Строковый тип данных в python: string
Содержание:
- Преобразование в кортежи и списки
- Разница между атомарными и структурными типы данных
- Присвоение значений переменным
- Как создать строку
- Форматирование строк в Python
- Десятичные дроби в Python
- Вводная информация о строках
- Форматирование строк
- Целочисленный тип данных integer
- Основные строковые функции
- Что такое строка в Python?
- Вывод
Преобразование в кортежи и списки
Вы можете использовать методы и для преобразования переданных им значений в тип данных списка и кортежа соответственно. В Python:
- список является изменяемой упорядоченной последовательностью элементов, заключенных в квадратные скобки .
- кортеж является неизменяемой упорядоченной последовательностью элементов, заключенных в круглые скобки .
Преобразование в кортежи
Начнем с преобразования списка в кортеж. Поскольку кортеж — это неизменяемый тип данных, такое преобразование может способствовать существенной оптимизации наших программ. Метод возвращает «кортежную» версию переданного ему значения.
print(tuple())
Мы видим, что в результате выводится кортеж, поскольку элементы теперь заключены в круглые, а не в квадратные скобки.
Давайте используем с переменной, представляющей список:
sea_creatures = print(tuple(sea_creatures))
Опять же, мы видим, что значения списка преобразуются в значения кортежа, что обозначается круглыми скобками.
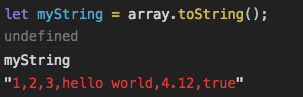
Мы можем преобразовать в кортеж не только список, но и любой итерируемый тип, включая строки:
print(tuple('Sammy'))
Строки можно преобразовывать в кортежи с помощью метода , потому что они итерируемые (их можно перебирать). Но с типами данных, которые не являются итерируемыми (пример — целые числа и числа с плавающей запятой), мы получим ошибку:
print(tuple(5000))
Можно преобразовать целое число в строку, а затем в кортеж: . Но лучше выбрать читаемый код, а не сложные преобразования.
Преобразование в списки
Преобразование значений, особенно кортежей, в списки может быть полезно, когда вам нужно иметь изменяемую версию этого значения. Для преобразования в список используется метод .
Давайте преобразуем кортеж в список. Будьте внимательны со скобками: одна пара для кортежа, вторая — для метода , а третья — для метода :
print(list(('blue coral', 'staghorn coral', 'pillar coral')))
Квадратные скобки сигнализируют о том, что кортеж, переданный в метод , преобразован в список.
Чтобы сделать код более читабельным, мы можем ввести переменную и удалить одну из пар круглых скобок:
coral = ('blue coral', 'staghorn coral', 'pillar coral')
list(coral)
Если мы выведем , мы получим тот же результат, что и выше.
В список можно преобразовать не только кортеж, но и строку:
print(list('shark'))
Разница между атомарными и структурными типы данных
По одной из классификаций все типы данных в Python делятся на атомарные и ссылочные.
Атомарные:
- числа;
- строки;
Ссылочные:
- списки;
- кортежи;
- словари;
- функции;
- классы;
Разница между этими двумя группами уходит глубоко в корни языка. Вкратце:
Из результатов видно, что переменной было присвоено именно значение, содержащееся в atom, а не ссылка, указывающая на область памяти.
Посмотрим, как это работает для структурных типов:
Поскольку списки – это ссылочные объекты, то вполне закономерно, что после присваивания переменной переменной передалась именно ссылка на объект list-а и, при печати, на экран были выведены две одинаковые надписи.
Собственно, в этом и вся разница.
Присвоение значений переменным
Переменные Python не требуют явного объявления для резервирования пространства памяти. Объявление присваивается автоматически, когда вы присваиваете значение переменной. Знак равенства (=) используется для присвоения значений переменным.
Операнд слева от оператора = является именем переменной, а операнд справа от оператора = является значением, которое хранится в переменной. Например,
#!/usr/bin/python3 counter = 100 # Целочисленная переменная miles = 1000.0 # Переменная с плафающей точкой name = "John" # Строковая переменная print (counter) print (miles) print (name)
Здесь 100, 1000.0 и «John» являются значениями, присвоенными счетчику, милям и переменной имени, соответственно. Это дает следующий результат:
100 1000.0 John
Как создать строку
Строки всегда создаются одним из трех способов. Вы можете использовать одинарные, двойные и тройные скобки. Давайте посмотрим
Python
my_string = «Добро пожаловать в Python!»
another_string = ‘Я новый текст тут…’
a_long_string = »’А это у нас
новая строка
в троичных скобках»’
|
1 2 3 4 5 6 |
my_string=»Добро пожаловать в Python!» another_string=’Я новый текст тут…’ a_long_string=»’А это у нас новая строка |
Строка с тремя скобками может быть создана с использованием трех одинарных скобок или трех двойных скобок. Так или иначе, с их помощью программист может писать строки в нескольких линиях. Если вы впишете это, вы увидите, что выдача сохраняет разрыв строк. Если вам нужно использовать одинарные скобки в вашей строке, то впишите двойные скобки. Давайте посмотрим на пример:
Python
my_string = «I’m a Python programmer!»
otherString = ‘Слово «Python» обычно подразумевает змею’
tripleString = «»»В такой «строке» мы можем ‘использовать’ все.»»»
|
1 2 3 |
my_string=»I’m a Python programmer!» otherString=’Слово «Python» обычно подразумевает змею’ tripleString=»»»В такой «строке» мы можем ‘использовать’ все.»»» |
Данный код демонстрирует то, как вы можете вписать одинарные или двойные скобки в строку. Существует еще один способ создания строки, при помощи метода str. Как это работает:
Python
my_number = 123
my_string = str(my_number)
|
1 2 |
my_number=123 my_string=str(my_number) |
Если вы впишете данный код в ваш интерпретатор, вы увидите, что вы изменили значение интегратора на строку и присвоили ее переменной my_string. Это называется кастинг, или конвертирование. Вы можете конвертировать некоторые типы данных в другие, например числа в строки. Но вы также заметите, что вы не всегда можете делать обратное, например, конвертировать строку вроде ‘ABC’ в целое число. Если вы сделаете это, то получите ошибку вроде той, что указана в этом примере:
Python
int(‘ABC’)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
ValueError: invalid literal for int() with base 10: ‘ABC’
|
1 2 3 4 5 |
int(‘ABC’) Traceback(most recent call last) File»<string>»,line1,in<fragment> ValueErrorinvalid literal forint()withbase10’ABC’ |
Мы рассмотрели обработку исключений в другой статье, но как вы могли догадаться из сообщения, это значит, что вы не можете конвертировать сроки в цифры. Тем не менее, если вы вписали:
Python
x = int(«123»)
| 1 | x=int(«123») |
То все должно работать
Обратите внимание на то, что строка – это один из неизменных типов Python. Это значит, что вы не можете менять содержимое строки после ее создания
Давайте попробуем сделать это и посмотрим, что получится:
Python
my_string = «abc»
my_string = «d»
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: ‘str’ object does not support item assignment
|
1 2 3 4 5 6 |
my_string=»abc» my_string=»d» Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeError’str’objectdoes notsupport item assignment |
Здесь мы пытаемся изменить первую букву с «а» на «d«, в итоге это привело к ошибке TypeError, которая не дает нам сделать это. Теперь вы можете подумать, что присвоение новой строке то же значение и есть изменение строки. Давайте взглянем, правда ли это:
Python
my_string = «abc»
a = id(my_string)
print(a) # 19397208
my_string = «def»
b = id(my_string)
print(b) # 25558288
my_string = my_string + «ghi»
c = id(my_string)
print(c) # 31345312
|
1 2 3 4 5 6 7 8 9 10 11 |
my_string=»abc» a=id(my_string) print(a)# 19397208 my_string=»def» b=id(my_string) print(b)# 25558288 my_string=my_string+»ghi» c=id(my_string) print(c)# 31345312 |
Проверив id объекта, мы можем определить, что когда мы присваиваем новое значение переменной, то это меняет тождество
Обратите внимание, что в версии Python, начиная с 2.0, строки могут содержать только символы ASCII. Если вам нужен Unicode, тогда вы должны вписывать u перед вашей строкой
Пример:
Python
# -*- coding: utf-8 -*-
my_unicode_string = u»Это юникод!»
|
1 2 |
# -*- coding: utf-8 -*- my_unicode_string=u»Это юникод!» |
В Python, начиная с версии 3, все строки являются юникодом.
Форматирование строк в Python
Экранирование символов
Если внутри строки содержатся символы одинарной и двойной кавычки, то вне зависимости от того, какие кавычки мы использовали для создания строки — мы получим ошибку SyntaxError.
>>> print("She said, "What's there?"")
...
SyntaxError: invalid syntax
>>> print('She said, "What's there?"')
...
SyntaxError: invalid syntax
Один из способов обойти эту проблему — использовать тройные кавычки. В качестве альтернативы мы можем использовать escape-последовательности или так называемое «экранирование символов».
Экранирующая последовательность начинается с обратной косой черты. Если мы используем одинарную кавычку для представления строки, все одинарные кавычки внутри строки должны быть экранированы. Аналогично обстоит дело с двойными кавычками. Вот как это можно сделать для представления приведенного выше текста.
# Тройные кавычки
print('''He said, "What's there?"''')
# Экранирование одинарных кавычек
print('He said, "What\'s there?"')
# Экранирование двойных кавычек
print("He said, \"What's there?\"")
Использование метода format() для форматирования строк
Метод format(), доступный для строкового объекта, очень универсален и мощен в форматировании строк. Формат строки содержит фигурные скобки {} в качестве заполнителей или заменяющих полей, которые заменяются соответствующими значениями.
Мы можем использовать позиционные аргументы или ключевые аргументы, чтобы указать порядок.
# порядок по умолчанию
default_order = "{}, {} and {}".format('John','Bill','Sean')
print(default_order)
# порядок задается вручную
positional_order = "{1}, {0} and {2}".format('John','Bill','Sean')
print(positional_order)
# порядок задается аргументами
keyword_order = "{s}, {b} and {j}".format(j='John',b='Bill',s='Sean')
print(keyword_order)
Метод format() может иметь необязательные спецификации формата. Они отделены от имени поля двоеточием. Например, мы можем выравнивать по левому краю <, выравнивать по правому краю > или центрировать ^ строку в заданном пространстве. Мы также можем отформатировать целые числа как двоичные, шестнадцатеричные и т.д., а числа с плавающей точкой могут быть округлены или отображены в формате экспоненты. Существует множество форматов, которые вы можете использовать. Более подробно про метод format() можно почитать в официальной документации к языку.
>>> # форматирование целых чисел
>>> "Binary representation of {0} is {0:b}".format(12)
'Binary representation of 12 is 1100'
>>> # форматирование чисел с плавающей запятой
>>> "Exponent representation: {0:e}".format(1566.345)
'Exponent representation: 1.566345e+03'
>>> # округление
>>> "One third is: {0:.3f}".format(1/3)
'One third is: 0.333'
>>> # выравнивание строки
>>> "|{:<10}|{:^10}|{:>10}|".format('butter','bread','ham')
'|butter | bread | ham|’
Десятичные дроби в Python
Встроенный в Python класс float выполняет некоторые вычисления, которые могут нас удивить. Мы все знаем, что сумма 1.1 и 2.2 равна 3.3, но Python, похоже, не согласен.
>>> (1.1 + 2.2) == 3.3 False
Оказывается, что числа с плавающей запятой реализованы в Python как двоичные дроби, поскольку компьютер понимает только двоичную систему счисления (0 и 1). По этой причине большинство известных нам десятичных дробей не может быть точно сохранено на нашем компьютере.
Давайте рассмотрим пример. Мы не можем представить дробь 1/3 как десятичное число. Это даст 0.33333333.
Получается, что десятичная дробь 0,1 приведет к бесконечно длинной двоичной дроби 0,000110011001100110011 … и наш компьютер хранит только ее конечное число.
Это будет только приблизительно 0,1, но никогда не будет равным 0,1. Следовательно, это ограничение нашего компьютерного оборудования, а не ошибка в Python.
>>> 1.1 + 2.2 3.3000000000000003
Чтобы преодолеть эту проблему, мы можем использовать десятичный модуль decimal, который поставляется с Python. В то время как числа с плавающей запятой имеют точность до 15 десятичных знаков, десятичный модуль имеет заданную пользователем точность.
import decimal
# Результат: 0.1
print(0.1)
# Результат: Decimal('0.1000000000000000055511151231257827021181583404541015625')
print(decimal.Decimal(0.1))
Этот модуль используется, когда мы хотим выполнить десятичные вычисления с высокой точностью.
Вводная информация о строках
Как и во многих других языках программирования, в Python есть большая коллекция функций, операторов и методов, позволяющих работать со строковым типом.
Литералы строк
Литерал – способ создания объектов, в случае строк Питон предлагает несколько основных вариантов:
Если внутри строки необходимо расположить двойные кавычки, и сама строка была создана с помощью двойных кавычек, можно сделать следующее:
Разницы между строками с одинарными и двойными кавычками нет – это одно и то же
Какие кавычки использовать – решать вам, соглашение PEP 8 не дает рекомендаций по использованию кавычек. Просто выберите один тип кавычек и придерживайтесь его. Однако если в стоке используются те же кавычки, что и в литерале строки, используйте разные типы кавычек – обратная косая черта в строке ухудшает читаемость кода.
Кодировка строк
В третьей версии языка программирования Python все строки представляют собой последовательность Unicode-символов.
В Python 3 кодировка по умолчанию исходного кода – UTF-8. Во второй версии по умолчанию использовалась ASCII. Если необходимо использовать другую кодировку, можно разместить специальное объявление на первой строке файла, к примеру:
Максимальная длина строки в Python
Максимальная длина строки зависит от платформы. Обычно это:
- 2**31 — 1 – для 32-битной платформы;
- 2**63 — 1 – для 64-битной платформы;
Константа , определенная в модуле
Конкатенация строк
Одна из самых распространенных операций со строками – их объединение (конкатенация). Для этого используется знак , в результате к концу первой строки будет дописана вторая:
При необходимости объединения строки с числом его предварительно нужно привести тоже к строке, используя функцию
Сравнение строк
При сравнении нескольких строк рассматриваются отдельные символы и их регистр:
- цифра условно меньше, чем любая буква из алфавита;
- алфавитная буква в верхнем регистре меньше, чем буква в нижнем регистре;
- чем раньше буква в алфавите, тем она меньше;
При этом сравниваются по очереди первые символы, затем – 2-е и так далее.
Далеко не всегда желательной является зависимость от регистра, в таком случае можно привести обе строки к одному и тому же регистру. Для этого используются функции – для приведения к нижнему и – к верхнему:
Как удалить строку в Python
Строки, как и некоторые другие типы данных в языке Python, являются неизменяемыми объектами. При задании нового значения строке просто создается новая, с заданным значением. Для удаления строки можно воспользоваться методом , заменив ее на пустую строку:
Или перезаписать переменную пустой строкой:
Обращение по индексу
Для выбора определенного символа из строки можно воспользоваться обращением по индексу, записав его в квадратных скобках:
Индекс начинается с 0
В Python предусмотрена возможность получить доступ и по отрицательному индексу. В таком случае отсчет будет вестись от конца строки:
Форматирование строк
Форматирование строк (также известно как замещение) – это замещение значений в базовой строке. Большую часть времени вы будете вставлять строки внутри строк, однако, вам также понадобиться вставлять целые числа и числа с запятыми в строки весьма часто. Существует два способа достичь этой цели. Начнем с старого способа, после чего перейдем к новому:
Python
# -*- coding: utf-8 -*-
my_string = «Я люблю %s» % «Python»
print(my_string) # Я люблю Python
var = «яблоки»
newString = «Я ем %s» % var
print(newString) # Я ем яблоки
another_string = «Я люблю %s и %s» % («Python», var)
print(another_string) # Я люблю Python и яблоки
|
1 2 3 4 5 6 7 8 9 10 11 |
# -*- coding: utf-8 -*- my_string=»Я люблю %s»%»Python» print(my_string)# Я люблю Python var=»яблоки» newString=»Я ем %s»%var print(newString)# Я ем яблоки another_string=»Я люблю %s и %s»%(«Python»,var) print(another_string)# Я люблю Python и яблоки |
Как вы могли догадаться, % — это очень важная часть вышеописанного кода. Этот символ указывает Python, что вы скоро вставите текст на его место. Если вы будете следовать за строкой со знаком процента и другой строкой или переменной, тогда Python попытается вставить ее в строку. Вы можете вставить несколько строк, добавив несколько знаков процента в свою строку. Это видно в последнем примере
Обратите внимание на то, что когда вы добавляете больше одной строки, вам нужно закрыть эти строки в круглые скобки. Теперь взглянем на то, что случится, если мы вставим недостаточное количество строк:
Python
another_string = «Я люблю %s и %s» % «Python»
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: not enough arguments for format string
|
1 2 3 4 5 |
another_string=»Я люблю %s и %s»%»Python» Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeErrornotenough arguments forformatstring |
О-па. Мы не передали необходимое количество аргументов для форматирования строки. Если вы внимательно взгляните на пример, вы увидите, что у нас есть два экземпляра %, но для того, чтобы вставить строки, вам нужно передать столько же %, сколько у нас строк. Теперь вы готовы к тому, чтобы узнать больше о вставке целых чисел, и чисел с запятыми. Давайте взглянем.
Python
my_string = «%i + %i = %i» % (1,2,3)
print(my_string) # ‘1 + 2 = 3’
float_string = «%f» % (1.23)
print(float_string) # ‘1.230000’
float_string2 = «%.2f» % (1.23)
print(float_string2) # ‘1.23’
float_string3 = «%.2f» % (1.237)
print(float_string3) # ‘1.24’
|
1 2 3 4 5 6 7 8 9 10 11 |
my_string=»%i + %i = %i»%(1,2,3) print(my_string)# ‘1 + 2 = 3’ float_string=»%f»%(1.23) print(float_string)# ‘1.230000’ float_string2=»%.2f»%(1.23) print(float_string2)# ‘1.23’ float_string3=»%.2f»%(1.237) print(float_string3)# ‘1.24’ |
Первый пример достаточно простой. Мы создали строку, которая принимает три аргумента, и мы передаем их. В случае, если вы еще не поняли, Python не делает никаких дополнений в первом примере. Во втором примере, мы передаем число с запятой
Обратите внимание на то, что результат включает множество дополнительных нулей (1.230000). Нам это не нужно, так что мы указываем Python ограничить выдачу до двух десятичных значений в третьем примере (“%.2f”)
Последний пример показывает, что Python округлит числа для вас, если вы передадите ему дробь, что лучше, чем два десятичных значения. Давайте взглянем на то, что произойдет, если мы передадим неправильные данные:
Python
int_float_err = «%i + %f» % («1», «2.00»)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: %d format: a number is required, not str
|
1 2 3 4 |
int_float_err=»%i + %f»%(«1″,»2.00») Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeError%dformatanumber isrequired,notstr |
В данном примере мы передали две строки вместо целого числа и дроби. Это привело к ошибке TypeError, что говорит нам о том, что Python ждал от нас чисел. Это указывает на отсутствие передачи целого числа, так что мы исправим это, по крайней мере, попытаемся:
Python
int_float_err = «%i + %f» % (1, «2.00»)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: float argument required, not str
|
1 2 3 4 5 |
int_float_err=»%i + %f»%(1,»2.00″) Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeErrorfloatargument required,notstr |
Мы получили ту же ошибку, но под другим предлогом, в котором написано, что мы должны передать дробь. Как мы видим, Python предоставляет нам полезную информацию о том, что же пошло не так и как это исправить. Если вы исправите вложения надлежащим образом, тогда вы сможете запустить этот пример. Давайте перейдем к новому методу форматирования строк.
Целочисленный тип данных integer
Мы можем использовать тип данных для определения объектов, значение которых может быть целым числом. Например, следующие строки определяют сигнал типа и присваивают ему целое число 4.
Как показано на рисунке 2, тип данных относится к категории «стандартных типов», которая определена в пакете “” из библиотеки “”. Как обсуждалось в предыдущей статье, нам не нужно явно делать пакет “” и библиотеку “” видимыми для проекта.
Следующий код показывает простой пример, когда два входа типа , и , складываются вместе, и результат присваивается .
На рисунке 3 показан результат ISE симуляции приведенного выше кода. На этом рисунке показан десятичный эквивалент значений ввода/вывода. Например, от 200 нс до 300 нс, входы и равны 3 и -1 соответственно. Таким образом, выход, , равен 3 + (-1) = 2.
Рисунок 3 – Результаты симуляции
При использовании целочисленного типа данных мы не принимаем непосредственного участия в определениях на уровне битов, однако ясно, что реализация для представления определенных сигналов будет использовать несколько бит. Сколько бит будет использоваться для представления целочисленных сигналов в приведенном выше коде? VHDL не указывает точное количество бит, но любая реализация VHDL должна поддерживать как минимум 32-разрядрую реализацию типа . Согласно стандарту, эта 32-разрядная реализация позволяет присваивать объекту типа целое число в диапазоне от -(231-1) до +(231-1).
Иногда мы имеем дело с ограниченными значениями, и для представления небольшого значения неэффективно использовать 32-разрядный сигнал. Например, предположим, что вход принимает значение от до 45. Таким образом, мы можем использовать 6-разрядный сигнал вместо 32-разрядного представления, потому что 4510=1011012. Более того, предположим, что другой вход, , имеет значение в диапазоне от -45 до 45, поэтому должно использоваться знаковое () представление. Учитывая бит знака, нам нужно всего семь битов вместо 32 битов по умолчанию, потому что представление двух -45 равно 1010011. Чтобы добиться значительного сокращения использования ресурсов FPGA, мы можем просто указать диапазон значений сигналов, как в следующем коде:
Данный код предполагает, что входы и находятся в диапазонах от 0 до 45 и от -45 до 45 соответственно. Поскольку равен , диапазон будет от -45 до 90. Ограничение диапазона целых чисел уменьшает объем ресурсов FPGA, необходимых для реализации проекта. Более того, это дает возможность проверить на ошибки на ранних этапах проектирования. Например, предположим, что представляет собой угол, и из системных спецификаций мы знаем, что значение этого угла ограничено диапазоном от -45 до 90.
Как указано в приведенном выше коде, мы можем применить этот диапазон к определению объекта . Теперь, если мы допустим ошибку, которая заставляет значение находиться за пределами указанного диапазона, программное обеспечение симулятора выдаст ошибку и идентифицирует строку кода, которая включает недопустимое присваивание. Например, если мы укажем диапазон как от -45 до 89, а затем присвоим значение 45 и , и , ISIim симулятор прекратит моделирование со следующей ошибкой (ISim – это название симулятора, который включен в программное обеспечение ISE):
(В моем коде моделирования строка 17 содержит присваивание .) Обратите внимание, что симулятор ISIM по умолчанию не отлавливает эти ошибки, связанные с диапазоном; вы должны включить опцию «value range check» (проверка диапазона значений). Если данная опция не включена, симуляция не остановится, и целому числу, объявленному с ограниченным диапазоном, сможет быть присвоено любое значение
Обратите внимание, что указание меньшего диапазона не всегда означает, что мы можем представить сигнал меньшим количеством бит. Например, рассмотрите следующие объявления:. Первые для объявления требуют трехразрядного представления, хотя второе объявление имеет меньший диапазон
Аналогичным образом, третье и четвертое объявления должны иметь четыре бита
Первые для объявления требуют трехразрядного представления, хотя второе объявление имеет меньший диапазон. Аналогичным образом, третье и четвертое объявления должны иметь четыре бита.
Основные строковые функции
| capitalize() | Преобразует первый символ строки в верхний регистр | str_name.capitalize() |
| casefold() | Он преобразует любую строку в нижний регистр независимо от ее регистра | str_name.casefold() |
| center() | Используется для выравнивания строки по центру | str_name.center (длина, символ) |
| count() | Для подсчета количества раз, когда определенное значение появляется в строке. | str_name.count (значение, начало, конец) |
| endswith() | Проверяет, заканчивается ли строка указанным значением, затем возвращает True | str_name.endswith (значение, начало, конец) |
| find() | Используется для определения наличия указанного значения в строке | str_name.find (значение, начало, конец) |
| index() | Он используется для поиска первого вхождения указанного значения в строке | str_name.index (значение, начало, конец) |
| isalnum() | Проверяет, все ли символы являются буквенно-цифровыми, затем возвращает True | str_name.isalnum() |
| isalpha() | Проверяет, все ли символы являются алфавитными (az), затем возвращает True | str_name.isalpha() |
| isdecimal() | Проверяет, все ли символы являются десятичными (0-9), затем возвращает True | str_name.isdecimal() |
| isdigit() | Проверяет, все ли символы являются цифрами, затем возвращает True | str_name.isdigit() |
| islower() | Проверяет, все ли символы в нижнем регистре, затем возвращает True | str_name.islower() |
| isnumeric() | Проверяет, все ли символы являются числовыми (0-9), затем возвращает True | str_name.isnumeric() |
| isspace() | Проверяет, все ли символы являются пробелами, затем возвращает True | str_name.isspace() |
| isupper() | Проверяет, все ли символы в верхнем регистре, затем возвращает True | str_name.isupper() |
| lower() | Используется для преобразования всех символов в нижний регистр | str_name.lower() |
| partition() | Используется для разделения строки на кортеж из трех элементов. | str_name.partition (значение) |
| replace() | Используется для замены указанного слова или фразы другим словом или фразой в строке. | str_name.replace (старое значение, новое значение, количество) |
| split() | Используется для разделения строки на список | str_name.split (разделитель, maxsplit) |
| splitlines() | Используется для разделения строки и составления ее списка. Разбивается на разрыв строки. | str_name.splitlines (keeplinebreaks) |
| startswith() | Проверяет, начинается ли строка с указанного значения, затем возвращает True | str_name.startswith (значение, начало, конец) |
| strip() | Используется для удаления символов, указанных в аргументе, с обоих концов | str_name.strip (символы) |
| swapcase() | Используется для замены строки верхнего регистра на нижний регистр или наоборот. | str_name.swapcase() |
| title() | Преобразует начальную букву каждого слова в верхний регистр | str_name.title() |
| upper() | Он используется для преобразования всех символов в строке в верхний регистр | str_name.upper() |
Что такое строка в Python?
Строка в Python — это обычная последовательность символов (букв, цифр, знаков препинания).
Компьютеры не имеют дело с символами, они имеют дело с числами (в двоичной системе). Даже если вы видите символы на вашем экране, внутри памяти компьютера он хранится и обрабатываются как последовательность нулей и единиц.
Преобразование символа в число называется кодированием, а обратный процесс — декодированием. ASCII и Unicode — наиболее популярные из кодировок, которые используются для кодирования и декодирования данных.
В Python, строка — это последовательность символов Unicode. Юникод был введен для включения каждого символа на всех языках и обеспечения единообразия в кодировании.
Вывод
На этом этапе вы должны лучше понять некоторые основные типы данных Python, которые доступны для использования в Python. Каждый из этих типов данных станет важным по мере разработки проектов программирования на языке Python.
Как только у вас будет четкое представление о типах данных, доступных вам в Python, вы сможете научиться преобразовывать эти типы данных Python.
Этот учебник охватывал различные типы данных Python и пытался объяснить каждый из них на примерах. Здесь вы можете найти всю необходимую информацию, которая может быть полезна вам при разработке программ на Python.
Если у вас есть какие-либо сомнения, сообщите нам об этом в разделе комментариев ниже.
Счастливого кодирования!