Int, bigint, smallint, and tinyint (transact-sql)
Содержание:
Целочисленные типы фиксированной ширины
Стандарт C99 включает определения нескольких новых целочисленных типов для повышения переносимости программ. Уже доступных базовых целочисленных типов было сочтено недостаточным, поскольку их фактические размеры определяются реализацией и могут различаться в разных системах. Новые типы особенно полезны во встроенных средах, где оборудование обычно поддерживает только несколько типов, и эта поддержка варьируется в зависимости от среды. Все новые типы определены в заголовке ( заголовок в C ++), а также доступны в заголовке ( заголовок в C ++). Типы можно сгруппировать в следующие категории:
- Целочисленные типы точной ширины, которые гарантированно имеют одинаковое количество бит n во всех реализациях. Включается только в том случае, если это доступно в реализации.
- Целочисленные типы с наименьшей шириной, которые, как гарантируется, будут наименьшим типом, доступным в реализации, который имеет как минимум указанное количество n битов. Гарантированно указывается не менее N = 8,16,32,64.
- Самые быстрые целочисленные типы, которые гарантированно являются самыми быстрыми целочисленными типами, доступными в реализации, которые имеют как минимум заданное количество n битов. Гарантированно указывается не менее N = 8,16,32,64.
- Целочисленные типы указателей, которые гарантированно могут содержать указатель. Включается только в том случае, если это доступно в реализации.
- Целочисленные типы максимальной ширины, которые гарантированно будут наибольшим целочисленным типом в реализации.
В следующей таблице приведены типы и интерфейс для получения сведений о реализации ( n означает количество битов):
| Типовая категория | Подписанные типы | Беззнаковые типы | |||
|---|---|---|---|---|---|
| Тип | Минимальное значение | Максимальное значение | Тип | Минимальное значение | Максимальное значение |
| Точная ширина | |||||
| Наименьшая ширина | |||||
| Самый быстрый | |||||
| Указатель | |||||
| Максимальная ширина |
Спецификаторы формата printf и scanf
Заголовка ( в C ++) обеспечивает функции , которые повышают функциональность типов , определенных в заголовке. Он определяет макросы для Printf форматной строки и формата зсапЕ строки спецификаторов , соответствующих типов , определенных в и несколько функций для работы с и типами. Этот заголовок был добавлен в C99 .
- Строка формата printf
Макросы в формате . Здесь {fmt} определяет форматирование вывода и может быть одним из (десятичного), (шестнадцатеричного), (восьмеричного), (беззнакового) и (целого). {тип} определяет тип аргумента и является одним из , , , , , где соответствует числу битов в аргументе.
- Строка формата scanf
Макросы в формате . Здесь {fmt} определяет форматирование вывода и может быть одним из (десятичного), (шестнадцатеричного), (восьмеричного), (беззнакового) и (целого). {тип} определяет тип аргумента и является одним из , , , , , где соответствует числу битов в аргументе.
- Функции
Биты целочисленных значений
Для того чтобы понять, почему при выходе из диапазона целые числа сбрасываются, рассмотрим биты. Специальный символ покажет биты целочисленного значения. Как и другие специальные символы может задействовать нулевой отступ с минимальной длиной, что показано в следующем примере:
Листинг 3
Go
var green uint8 = 3
fmt.Printf(«%08b\n», green) // Выводит: 00000011
green++
fmt.Printf(«%08b\n», green) // Выводит: 00000100
|
1 |
vargreen uint8=3 fmt.Printf(«%08b\n»,green)// Выводит: 00000011 green++ fmt.Printf(«%08b\n»,green)// Выводит: 00000100 |
Задание для проверки:
Используйте Go Playground, чтобы поэкспериментировать с целочисленным переполнением:
- Листинг 2 (один из примеров урока) увеличивает значения и на 1. Что произойдет при добавлении более крупного числа к каждой переменной?
- Рассмотрите иной вариант развития событий. Что случится при уменьшении значения , когда то равно 0 или уменьшения , когда то равно -128?
- Целочисленное переполнение также касается 16, 32 и 64-битных целых чисел. Что произойдет при объявлении , присвоенного к максимальному значению 65535, а затем уменьшенному на 1?
Пакет определяет как 65535 и min/max константы для каждого независимого от архитектуры целочисленного типа. Помните, что int и uint могут быть как 32, так и 64-битными, зависит от компьютера.
В примере выше (Листинг 3) увеличение приводит к перемещению 1, что оставляет нули справа. Результат является бинарным, что равняется 4 в десятичной системе. Это показано на схеме ниже.
Перемещение 1 в бинарном дополнении
То же самое происходит при увеличении 255. Однако есть одна кардинальная разница: оставшейся только с восемью доступными битами переместившейся 1 некуда больше деваться, поэтому значение остается как 0. Это показано в следующей схеме:
Куда перемещаться дальше?
Листинг 4
Go
var blue uint8 = 255
fmt.Printf(«%08b\n», blue) // Выводит: 11111111
blue++
fmt.Printf(«%08b\n», blue) // Выводит: 00000000
|
1 |
varblue uint8=255 fmt.Printf(«%08b\n»,blue)// Выводит: 11111111 blue++ fmt.Printf(«%08b\n»,blue)// Выводит: 00000000 |
В некоторых ситуациях целочисленное переполнение может прийтись кстати, но не всегда. Самым простым способом избежать его является использование целочисленного типа с достаточно большим диапазоном, что способен вместить все задействованные значения.
Вопрос для проверки:
Какой специальный символ нужно использовать, чтобы увидеть биты?
Целочисленный тип данных integer
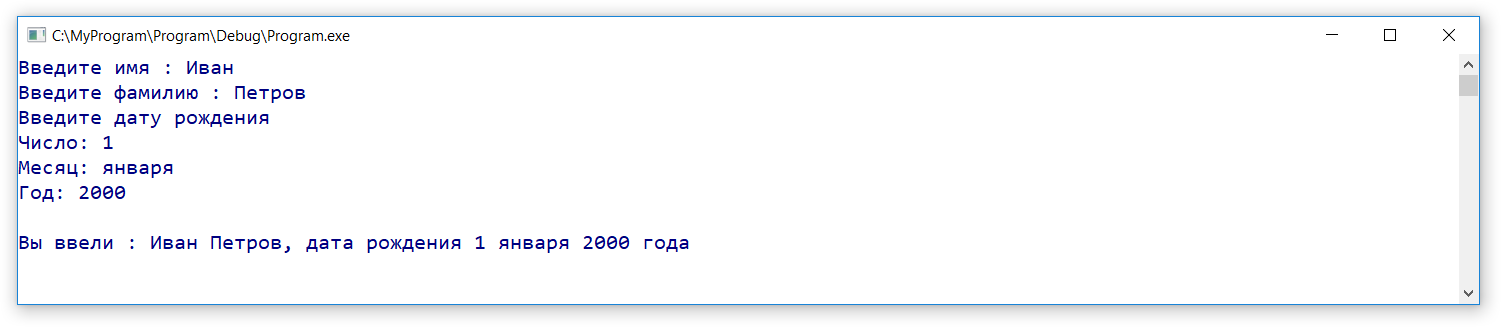
Мы можем использовать тип данных для определения объектов, значение которых может быть целым числом. Например, следующие строки определяют сигнал типа и присваивают ему целое число 4.
Как показано на рисунке 2, тип данных относится к категории «стандартных типов», которая определена в пакете “” из библиотеки “”. Как обсуждалось в предыдущей статье, нам не нужно явно делать пакет “” и библиотеку “” видимыми для проекта.
Следующий код показывает простой пример, когда два входа типа , и , складываются вместе, и результат присваивается .
На рисунке 3 показан результат ISE симуляции приведенного выше кода. На этом рисунке показан десятичный эквивалент значений ввода/вывода. Например, от 200 нс до 300 нс, входы и равны 3 и -1 соответственно. Таким образом, выход, , равен 3 + (-1) = 2.
Рисунок 3 – Результаты симуляции
При использовании целочисленного типа данных мы не принимаем непосредственного участия в определениях на уровне битов, однако ясно, что реализация для представления определенных сигналов будет использовать несколько бит. Сколько бит будет использоваться для представления целочисленных сигналов в приведенном выше коде? VHDL не указывает точное количество бит, но любая реализация VHDL должна поддерживать как минимум 32-разрядрую реализацию типа . Согласно стандарту, эта 32-разрядная реализация позволяет присваивать объекту типа целое число в диапазоне от -(231-1) до +(231-1).
Иногда мы имеем дело с ограниченными значениями, и для представления небольшого значения неэффективно использовать 32-разрядный сигнал. Например, предположим, что вход принимает значение от до 45. Таким образом, мы можем использовать 6-разрядный сигнал вместо 32-разрядного представления, потому что 4510=1011012. Более того, предположим, что другой вход, , имеет значение в диапазоне от -45 до 45, поэтому должно использоваться знаковое () представление. Учитывая бит знака, нам нужно всего семь битов вместо 32 битов по умолчанию, потому что представление двух -45 равно 1010011. Чтобы добиться значительного сокращения использования ресурсов FPGA, мы можем просто указать диапазон значений сигналов, как в следующем коде:
Данный код предполагает, что входы и находятся в диапазонах от 0 до 45 и от -45 до 45 соответственно. Поскольку равен , диапазон будет от -45 до 90. Ограничение диапазона целых чисел уменьшает объем ресурсов FPGA, необходимых для реализации проекта. Более того, это дает возможность проверить на ошибки на ранних этапах проектирования. Например, предположим, что представляет собой угол, и из системных спецификаций мы знаем, что значение этого угла ограничено диапазоном от -45 до 90.
Как указано в приведенном выше коде, мы можем применить этот диапазон к определению объекта . Теперь, если мы допустим ошибку, которая заставляет значение находиться за пределами указанного диапазона, программное обеспечение симулятора выдаст ошибку и идентифицирует строку кода, которая включает недопустимое присваивание. Например, если мы укажем диапазон как от -45 до 89, а затем присвоим значение 45 и , и , ISIim симулятор прекратит моделирование со следующей ошибкой (ISim – это название симулятора, который включен в программное обеспечение ISE):
(В моем коде моделирования строка 17 содержит присваивание .) Обратите внимание, что симулятор ISIM по умолчанию не отлавливает эти ошибки, связанные с диапазоном; вы должны включить опцию «value range check» (проверка диапазона значений). Если данная опция не включена, симуляция не остановится, и целому числу, объявленному с ограниченным диапазоном, сможет быть присвоено любое значение
Обратите внимание, что указание меньшего диапазона не всегда означает, что мы можем представить сигнал меньшим количеством бит. Например, рассмотрите следующие объявления:. Первые для объявления требуют трехразрядного представления, хотя второе объявление имеет меньший диапазон
Аналогичным образом, третье и четвертое объявления должны иметь четыре бита
Первые для объявления требуют трехразрядного представления, хотя второе объявление имеет меньший диапазон. Аналогичным образом, третье и четвертое объявления должны иметь четыре бита.
Тип char
Среди примитивных типов в Java есть еще один, который заслуживает особого внимания — тип . Его название происходит от слова Character, а сам тип используется для того, чтобы хранить символы.
А ведь символы — это как раз то, из чего состоят строки: каждая строка содержит в себе массив символов.
Но еще интереснее тот факт, что тип — это и числовой тип тоже! Так сказать, тип двойного назначения.
Все дело в том, что на самом деле тип хранит не символы, а коды символов из кодировки Unicode. Каждому символу соответствует число — числовой код символа.
Каждая переменная типа занимает в памяти два байта (как и тип ). Но в отличие от типа , целочисленный тип — беззнаковый, и может хранить значения от до .
Тип — гибридный тип. Его значения можно интерпретировать и как числа (их можно складывать и умножать), и как символы. Так было сделано потому, что хоть символы и имеют визуальное представление, для компьютера они в первую очередь просто числа. И работать с ними как с числами гораздо удобнее.
Unicode
Unicode — это специальная таблица (кодировка), которая содержит все символы мира. И у каждого символа есть свой номер. Выглядит она примерно так:

Присвоить значение переменной типа можно разными способами.
| Код | Описание |
|---|---|
| Переменная будет содержать латинскую букву . | |
| Переменная будет содержать латинскую букву . Ее код как раз . | |
| Переменная будет содержать латинскую букву . Ее код как раз , что равно в шестнадцатеричной системе. |
|
| Переменная будет содержать латинскую букву . Ее код как раз , что равно в шестнадцатеричной системе. Два лишних нуля ничего не меняют. |
|
| Переменная будет содержать латинскую букву . Еще один способ задать символ по его коду. |
Чаще всего просто указывают символ в кавычках (как в первой строке таблицы). Хотя популярен и последний способ. Его преимущество в том, что его можно использовать в строках.
И как мы говорили, тип — это и целочисленный тип тоже, поэтому можно написать так:
| Код | Вывод на экран |
|---|---|
| На экран будет выведена латинская буква . Потому что: – – – |
Работа с типом
Каждый символ — это в первую очередь число (код символа), а потом уже символ. Зная код символа, всегда можно получить его в программе. Пример:
| Код | Вывод на экран |
|---|---|
Стандартные коды
Вот самые известные коды символов:
| Символы | Коды |
|---|---|
| , , , … | , , , … |
| , , , … | , , , … |
| , , , … | , , , … |
Programming tips
-
Interop Considerations. If you are interfacing with components not written for the .NET Framework, such as Automation or COM objects, remember that has a different data width (16 bits) in other environments. If you are passing a 16-bit argument to such a component, declare it as instead of in your new Visual Basic code.
-
Widening. The data type widens to , , , or . This means you can convert to any one of these types without encountering a System.OverflowException error.
-
Type Characters. Appending the literal type character to a literal forces it to the data type. Appending the identifier type character to any identifier forces it to .
-
Framework Type. The corresponding type in the .NET Framework is the System.Int32 structure.
Квалификаторы типа
Вышеупомянутые типы могут быть дополнительно охарактеризованы квалификаторами типа , что дает квалифицированный тип . По состоянию на 2014 год и C11 в стандарте C есть четыре квалификатора типа: ( C89 ), ( C89 ), ( C99 ) и ( C11 ) — последний имеет частное имя, чтобы избежать конфликтов с именами пользователей, но более обычное имя может использоваться, если заголовок включен. Из них, безусловно, самый известный и наиболее используемый, он появляется в стандартной библиотеке и встречается при любом значительном использовании языка C, который должен удовлетворять константной корректности . Другие квалификаторы используются для низкоуровневого программирования и, хотя и широко используются там, редко используются типичными программистами.
Целые типы
В языке Java аж 4 целых типа: , , и . Они отличаются размером и диапазоном значений, которые могут хранить.
Тип
Самым часто используемым является тип . Его название происходит от Integer (целый). Все целочисленные литералы в коде имеют тип (если в конце числа не указана буква , или ).
Переменные этого типа могут принимать значение от до .
Это достаточно много и хватает почти для всех случаев жизни. Почти все функции, которые возвращают число, возвращают число типа .
Примеры:
| Код | Пояснение |
|---|---|
| Метод возвращает длину строки | |
| Поле содержит длину массива. |
Тип
Тип получил свое название от . Его еще называют короткое целое. В отличие от типа , его длина всего два байта и возможный диапазон значений от до .
То есть в нем даже число миллион не сохранишь. Даже 50 тысяч. Это самый редко используемый целочисленный тип в Java. В основном его используют, когда хотят сэкономить на памяти.
Допустим, у вас ситуация, когда заранее известно, что значения с которыми вы работаете не превышает 30 тысяч, и таких значений миллионы.
Например, вы пишете приложение, которое обрабатывает картинки сверхвысокой четкости: на один цвет приходится бит. А точек у вас в картинке — миллион. И вот тут уже играет роль, используете вы тип или .
Тип
Этот тип получил свое название от — его еще называют длинное целое. В отличие от типа , у него просто гигантский диапазон значений: от до
Почему же он не является основным целым типом?
Все дело в том, что Java появилась еще в середине 90-х, когда большинство компьютеров были 32-х разрядными. А это значило, что все процессоры были заточены под работу с числами из 32-х бит. С целыми числами из 64-х бит процессоры работать уже умели, но операции с ними были медленнее.
Поэтому программисты разумно решили сделать стандартным целым типом тип , ну а тип использовать только тогда, когда без него действительно не обойтись.
Тип
Это самый маленький целочисленный тип в Java, но далеко не самый редко используемый. Его название совпадает со словом — минимальная адресуемая ячейка памяти в Java.
Размер допустимых значений типа не так уж велик: от до . Но не в этом его сила. Тип чаще всего используется, когда нужно хранить в памяти большой блок обезличенных данных. Массив типа просто идеально подходит для этих целей.
Например, вам нужно куда-то скопировать файл.
Вам не нужно обрабатывать содержимое файла: вы просто хотите создать область памяти (буфер), скопировать в нее содержимое файла, а затем записать эти данные из буфера в другой файл. Массив типа — то, что нужно для этих целей.
Тем более, что в переменной-типа-массив хранится только ссылка на область памяти. При передаче значения этой переменной в какой-то метод произойдет только передача адреса в памяти, а сам блок памяти копироваться на будет.
Решение
объявляет указатель на стек, который указывает на указатель (и) в куче. Каждый из этих указателей указывает на целое число или массив целых чисел в куче.
Это:
означает, что вы объявили указатель на стек и инициализировали его так, чтобы он указывал на массив из 100 указателей в куче. Пока что каждый из этих 100 указателей никуда не указывает. Под «нигде» я подразумеваю, что они не указывают ни на действительный кусок памяти, ни на s. Они не инициализируются, поэтому они содержат некоторое значение мусора, которое было в памяти до размещения указателей. Вы должны назначить им что-то разумное в цикле перед использованием
Обратите внимание, что — указатели не гарантированно указывают на смежные области памяти, если вы присваиваете возвращаемые значения им. Например, если вы выделите память для каждого из них как , не будет ссылаться , но приведет к неопределенному поведению
И это:
указатель на стек, который указывает на массив из 100 целых чисел в куче
6
Размер основных типов данных в C++
Возникает вопрос: «Сколько памяти занимают переменные разных типов данных?». Вы можете удивиться, но размер переменной с любым типом данных зависит от компилятора и/или архитектуры компьютера!
Язык C++ гарантирует только их минимальный размер:
| Категория | Тип | Минимальный размер |
| Логический тип данных | bool | 1 байт |
| Символьный тип данных | char | 1 байт |
| wchar_t | 1 байт | |
| char16_t | 2 байта | |
| char32_t | 4 байта | |
| Целочисленный тип данных | short | 2 байта |
| int | 2 байта | |
| long | 4 байта | |
| long long | 8 байт | |
| Тип данных с плавающей запятой | float | 4 байта |
| double | 8 байт | |
| long double | 8 байт |
Фактический размер переменных может отличаться на разных компьютерах, поэтому для его определения используют оператор sizeof.
Оператор sizeof — это унарный оператор, который вычисляет и возвращает размер определенной переменной или определенного типа данных в байтах. Вы можете скомпилировать и запустить следующую программу, чтобы выяснить, сколько занимают разные типы данных на вашем компьютере:
#include <iostream>
int main()
{
std::cout << «bool:\t\t» << sizeof(bool) << » bytes» << std::endl;
std::cout << «char:\t\t» << sizeof(char) << » bytes» << std::endl;
std::cout << «wchar_t:\t» << sizeof(wchar_t) << » bytes» << std::endl;
std::cout << «char16_t:\t» << sizeof(char16_t) << » bytes» << std::endl;
std::cout << «char32_t:\t» << sizeof(char32_t) << » bytes» << std::endl;
std::cout << «short:\t\t» << sizeof(short) << » bytes» << std::endl;
std::cout << «int:\t\t» << sizeof(int) << » bytes» << std::endl;
std::cout << «long:\t\t» << sizeof(long) << » bytes» << std::endl;
std::cout << «long long:\t» << sizeof(long long) << » bytes» << std::endl;
std::cout << «float:\t\t» << sizeof(float) << » bytes» << std::endl;
std::cout << «double:\t\t» << sizeof(double) << » bytes» << std::endl;
std::cout << «long double:\t» << sizeof(long double) << » bytes» << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { std::cout<<«bool:\t\t»<<sizeof(bool)<<» bytes»<<std::endl; std::cout<<«char:\t\t»<<sizeof(char)<<» bytes»<<std::endl; std::cout<<«wchar_t:\t»<<sizeof(wchar_t)<<» bytes»<<std::endl; std::cout<<«char16_t:\t»<<sizeof(char16_t)<<» bytes»<<std::endl; std::cout<<«char32_t:\t»<<sizeof(char32_t)<<» bytes»<<std::endl; std::cout<<«short:\t\t»<<sizeof(short)<<» bytes»<<std::endl; std::cout<<«int:\t\t»<<sizeof(int)<<» bytes»<<std::endl; std::cout<<«long:\t\t»<<sizeof(long)<<» bytes»<<std::endl; std::cout<<«long long:\t»<<sizeof(longlong)<<» bytes»<<std::endl; std::cout<<«float:\t\t»<<sizeof(float)<<» bytes»<<std::endl; std::cout<<«double:\t\t»<<sizeof(double)<<» bytes»<<std::endl; std::cout<<«long double:\t»<<sizeof(longdouble)<<» bytes»<<std::endl; return; } |
Вот результат, полученный на моем компьютере:
Ваши результаты могут отличаться, если у вас другая архитектура, или другой компилятор
Обратите внимание, оператор sizeof не используется с типом void, так как последний не имеет размера
Если вам интересно, что значит в коде, приведенном выше, то это специальный символ, который используется вместо клавиши TAB. Мы его использовали для выравнивания столбцов. Детально об этом мы еще поговорим на соответствующих уроках.
Интересно то, что sizeof — это один из 3-х операторов в языке C++, который является словом, а не символом (еще есть new и delete).
Вы также можете использовать оператор sizeof и с переменными:
#include <iostream>
int main()
{
int x;
std::cout << «x is » << sizeof(x) << » bytes» << std::endl;
}
|
1 |
#include <iostream> intmain() { intx; std::cout<<«x is «<<sizeof(x)<<» bytes»<<std::endl; } |
Результат выполнения программы:
На следующих уроках мы рассмотрим каждый из фундаментальных типов данных языка С++ по отдельности.
Ценность и представление
Значение какого — либо пункта с интегральным типом является математическим целым числом , что оно соответствует. Целочисленные типы могут быть беззнаковыми (способными представлять только неотрицательные целые числа) или знаковыми (способными также представлять отрицательные целые числа).
Целочисленное значение обычно указывается в исходном коде программы как последовательность цифр, необязательно с префиксом + или -. Некоторые языки программирования допускают другие обозначения, например шестнадцатеричные (основание 16) или восьмеричные (основание 8). Некоторые языки программирования также допускают разделители групп цифр .
Внутреннее представление этого элемента данных является то , как значение сохраняется в памяти компьютера. В отличие от математических целых чисел, типичные данные в компьютере имеют минимальное и максимальное возможное значение.
Наиболее распространенное представление положительного целого числа — это строка битов в двоичной системе счисления . Порядок байтов памяти, в которых хранятся биты, варьируется; видеть порядок байтов . Ширина или точности интегрального типа является числом бит в его представлении. Целочисленный тип с n битами может кодировать 2 n чисел; например, беззнаковый тип обычно представляет неотрицательные значения от 0 до 2 n -1. Другие кодировки целочисленных значений для битовых комбинаций иногда используются, например , двоично-кодированной десятичной или код Грея , или в виде печатных кодов символов , таких как ASCII .
Существует четыре хорошо известных способа представления чисел со знаком в двоичной вычислительной системе. Наиболее распространенным является дополнение до двух , которое позволяет целочисленному типу со знаком с n битами представлять числа от −2 ( n −1) до 2 ( n −1) −1. Арифметика с дополнением до двух удобна тем, что существует идеальное взаимно однозначное соответствие между представлениями и значениями (в частности, нет отдельных +0 и -0), и потому , что сложение , вычитание и умножение не должны различать подписанные и беззнаковые типы. . Другие возможности включают двоичное смещение , величину знака и дополнение до единиц .
Некоторые компьютерные языки определяют целочисленные размеры машинно-независимым способом; другие имеют разные определения в зависимости от размера слова процессора. Не все языковые реализации определяют переменные всех целочисленных размеров, а определенные размеры могут даже не различаться в конкретной реализации. Целое число на одном языке программирования может иметь другой размер на другом языке или на другом процессоре.
См. такжеSee also
- Сводка типов данныхData types summary
- Глоссарий редактора Visual Basic (VBE)Visual Basic Editor (VBE) Glossary
- Темы по основам Visual BasicVisual Basic conceptual topics
Поддержка и обратная связьSupport and feedback
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи?Have questions or feedback about Office VBA or this documentation? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.Please see Office VBA support and feedback for guidance about the ways you can receive support and provide feedback.
German[edit]
Adjectiveedit
integer ( , )
- with integrity, of integrity
Declensionedit
Positive forms of integer
| number & gender | singular | plural | |||
|---|---|---|---|---|---|
| masculine | feminine | neuter | all genders | ||
| predicative | er ist integer | sie ist integer | es ist integer | sie sind integer | |
| strong declension (without article) | nominative | ||||
| genitive | |||||
| dative | |||||
| accusative | |||||
| weak declension (with definite article) | nominative | der | die | das | die |
| genitive | des | der | des | der | |
| dative | dem | der | dem | den | |
| accusative | den | die | das | die | |
| mixed declension (with indefinite article) | nominative | ein | eine | ein | (keine) |
| genitive | eines | einer | eines | (keiner) | |
| dative | einem | einer | einem | (keinen) | |
| accusative | einen | eine | ein | (keine) |
Comparative forms of integer
| number & gender | singular | plural | |||
|---|---|---|---|---|---|
| masculine | feminine | neuter | all genders | ||
| predicative | er ist | sie ist | es ist | sie sind | |
| strong declension (without article) | nominative | ||||
| genitive | |||||
| dative | |||||
| accusative | |||||
| weak declension (with definite article) | nominative | der | die | das | die |
| genitive | des | der | des | der | |
| dative | dem | der | dem | den | |
| accusative | den | die | das | die | |
| mixed declension (with indefinite article) | nominative | ein | eine | ein | (keine) |
| genitive | eines | einer | eines | (keiner) | |
| dative | einem | einer | einem | (keinen) | |
| accusative | einen | eine | ein | (keine) |
Superlative forms of integer
| number & gender | singular | plural | |||
|---|---|---|---|---|---|
| masculine | feminine | neuter | all genders | ||
| predicative | er ist am | sie ist am | es ist am | sie sind am | |
| strong declension (without article) | nominative | ||||
| genitive | |||||
| dative | |||||
| accusative | |||||
| weak declension (with definite article) | nominative | der | die | das | die |
| genitive | des | der | des | der | |
| dative | dem | der | dem | den | |
| accusative | den | die | das | die | |
| mixed declension (with indefinite article) | nominative | ein | eine | ein | (keine) |
| genitive | eines | einer | eines | (keiner) | |
| dative | einem | einer | einem | (keinen) | |
| accusative | einen | eine | ein | (keine) |
Integrität
“integer” in Duden online
Теоретико-порядковые свойства
ℤ — полностью упорядоченное множество без верхней и нижней границы . Порядок ℤ определяется следующим образом:
… −3 <−2 <−1 <0 <1 <2 <3 <…
Целое число положительно, если оно больше нуля , и отрицательно, если оно меньше нуль. Ноль не определяется ни отрицательным, ни положительным.
Порядок целых чисел совместим с алгебраическими операциями следующим образом:
- если a < b и c < d , то a + c < b + d
- если a < b и 0 < c , то ac < bc .
Отсюда следует , что ℤ вместе с вышеназванным заказом является упорядоченным кольцом .
Целые числа — единственная нетривиальная вполне упорядоченная абелева группа , положительные элементы которой хорошо упорядочены . Это эквивалентно утверждению, что любое нётерово оценочное кольцо является либо полем, либо дискретным оценочным кольцом .