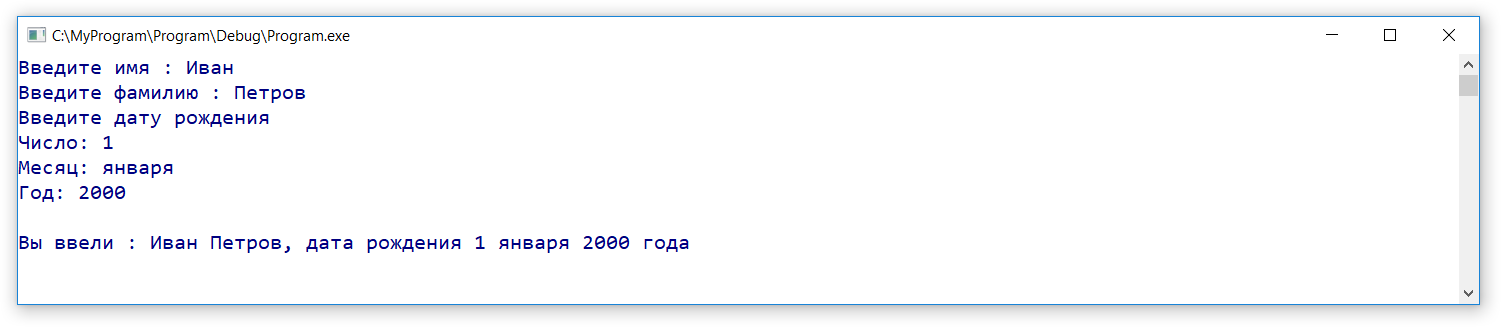
Пример
struct date bd={8,»июня», 1978};
ИмяПеременной.ИмяЭлементаСтруктуры
printf(«%d %s %d»,bd.day, bd.month, bd.year);
Пример
1234567891011121314151617181920212223242526272829303132
#define _CRT_SECURE_NO_WARNINGS#include <stdio.h>#include <stdlib.h>struct date { int day; char month; int year;};struct persone { char firstname; char lastname; struct date bd;};int main() { system(«chcp 1251»); system(«cls»); struct persone p; printf(«Введите имя : «); scanf(«%s», p.firstname); printf(«Введите фамилию : «); scanf(«%s», p.lastname); printf(«Введите дату рождения\nЧисло: «); scanf(«%d», &p.bd.day); printf(«Месяц: «); scanf(«%s», p.bd.month); printf(«Год: «); scanf(«%d», &p.bd.year); printf(«\nВы ввели : %s %s, дата рождения %d %s %d года», p.firstname, p.lastname, p.bd.day, p.bd.month, p.bd.year); getchar(); getchar(); return 0;}
Имя структурной переменной может быть указано при объявлении структуры. В этом случае оно размещается после закрывающей фигурной скобки }. Область видимости такой структурной переменной будет определяться местом описания структуры.
struct complex_type // имя структуры{ double real; double imag;} number; // имя структурной переменной
Поля приведенной структурной переменной: number.real, number.imag .
Символы
В C# символы представлены не 8-разрядным кодом, как во многих других языках
программирования, например , а 16-разрядным кодом, который называется юникодом (Unicode). В юникоде набор символов представлен настолько широко, что он охватывает символы практически из всех естественных языков на свете. Если для многих
естественных языков, в том числе английского, французского и немецкого, характерны
относительно небольшие алфавиты, то в ряде других языков, например китайском,
употребляются довольно обширные наборы символов, которые нельзя представить
8-разрядным кодом. Для преодоления этого ограничения в C# определен тип char,
представляющий 16-разрядные значения без знака в пределах от 0 до 65 535. При этом
стандартный набор символов в 8-разрядном коде ASCII является подмножеством юникода в пределах от 0 до 127. Следовательно, символы в коде ASCII по-прежнему остаются действительными в C#.
Для того чтобы присвоить значение символьной переменной, достаточно заключить это значение (т.е. символ) в одинарные кавычки:
Несмотря на то что тип char определен в C# как целочисленный, его не следует
путать со всеми остальными целочисленными типами. Дело в том, что в C# отсутствует автоматическое преобразование символьных значений в целочисленные и обратно.
Например, следующий фрагмент кода содержит ошибку:
Наравне с представлением char как символьных литералов, их можно представлять
как 4-разрядные шестнадцатеричные значения Unicode (например, ‘\u0041’), целочисленные значения с приведением (например, (char) 65) или же шестнадцатеричные значения (например, ‘\x0041’). Кроме того, они могут быть представлены в виде .
Размер основных типов данных в C++
Возникает вопрос: «Сколько памяти занимают переменные разных типов данных?». Вы можете удивиться, но размер переменной с любым типом данных зависит от компилятора и/или архитектуры компьютера!
Язык C++ гарантирует только их минимальный размер:
| Категория | Тип | Минимальный размер |
| Логический тип данных | bool | 1 байт |
| Символьный тип данных | char | 1 байт |
| wchar_t | 1 байт | |
| char16_t | 2 байта | |
| char32_t | 4 байта | |
| Целочисленный тип данных | short | 2 байта |
| int | 2 байта | |
| long | 4 байта | |
| long long | 8 байт | |
| Тип данных с плавающей запятой | float | 4 байта |
| double | 8 байт | |
| long double | 8 байт |
Фактический размер переменных может отличаться на разных компьютерах, поэтому для его определения используют оператор sizeof.
Оператор sizeof — это унарный оператор, который вычисляет и возвращает размер определенной переменной или определенного типа данных в байтах. Вы можете скомпилировать и запустить следующую программу, чтобы выяснить, сколько занимают разные типы данных на вашем компьютере:
#include <iostream>
int main()
{
std::cout << «bool:\t\t» << sizeof(bool) << » bytes» << std::endl;
std::cout << «char:\t\t» << sizeof(char) << » bytes» << std::endl;
std::cout << «wchar_t:\t» << sizeof(wchar_t) << » bytes» << std::endl;
std::cout << «char16_t:\t» << sizeof(char16_t) << » bytes» << std::endl;
std::cout << «char32_t:\t» << sizeof(char32_t) << » bytes» << std::endl;
std::cout << «short:\t\t» << sizeof(short) << » bytes» << std::endl;
std::cout << «int:\t\t» << sizeof(int) << » bytes» << std::endl;
std::cout << «long:\t\t» << sizeof(long) << » bytes» << std::endl;
std::cout << «long long:\t» << sizeof(long long) << » bytes» << std::endl;
std::cout << «float:\t\t» << sizeof(float) << » bytes» << std::endl;
std::cout << «double:\t\t» << sizeof(double) << » bytes» << std::endl;
std::cout << «long double:\t» << sizeof(long double) << » bytes» << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { std::cout<<«bool:\t\t»<<sizeof(bool)<<» bytes»<<std::endl; std::cout<<«char:\t\t»<<sizeof(char)<<» bytes»<<std::endl; std::cout<<«wchar_t:\t»<<sizeof(wchar_t)<<» bytes»<<std::endl; std::cout<<«char16_t:\t»<<sizeof(char16_t)<<» bytes»<<std::endl; std::cout<<«char32_t:\t»<<sizeof(char32_t)<<» bytes»<<std::endl; std::cout<<«short:\t\t»<<sizeof(short)<<» bytes»<<std::endl; std::cout<<«int:\t\t»<<sizeof(int)<<» bytes»<<std::endl; std::cout<<«long:\t\t»<<sizeof(long)<<» bytes»<<std::endl; std::cout<<«long long:\t»<<sizeof(longlong)<<» bytes»<<std::endl; std::cout<<«float:\t\t»<<sizeof(float)<<» bytes»<<std::endl; std::cout<<«double:\t\t»<<sizeof(double)<<» bytes»<<std::endl; std::cout<<«long double:\t»<<sizeof(longdouble)<<» bytes»<<std::endl; return; } |
Вот результат, полученный на моем компьютере:
Ваши результаты могут отличаться, если у вас другая архитектура, или другой компилятор
Обратите внимание, оператор sizeof не используется с типом void, так как последний не имеет размера
Если вам интересно, что значит в коде, приведенном выше, то это специальный символ, который используется вместо клавиши TAB. Мы его использовали для выравнивания столбцов. Детально об этом мы еще поговорим на соответствующих уроках.
Интересно то, что sizeof — это один из 3-х операторов в языке C++, который является словом, а не символом (еще есть new и delete).
Вы также можете использовать оператор sizeof и с переменными:
#include <iostream>
int main()
{
int x;
std::cout << «x is » << sizeof(x) << » bytes» << std::endl;
}
|
1 |
#include <iostream> intmain() { intx; std::cout<<«x is «<<sizeof(x)<<» bytes»<<std::endl; } |
Результат выполнения программы:
На следующих уроках мы рассмотрим каждый из фундаментальных типов данных языка С++ по отдельности.
Математические операции в C++
В С++ есть пять базовых математических операций:
- Сложение (+).
- Вычитание (-).
- Умножение (*).
- Деление (/).
- Остаток от деления (%).
Используются они следующим образом:
Важно! Сначала выполняется правая часть выражения после знака =, а потом левая. То есть переменной не будет присвоено значения, пока не выполнены все вычисления
Поэтому можно записать в переменную результат вычислений, в которых использовалась эта же переменная:
Если вам нужно провести какую-то операцию с переменной, а потом записать значение в неё же, используйте следующие операторы:
Во время работы с С++ вы будете часто прибавлять или отнимать единицу от какой-нибудь переменной. Для этого тоже есть сокращённая запись:
Инкремент и декремент могут быть префиксными (++x) и постфиксными (x++). Префиксный инкремент сначала прибавляет к переменной единицу, а потом использует эту переменную, а постфиксный — наоборот.
Указатели
Для любого типа T существует тип «указатель на T».
Переменные могут быть объявлены как указатели на значения различных типов с помощью символа . Для того чтобы определить тип переменной как указатель, нужно предварить её имя звёздочкой.
char letterC = 'C';
char *letter = &letterC; //взятие адреса переменной letterC и присваивание в переменную letter
printf("This code is written in %c.", *letter); //"This code is written in C."
Поскольку указатель — тоже тип переменной, правило «для любого типа T» выполняется и для них: можно объявлять указатели на указатели. К примеру, можно пользоваться :
int w = 100;
int *x = &w;
int **y = &x;
int ***z = &y;
printf("w contains %d.", ***z); //"w contains 100."
Существуют также указатели на массивы и на функции. Указатели на массивы имеют следующий синтаксис:
char *pc10; // массив из 10 указателей на char char (*pa)10; // указатель на массив из 10 переменных типа char
— массив указателей, занимающий байт (на распространённых платформах — обычно 40 или 80 байт), а — это один указатель; занимает он обычно 4 или 8 байт, однако позволяет обращаться к массиву, занимающему 10 байт: , но .
Указатели на массивы отличаются от указателей на первый элемент арифметикой. Например, если указатели указывает на адрес 2000, то указатель будет указывать на адрес 2010.
char (*pa)10;
char array10 = "Wikipedia";
pa = &array;
printf("An example for %s.\n", *pa); //"An example for Wikipedia."
printf("%c %c %c", (*pa)1, (*pa)3, (*pa)7); //"i i i"
Арифметическое переполнение и деление на нуль
Если результат арифметической операции выходит за пределы диапазона возможных конечных значений соответствующего числового типа, поведение арифметического оператора зависит от типа его операндов.
Целочисленное арифметическое переполнение
Деление целого числа на ноль всегда вызывает исключение DivideByZeroException.
В случае целочисленного арифметического переполнения итоговое поведение определяется контекстом проверки переполнения, который может быть проверяемым или непроверяемым:
- Если в проверяемом контексте переполнение возникает в константном выражении, происходит ошибка времени компиляции. В противном случае, если операция производится во время выполнения, возникает исключение OverflowException.
- В непроверяемом контексте результат усекается путем удаления старших разрядов, которые не помещаются в целевой тип данных.
Вместе с проверяемыми и непроверяемыми операторами вы можете использовать операторы и , чтобы управлять контекстом проверки переполнения, в котором вычисляется выражение:
По умолчанию арифметические операции выполняются в непроверяемом контексте.
Арифметическое переполнение с плавающей запятой
Арифметические операции с типами и никогда не вызывают исключение. Результатом арифметических операций с этими типами может быть одно из специальных значений, представляющих бесконечность и объект, не являющийся числовым:
Для операндов типа арифметическое переполнение всегда вызывает исключение OverflowException, а деление на нуль всегда вызывает исключение DivideByZeroException.
Преобразование типов данных в C#
Преобразование типов данных, это приведение одного типа к другому. Например, приведение целочисленной переменной к числу с плавающей точной, или преобразование числа в строку. В C# выделяют два варианта преобразования типов:
- Неявное преобразование типов. Это, так называемое безопасное преобразование типов в C#. Например, преобразование из типа float (более «маленький» тип) в тип double (более «большой» тип). При таком преобразовании никакая информация не «потеряется», что при обратном преобразовании вполне возможно.
- Явное преобразование типов. Такое преобразование выполняется программистом с прямым указанием типа, к которому нужно привести переменную. Для такого преобразования требуется наличие оператора преобразования.
А теперь, я покажу как можно использовать явное преобразование типов в C#:
using System;
namespace TypesConvertion
{
class Program
{
static void Main(string[] args)
{
//Число с плавающей точкой
double doubleData = 245.45;
//Вывод этого числа
Console.WriteLine(doubleData);
//А теперь, мы сделаем на основе этого числа, цело число
int intData = (int)doubleData;
//Вывод целого числа
Console.WriteLine(intData);
//Чтобы окно не закрылось раньше времени
Console.ReadKey();
}
}
}
Преобразование типа double в тип int выполнялось в выделенной строке (строке с номером 16). Если вы соберете данный пример и запустите его, то увидите, что преобразование типов прошло, т.е. из числа с плавающей точкой мы получили целое число.
Так же, для преобразования данных из одного типа в другой, есть целый класс с именем Convert, у которого имеются специальные методы. Ниже, в таблице, представлены основные методы этого класса.
| Название метода | Целевой тип |
|---|---|
| ToBoolean | bool |
| ToByte | byte |
| ToChar | char |
| ToDouble | double |
| ToSingle | float |
| ToInt32 | int |
| ToInt64 | long |
| ToString | string |
А теперь, пример использования класса Convert и его методов:
using System;
namespace TypesConvertion
{
class Program
{
static void Main(string[] args)
{
//Число с плавающей точкой
double doubleData = 245.45;
//Вывод этого числа
Console.WriteLine(doubleData);
//А теперь, мы сделаем на основе этого числа, цело число
int intData = Convert.ToInt32(doubleData);
//Вывод целого числа
Console.WriteLine(intData);
//Чтобы окно не закрылось раньше времени
Console.ReadKey();
}
}
}
Как видите, это практически тот же код, что был в первом примере, но с использованием другого подхода в преобразовании типов.
Пользоваться возможность преобразования типов вам придется довольно часто!
Целочисленные литералы
Целочисленные литералы могут быть:
- десятичным числом: без префикса;
- шестнадцатеричным числом: с префиксом или ;
- двоичными: с префиксом или (доступно в C# 7.0 и более поздних версиях).
В приведенном ниже коде показан пример каждого из них.
В предыдущем примере также показано использование в качестве цифрового разделителя, который поддерживается, начиная с версии C# 7.0. Цифровой разделитель можно использовать со всеми видами числовых литералов.
Тип целочисленного литерала определяется его суффиксом следующим образом:
-
Если литерал не имеет суффикса, его типом будет первый из следующих типов, в котором может быть представлено его значение: , , , .
Примечание
Литералы интерпретируется как положительные значения. Например, литерал представляет число типа , хотя он имеет то же битовое представление, что и число типа . Если вам требуется значение определенного типа, приведите литерал к этому типу. Используйте оператор , если представить значение литерала в целевом типе невозможно. Например, выдает .
-
Если у литерала есть суффикс или , его типом будет первый из следующих типов, в котором может быть представлено его значение: , .
-
Если у литерала есть суффикс или , его типом будет первый из следующих типов, в котором может быть представлено его значение: , .
Примечание
Строчную букву можно использовать в качестве суффикса. Однако при этом выдается предупреждение компилятора, так как букву можно перепутать с цифрой . Для ясности используйте .
-
Если у литерала есть суффикс , , , , , , или , его тип — .
Если значение, представленное целочисленным литералом, превышает UInt64.MaxValue, происходит ошибка компиляции CS1021.
Если определенный тип целочисленного литерала — , а значение, представленное литералом, находится в диапазоне целевого типа, значение можно неявно преобразовать в , , , , , , или :
Как показано в предыдущем примере, если значение литерала выходит за пределы диапазона целевого типа, возникает ошибка компилятора CS0031.
Можно также использовать приведение для преобразования значения, представленного целочисленным литералом, в тип, отличный от определенного типа литерала:
Типы данных в программировании
Чаще всего используются следующие типы данных:
- int — целое число;
- byte — число от 0 до 255;
- float — число с плавающей запятой;
- double — число с плавающей запятой повышенной точности;
- char — символ;
- bool — логический тип, который может содержать в себе значения true (истина) и false (ложь).
Эти типы данных называются примитивными (значимыми), потому что они базово встроены в язык.
Также существуют ссылочные типы — такие переменные хранят в себе не само значение, а ссылку на него в оперативной памяти. К ссылочным типам относятся массивы, объекты, строки (так называют любой текст) и многое другое. Для строк используется тип std: string.
Вот несколько примеров переменных разных типов:
Указание типов переменных и функций
C++ — это строго типизированный язык, который также является статически типизированным; Каждый объект имеет тип, и этот тип никогда не изменяется (не следует путать с статическими объектами данных). При объявлении переменной в коде необходимо либо явно указать ее тип, либо использовать ключевое слово, чтобы указать компилятору вывести тип из инициализатора. При объявлении функции в коде необходимо указать тип каждого аргумента и его возвращаемое значение или значение, если функция не возвращает никакого значения. Исключением является использование шаблонов функции, которые допускают аргументы произвольных типов.
После объявления переменной изменить ее тип впоследствии уже невозможно. Однако можно скопировать значения переменной или возвращаемое значение функции в другую переменную другого типа. Такие операции называются преобразованиями типов, которые иногда являются обязательными, но также являются потенциальными источниками потери или неправильности данных.
При объявлении переменной типа POD настоятельно рекомендуется инициализировать ее, т. е. указать начальное значение. Пока переменная не инициализирована, она имеет «мусорное» значение, определяемое значениями битов, которые ранее были установлены в этом месте памяти. Необходимо учитывать эту особенность языка C++, особенно при переходе с другого языка, который обрабатывает инициализацию автоматически. При объявлении переменной типа, не являющегося классом POD, инициализация обрабатывается конструктором.
В следующем примере показано несколько простых объявлений переменных с небольшим описанием для каждого объявления. В примере также показано, как компилятор использует сведения о типе, чтобы разрешить или запретить некоторые последующие операции с переменной.
Общие понятия
Типом данных в программировании называют совокупность двух множеств: множество значений и множество операций, которые можно применять к ним. Например, к типу данных целых неотрицательных чисел, состоящего из конечного множества натуральных чисел, можно применить операции сложения (+), умножения (*), целочисленного деления (/), нахождения остатка (%) и вычитания (−).
Язык программирования, как правило, имеет набор примитивных типов данных — типы, предоставляемые языком программирования как базовая встроенная единица. В C++ такие типы создатель языка называет фундаментальными типами. Фундаментальными типами в C++ считаются:
- логический ();
- символьный (напр., );
- целый (напр., );
- с плавающей точкой (напр., );
- перечисления (определяется программистом);
- .
Поверх перечисленных строятся следующие типы:
- указательные (напр., );
- массивы (напр., );
- ссылочные (напр., );
- другие структуры.
Перейдём к понятию литерала (напр., 1, 2.4F, 25e-4, ‘a’ и др.): литерал — запись в исходном коде программы, представляющаясобой фиксированное значение. Другими словами, литерал — это просто отображение объекта (значение) какого-либо типа в коде программы. В C++ есть возможность записи целочисленных значений, значений с плавающей точкой, символьных, булевых, строковых.
Литерал целого типа можно записать в:
- 10-й системе счисления. Например, ;
- 8-й системе счисления в формате 0 + число. Например, ;
- 16-й системе счисления в формате 0x + число. Например, .
24, 030, 0x18 — это всё записи одного и того же числа в разных системах счисления.
Для записи чисел с плавающей точкой используют запись через точку: 0.1, .5, 4. — либо в
экспоненциальной записи — 25e-100. Пробелов в такой записи быть не должно.
Имя, с которым мы можем связать записанные литералами значения, называют переменной. Переменная — это поименованная либо адресуемая иным способом область памяти, адрес которой можно использовать для доступа к данным. Эти данные записываются, переписываются и стираются в памяти определённым образом во время выполнения программы. Переменная позволяет в любой момент времени получить доступ к данным и при необходимости изменить их. Данные, которые можно получить по имени переменной, называют значением переменной.
Для того, чтобы использовать в программе переменную, её обязательно нужно объявить, а при необходимости можно определить (= инициализировать). Объявление переменной в тексте программы обязательно содержит 2 части: базовый тип и декларатор. Спецификатор и инициализатор являются необязательными частями:
const int example = 3; // здесь const — спецификатор // int — базовый тип // example — имя переменной // = 3 — инициализатор.
Имя переменной является последовательностью символов из букв латинского алфавита (строчных и прописных), цифр и/или знака подчёркивания, однако первый символ цифрой быть не может. Имя переменной следует выбирать таким, чтобы всегда было легко догадаться о том, что она хранит, например, «monthPayment». В конспекте и на практиках мы будем использовать для правил записи переменных нотацию CamelCase. Имя переменной не может совпадать с зарезервированными в языке словами, примеры таких слов: if, while, function, goto, switch и др.
Декларатор кроме имени переменной может содержать дополнительные символы:
- — указатель; перед именем;
- — константный указатель; перед именем;
- — ссылка; перед именем;
- — массив; после имени;
- — функция; после имени.
Инициализатор позволяет определить для переменной её значение сразу после объявления. Инициализатор начинается с литерала равенства (=) и далее происходит процесс задания значения переменной. Вообще говоря, знак равенства в C++ обозначает операцию присваивания; с её помощью можно задавать и изменять значение переменной. Для разных типов он может быть разным.
Спецификатор задаёт дополнительные атрибуты, отличные от типа. Приведённый в примере спецификатор const позволяет запретить последующее изменение значение переменной. Такие неизменяемые переменные называют константными или константой.
Объявить константу без инициализации не получится по логичным причинам:
const int EMPTY_CONST; // ошибка, не инициализована константная переменная const int EXAMPLE = 2; // константа со значением 2 EXAMPLE = 3; // ошибка, попытка присвоить значение константной переменной
Для именования констант принято использовать только прописные буквы, разделяя слова символом нижнего подчёркивания.
Допустимые имена для переменных
Идентификаторы переменных могут содержать в себе:
- латинские буквы;
- цифры;
- знак нижнего подчёркивания.
При этом название не может начинаться с цифр. Примеры названий:
- age;
- name;
- _sum;
- first_name;
- a1;
- a2;
- a_5.
Все идентификаторы регистрозависимы. Это значит, что name и Name — разные переменные.
Рекомендуется давать именам простые названия на английском языке, чтобы код был понятен и вам, и другим людям. Например:
- price, а не stoimost;
- currentId, а не pupa;
- carsCount, а не lupa и так далее.
Если название должно состоять из нескольких слов, то рекомендуется использовать camelCase (с англ. «верблюжий регистр»): первое слово пишется со строчной буквы, а каждое последующее — с заглавной.
Числовые типы данных
| Тип данных | Объем памяти | Диапазон | Описание |
| TINYINT (M) | 1 байт | от -128 до 127 или от 0 до 255 | Целое число. Может быть объявлено положительным с помощью ключевого слова UNSIGNED, тогда элементам столбца нельзя будет присвоить отрицательное значение. Необязательный параметр М — количество отводимых под число символов. Необязательный атрибут ZEROFILL позволяет свободные позиции по умолчанию заполнить нулями.Примеры: TINYINT — хранит любое число в диапазоне от -128 до 127. TINYINT UNSIGNED — хранит любое число в диапазоне от 0 до 255. TINYINT (2) — предполагается, что значения будут двузначными, но по факту будет хранить и трехзначные. TINYINT (3) ZEROFILL — свободные позиции слева заполнит нулями. Например, величина 2 будет отображаться, как 002. |
| SMALLINT (M) | 2 байта | от -32768 до 32767 или от 0 до 65535 | Аналогично предыдущему, но с большим диапазоном.Примеры: SMALLINT — хранит любое число в диапазоне от -32768 до 32767. SMALLINT UNSIGNED — хранит любое число в диапазоне от 0 до 65535. SMALLINT (4) — предполагается, что значения будут четырехзначные, но по факту будет хранить и пятизначные. SMALLINT (4) ZEROFILL — свободные позиции слева заполнит нулями. Например, величина 2 будет отображаться, как 0002. |
| MEDIUMINT (M) | 3 байта | от -8388608 до 8388608 или от 0 до 16777215 | Аналогично предыдущему, но с большим диапазоном.Примеры: MEDIUMINT — хранит любое число в диапазоне от -8388608 до 8388608. MEDIUMINT UNSIGNED — хранит любое число в диапазоне от 0 до 16777215. MEDIUMINT (4) — предполагается, что значения будут четырехзначные, но по факту будет хранить и семизначные. MEDIUMINT (5) ZEROFILL — свободные позиции слева заполнит нулями. Например, величина 2 будет отображаться, как 00002. |
| INT (M) или INTEGER (M) | 4 байта | от -2147683648 до 2147683648 или от 0 до 4294967295 | Аналогично предыдущему, но с большим диапазоном.Примеры: INT — хранит любое число в диапазоне от -2147683648 до 2147683648. INT UNSIGNED — хранит любое число в диапазоне от 0 до 4294967295. INT (4) — предполагается, что значения будут четырехзначные, но по факту будет хранить максимально возможные. INT (5) ZEROFILL — свободные позиции слева заполнит нулями. Например, величина 2 будет отображаться, как 00002. |
| BIGINT (M) | 8 байта | от -263 до 263-1 или от 0 до 264 | Аналогично предыдущему, но с большим диапазоном.Примеры: BIGINT — хранит любое число в диапазоне от -263 до 263-1. BIGINT UNSIGNED — хранит любое число в диапазоне от 0 до 264. BIGINT (4) — предполагается, что значения будут четырехзначные, но по факту будет хранить максимально возможные. BIGINT (7) ZEROFILL — свободные позиции слева заполнит нулями. Например, величина 2 будет отображаться, как 0000002. |
| BOOL или BOOLEAN | 1 байт | либо 0, либо 1 | Булево значение. 0 — ложь (false), 1 — истина (true). |
| DECIMAL (M,D) или DEC (M,D) или NUMERIC (M,D) | M + 2 байта | зависят от параметров M и D | Используются для величин повышенной точности, например, для денежных данных. M — количество отводимых под число символов (максимальное значение — 64). D — количество знаков после запятой (максимальное значение — 30).Пример: DECIMAL (5,2) — будет хранить числа от -99,99 до 99,99. |
| FLOAT (M,D) | 4 байта | мин. значение +(-) 1.175494351 * 10-39 макс. значение +(-) 3. 402823466 * 1038 |
Вещественное число (с плавающей точкой). Может иметь параметр UNSIGNED, запрещающий отрицательные числа, но диапазон значений от этого не изменится. M — количество отводимых под число символов. D — количество символов дробной части. Пример: FLOAT (5,2) — будет хранить числа из 5 символов, 2 из которых будут идти после запятой (например: 46,58). |
| DOUBLE (M,D) | 8 байт | мин. значение +(-) 2.2250738585072015 * 10-308 макс. значение +(-) 1.797693134862315 * 10308 |
Аналогично предыдущему, но с большим диапазоном. Пример: DOUBLE — будет хранить большие дробные числа. |
Оператор остатка %
Оператор остатка вычисляет остаток от деления левого операнда на правый.
Целочисленный остаток
Для целочисленных операндов результатом является значение, произведенное . Знак ненулевого остатка такой же, как и у левого операнда, как показано в следующем примере:
Используйте метод Math.DivRem для вычисления результатов как целочисленного деления, так и определения остатка.
Остаток с плавающей запятой
Для операндов типа и результатом для конечных и будет значение , так что:
- знак , если отлично от нуля, совпадает со знаком ;
- абсолютное значение является значением, произведенным , где — это наибольшее возможное целое число, которое меньше или равно , а и являются абсолютными значениями и , соответственно.
Примечание
Этот метод вычисления остатка аналогичен тому, который использовался для целочисленных операндов, но отличается от спецификации IEEE 754. Если вам нужна операция вычисления остатка, которая соответствует спецификации IEEE 754, используйте метод Math.IEEERemainder.
Сведения о поведение оператора в случае неконечных операндов см. в разделе спецификации языка C#.
Для операндов оператор остатка эквивалентен типа System.Decimal.
В следующем примере показано поведение оператора остатка для операндов с плавающей запятой: