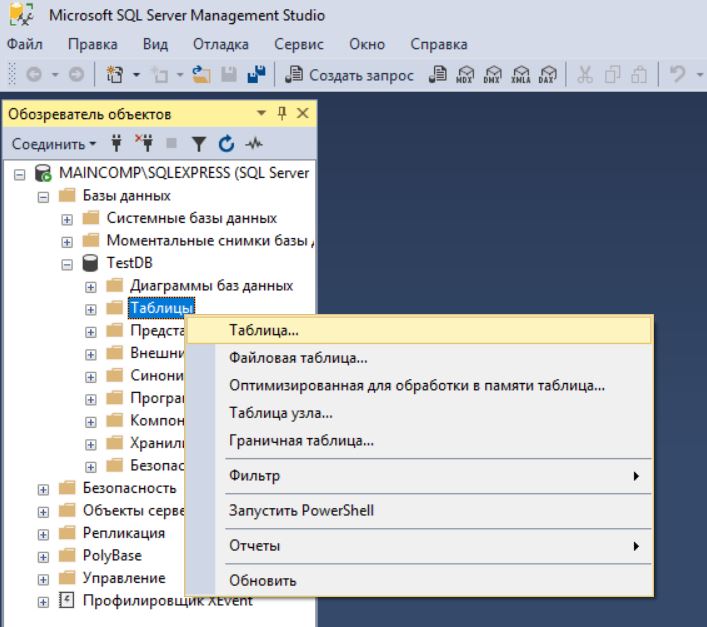
Базы данных и субд
Содержание:
- Современная СУБД состоит из:
- Реляционная модель данных
- Языки манипулирования данными
- Особенности реляционных данных
- Объектно-реляционные субд
- Сравнение SQL и NoSQL
- Реляционные базы данных SQL
- MS Access: где скачать дополнительные шаблоны?
- Иерархическая база данных
- Разница между базой данных и таблицей
- Слово, которое вовсе не имеет значения
- Локальный кэш распределенной информации
- Что такое база данных
- Популярные системы управления реляционными базами данных
- Отношения между таблицами
- Организация информации и данных
- Понятие базы данных
- Для чего нужны
- Базы данных в оперативной памяти
- Другие модели баз данных (ООСУБД)
- Организация информации и данных
- Сетевые
Современная СУБД состоит из:
- ядра — части программ СУБД, отвечающих за управление данными в памяти и журнализацию
- Процессора языка базы данных, обеспечивающего оптимизацию запросов на извлечение и изменение данных, и создание БД
- Подсистемы поддержки времени исполнения, интерпретирующую программы манипуляции данными, которые создают интерфейс пользователя СУБД
- Сервисных программ (внешних утилит), которые обеспечивают прочие возможности по обслуживанию информационных систем.
Так как через СУБД осуществляют все процессы, применимые к базам данных, следовательно, лучше будет выделить только её основные возможности.
Реляционная модель данных
Основной информационной единицей реляционной БД является таблица. База данных может состоять из одной таблицы (однотабличная БД) или из множества взаимосвязанных таблиц (многотабличная БД).
Структурными составляющими таблицы являются записи и поля.
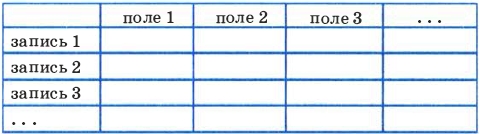
В одной таблице не должно быть повторяющихся записей.
Для каждой таблицы реляционной БД определяется главный ключ — поле или совокупность полей, однозначно определяющих запись. Иначе говоря, значение главного ключа не должно повторяться в разных записях. Например, в библиотечной базе данных в качестве такого ключа может быть выбран инвентарный номер книги, который не может совпадать у разных книг.
Для строчного представления структуры таблицы применяется следующая форма:
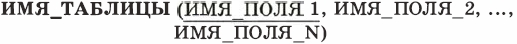
Подчеркиваются поля, составляющие главный ключ.
В теории реляционных баз данных таблица называется отношением. Отношение по-английски — relation. Отсюда происходит название «реляционные базы данных». ИМЯ_ТАБЛИЦЫ в нашем примере — это имя отношения. Примеры отношений:

Каждое поле таблицы имеет определенный тип. С типом связаны два свойства поля:
-
множество значений, которые оно может принимать;
- множество операций, которые над ним можно выполнять.
Поле имеет также формат (длину).
Существуют четыре основных типа для полей БД: символьный, числовой, логический и дата. Для полей таблиц БИБЛИОТЕКА и БОЛЬНИЦА могут быть установлены следующие типы:

В нашем случае поле ПЕРВИЧНЬШ показывает, поступил больной в больницу с данным диагнозом впервые или повторно. Те записи, где значение этого поля равно TRUE (ИСТИНА), относятся к первичным больным, значение FALSE (ЛОЖЬ) отмечает повторных больных. Таким образом, поле логического типа может принимать только два значения.
В таблице БОЛЬНИЦА используется составной ключ — состоящий из двух полей: ПАЛАТА и НОМЕР_МЕСТА. Только их сочетание не повторяется в разных записях (ведь фамилии пациентов могут совпадать).
Языки манипулирования данными
Основное средство для общения с реляционными базами данных — язык структурированных запросов SQL.
Это декларативный язык. То есть инструкции в нём не идут одна за другой (не как в императивных языках). Каждый оператор SQL описывает только необходимое действие, а СУБД сама принимает решение, как его выполнить.
Например, чтобы выбрать все данные из таблицы Messages за 10.11.2020, делается запрос:
SELECT * FROM messages WHERE date = ‘10.11.2020’
Язык структурированных запросов делится на несколько частей (группы операторов) и позволяет:
- определять данные (DDL),
- манипулировать ими (DML),
- контролировать доступ к данным (DCL)
- и управлять транзакциями (TCL).
В SQL изначально нет средств для создания печатных отчётов, экранных форм и других инструментов для разработки программ. Хотя SQL сам по себе не является полноценным (Тьюринг-полным) языком программирования, но его стандарт позволяет создавать процедурные расширения. Они доводят его функциональность до полноценного языка программирования.
При этом синтаксис SQL в разных СУБД может различаться. Кое-где даже используются его отдельные диалекты, например:
- T-SQL — для работы с Microsoft SQL Server;
- на PL / SQL пишут хранимые процедуры и функции в Oracle;
- на PL / pgSQL — в PostgreSQL.
Особенности реляционных данных
Главная особенность — все объекты хранятся в виде набора 2-мерных таблиц. Каждая таблица включает в себя набор столбцов, где указываются следующие параметры:
— название;
— тип данных (число, строка и т. д.).
Вторая важная особенность заключается в том, что число столбцов фиксировано. Это значит, что структура БД известна заранее, при этом количество рядов либо строк данных практически не ограничено. Грубо говоря, строки в реляционных БД — есть объекты, хранимые в базе.
По большему счёту, БД — это абстрактное понятие, а в случае с реляционной структурой таблица — есть не более чем удобный способ хранения информации. Причём набор таблиц превращается в базу данных тогда, когда он связан логически. А чтобы этим всем управлять, используют СУБД. Классический пример СУБД — система управления MySQL. Иными словами, СУБД MySQL — есть программное воплощение математических идей.
Объектно-реляционные субд
Разница между объектно-реляционными и объектными СУБД: первые являют собой надстройку над реляционной схемой, вторые же изначально объектно-ориентированы. Главная особенность и отличие объектно-реляционных, как и объектных, СУБД от реляционных заключается в том, что О(Р)СУБД интегрированы с Объектно-Ориентированным (OO) языком программирования, внутренним или внешним как C++, Java. Характерные свойства OРСУБД:
- комплексные данные,
- наследование типа,
- объектное поведение.
Комплексные данные могут быть реализованы через постоянно-хранимые объекты (persistent objects). Создание комплексных данных в большинстве существующих ОРСУБД основано на предварительном определении схемы через определяемый пользователем тип (UDT — user-defined type). Используются также встроенные конструкторы составных типов, например массив (ARRAY).
Иерархия структурных комплексных данных предлагает дополнительное свойство, наследование типа. То есть структурный тип может иметь подтипы, которые используют все его атрибуты и содержат дополнительные атрибуты, специфицированные в подтипе.
Объектное поведение закладывается через описание программных объектов. Такие объекты должны быть сохраняемыми и переносимыми для обработки в базе данных, поэтому они называются обычно как постоянные (или долговременные) объекты. Внутри базы данных все отношения с постоянным программным объектом есть отношения с его объектным идентификатором (OID).
Объектно-реляционными СУБД являются, к примеру, широко известные Oracle Database, Microsoft SQL Server 2005, PostgreSQL, а также Sav Zigzag, IBM Cloudscape,
Сравнение SQL и NoSQL
- Если SQL-системы основаны исключительно на строгом представлении данных, то NoSQL-системы предоставляют свободу и способны работать с любым типом данных.
- SQL-системы стандартизированы, за счёт чего запросы формируются с использованием языка SQL. В то же время NoSQL-системы базируются на специфической для каждой из них технологии, что является недостатком.
- Масштабируемость. Обе СУБД способны обеспечить вертикальное масштабирование, то есть увеличить объём системных ресурсов на обработку данных. При этом NoSQL, будучи более новой разновидностью баз данных, позволяет применять простые методы горизонтального масштабирования.
- В плане надёжности SQL обладает уверенным лидерством.
- У SQL-баз есть качественная техническая поддержка за счёт их продолжительной истории, в то время как NoSQL-системы весьма молоды и и решить какую-либо проблему сложнее.
- Хранение данных и доступ к их структурам в рамках реляционных систем лучше всего происходит в SQL-системах.
Таким образом, хоть NoSQL и является стремительно развивающейся разновидностью систем управления базами данных, однако на данном этапе рекомендуется остановить свой выбор на SQL.
Надёжность SQL-систем, особенно MySQL, подтверждается временем и массовостью. Сегодня любой уважающий себя ресурс использует для хранения данных именно систему MySQL.
@ivashkevich
04.04.2018 в 19:25
32464
+178
Реляционные базы данных SQL
Если вы когда-либо работали с базами данных, скорее всего, вы начали с этого типа, потому что он самый популярный и распространенный. Такие БД позволяют хранить данные в реляционных таблицах с определенными столбцами определенного типа. Реляционные таблицы хороши для нормализации и объединения.
Достоинства:
- Поддержка SQL
- ACID-транзакции (атомарность, согласованность, изоляция и долговечность)
- Поддержка индексации и разделения
Недостатки:
- Плохая поддержка неструктурированных данных / сложных типов
- Плохая оптимизация обработки событий
- Сложное / дорогое масштабирование
Примеры: Oracle DB, MySQL, PostgreSQL.
MS Access: где скачать дополнительные шаблоны?
Если вы не нашли подходящий шаблон среди предустановленных, то можете попробовать скачать шаблоны для Access из Интернета. К сожалению, количество загрузочных порталов, предоставляющих такие шаблоны, невелико, особенно в Рунете.
-
Для тех, кто владеет языками, существует сайт, Microsoft Templates. Он предлагает хорошую коллекцию бесплатных англоязычных шаблонов для любых продуктов Office, включая Access. Сайт содержит качественную подборку баз данных Access, разбитых по категориям — бизнес, нон-профит, для использования в образовании и так далее. Помимо этого, на сайте доступны шаблоны для Word, Excel, PowerPoint и других программ из офисного пакета MS.
- Существует огромная англоязычная коллекция шаблонов для Microsoft Access — Access Templates. Сайт предлагает солидное количество шаблонов баз данных Access для самых различных отраслей, от образования и медицины до бухучета и программирования. Шаблоны сорируются по версиям Access, дате, популярности. Однако, для полноценного скачивания требуется платная регистрация, которая стоит $88 и достаточно неудобна для России, так как работает через PayPal. В шаблонах, скачанных бесплатно, будут заблокированы таблицы (впрочем, разблокировка — вопрос умения).
- На русском языке существует неплохой проект Access Help. Несмотря на коммерческую направленность проекта, его создатели свободно выкладывают примеры созданных ими баз в Интернет, чтобы их мог использовать любой желающий. Для скачивания доступны готовые базы данных Access для самых разных организаций, особенно для бизнеса.
- Как создать календарь в MS Access
- Как обновить записи в формах MS Access
- Как задать первичный ключ базы данных Access
Фото: авторские, pixabay.com
Иерархическая база данных
Под иерархической понимается такая база данных, в которой хранение данных и их структурирование осуществляется по принципу разделения элементов на родительские и дочерние. Преимуществом таких баз является лёгкость в чтении запрашиваемой информации и её быстрое предоставление пользователю.
Компьютер способен быстро ориентироваться в ней. Иерархический принцип взят за основу в структурировании файлов и папок в операционной системе Windows, а реестр хранит информацию о параметрах работы тех или иных приложений в структурированном иерархическим способом виде.
Все интернет-ресурсы также построены по иерархическому принципу, так как при его использовании ориентироваться в рамках сайта очень легко.
В качестве примера можно привести базу данных на языке XML, содержащую в себе очерки о состоянии сельского хозяйства в регионах России. В этом случае родительским элементом выступит государство, далее пойдёт разделение на субъекты, а в рамках субъектов будет своё разветвление. В данном случае от верхнего элемента к нижнему идёт строго одно обращение.
Разница между базой данных и таблицей
Базы данных и электронные таблицы (например, Microsoft Excel) — удобные способы хранения информации. Основные различия между ними:
- Как данные хранятся и обрабатываются?
- Кто может получить доступ к данным?
- Сколько данных можно хранить?
Таблицы изначально создавались для одного пользователя, и их характеристики отражают это. Они отлично подходят для одного пользователя или небольшого числа пользователей, которым не нужно выполнять множество невероятно сложных манипуляций с данными. С другой стороны, базы данных предназначены для хранения гораздо больших совокупностей организованной информации — иногда огромных объемов. Базы данных позволяют нескольким пользователям одновременно быстро и безопасно получать доступ к данным и запрашивать их, используя очень сложную логику и язык.
Слово, которое вовсе не имеет значения
Главная проблема в области информации — стремительно растущая динамика, к которой пользователь не только привык, он сам ее формирует и заинтересован в адекватности используемых им инструментов.
Базы данных — не самый мобильный и динамичный инструмент. Хочет того разработчик или нет, но он всегда в плену технологий. Он не может создать базу данных, которая не поддерживается существующими СУБД, а создавать собственный вариант в 99 % случаев нет возможности и реальной необходимости.

Между тем, есть и отчасти реализуется иной подход к созданию современных информационных систем. Абстракция, которую принесло с собой объектно-ориентированное программирование и облачные технологии, позволяет определить слово, которое поначалу вовсе не имеет значения, но приобретает его с течением времени.
Каждый занимается своим делом. Базы данных работают в штатном режиме, появляются новые, модернизируются старые. Веб-ресурсы берут на себя функции систем управления базами данных на пользовательском уровне. Поисковые системы ассоциируют ключевые слова и запросы с пространством доступной информации, собранной по их уникальным критериям.
В этих двух примерах и веб-ресурсы — окошки в базы данных и поисковики, в собранную по критериям информацию, представляют собой реально работающую идею динамического использования информации.
Локальный кэш распределенной информации
В системе слежения за почтовыми отправлениями никогда не требуется доступ ко всей информации сразу. Это обычное явление во всех областях применения: есть вся накопленная и доступная информация, а есть та ее маленькая часть, которая актуальна на конкретный момент времени.
Ничто не мешает веб-ресурсу создать локальный образ распределенной базы данных. Например, пришел посетитель. Еще до того, как он сформулирует запрос, можно подгрузить варианты ответа.
Если есть опыт работы с посетителями из конкретной страны, то может быть известно, из каких стран ожидаются данные.

В некоторых странах система слежения загружена, в основном, локальными запросами (внутри страны), ничто не мешает оптимизировать этот момент, а внешние отправления отдать на откуп другим веб-ресурсам. В некоторых случаях необходимо не только предоставить посетителю внешнюю информацию, но и сопоставить сведения по ответу на один и тот же запрос от разных систем слежения.
Сказать, что в таком случае получится объектно-реляционная модель информации и доступа к ней в определенном смысле возможно, но для реализации этой модели потребуется представить инструмент моделирования действий компаний, работающих в области слежения, то есть развивающих свой функционал.
Что такое база данных
Основой для многих информационных систем (прежде всего, информационно-справочных систем) являются базы данных.
|
База данных (БД) — это совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отражающих состояние и взаимодействие объектов в определенной предметной области. |
Под вычислительной системой здесь понимается отдельный компьютер или компьютерная сеть. В первом случае база данных называется централизованной, во втором случае — распределенной.
База данных является компьютерной информационной моделью некоторой реальной системы. Например, книжного фонда библиотеки, кадрового состава предприятия, учебного процесса в школе и т. д. Такую систему называют предметной областью базы данных и информационной системы, в которую БД входит.
Описание структуры данных, хранимых в БД, называется моделью представления данных, или моделью данных. В теории БД известны три классические модели данных: иерархическая, сетевая и реляционная (табличная). По виду используемой модели данных базы данных делятся на иерархические, сетевые и реляционные (табличные).
В последние годы при разработке информационных систем стали использоваться и другие виды моделей данных. К ним относятся объектно-ориентированные, объектно-реляционные, многомерные и другие модели. Классическим вариантом, и пока наиболее распространенным, остается реляционная модель. В курсе информатики основной школы вы уже знакомились с основами реляционных БД. Вспомним главные понятия, связанные с ними.
Популярные системы управления реляционными базами данных
Синтаксис SQL может немного отличаться в зависимости от того, какую СУБД вы используете.
MySQL
Основными преимуществами MySQL являются то, что он прост в использовании, недорого, надежен (существует с 1995 года) и имеет большое сообщество разработчиков, которые могут помочь ответить на вопросы.
Разработка с открытым исходным кодом задерживается с тех пор, как Oracle взяла под свой контроль MySQL, и он не включает некоторые дополнительные функции, к которым могут быть привыкли разработчики.
PostgreSQL
PostgreSQL имеет многие из преимуществ MySQL.
Он прост в использовании, недорог, надежен и имеет большое сообщество разработчиков. Он также предоставляет некоторые дополнительные функции, такие как поддержка внешнего ключа, не требуя сложной настройки.
БД Oracle
Большинство ведущих банков мира используют приложения Oracle, потому что Oracle предлагает мощное сочетание технологий и комплексных, предварительно интегрированных бизнес-приложений, включая основные функции, созданные специально для банков.
SQL Server
Microsoft владеет SQL Server. Как и в Oracle DB, исходный код кода очень близок.
Крупные корпоративные приложения в основном используют SQL Server.
Microsoft предлагает бесплатную версию начального уровня под названием Express, но она может стать очень дорогой при масштабировании приложения.
SQLite
Одним из наиболее значительных преимуществ этого является то, что все данные могут храниться локально без необходимости подключения вашей базы данных к серверу.
SQLite – популярный выбор для баз данных в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных устройствах. Курсы SQL на Codecademy используют SQLite.
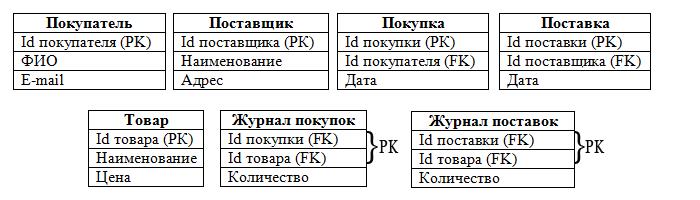
Отношения между таблицами
Чтобы база данных стала реляционной, одних данных мало. Между ними нужны еще и связи (те самые relations, от которых и пошло слово «реляционный»).
Для связи между таблицами служит так называемый внешний ключ (foreign key). Название довольно точно выражает его суть. Если в таблице A есть столбец для хранения первичного ключа таблицы B, то такой столбец и называется внешним ключом. Первичные и внешние ключи устанавливают связи между таблицами, превращая набор таблиц в цельную конструкцию — реляционную базу данных.
Приведу пример. Допустим, мы создали еще одну простую таблицу — справочник товаров. Назовем ее GOODS.
| Товарный справочник GOODS | ||||
| ID | NAME | PRICE | UNIT | COUNTRY |
| 1 | Яблоки | 50.00 | кг | Россия |
| 2 | Груши | 60.40 | кг | Франция |
| 3 | Апельсины | 40.00 | кг | Марокко |
| 4 | Макароны | 21.00 | шт | Франция |
| 5 | Кефир | 25.30 | шт | Россия |
| 6 | Молоко | 30.50 | шт | Россия |
Ее колонки: ID — первичный ключ, NAME — название товара, PRICE — его цена, UNIT — краткое название единицы измерения, COUNTRY — название страны-производителя.
Хорошо ли построена такая таблица? Вроде бы всем упоминавшимся выше принципам она удовлетворяет: уникальные имена столбцов с однородными данными, строки с уникальным первичным ключом. Казалось бы, все на месте. Тем не менее построена она непрофессионально. Здесь мы подходим к принципам, о которых я еще не упоминал, — к понятию о нормализации таблиц. Суть в том, чтобы всюду, где только можно, избегать избыточности в хранении данных путем выделения их в отдельные таблицы.
Посмотрим на нашу таблицу GOODS. Чем она плоха? Представьте себе, что завтра придется изменить название какой-нибудь страны. Такое случается часто. Бирма когда-то меняла свое название на Мьянму, Польша — на Польскую Республику. Хочется ли вам менять огромное количество строк во всех таблицах, где эти страны упоминаются? Представьте также, что вас попросят отобрать запросом весь штучный товар. Можете ли вы быть уверены в том, что оператор всюду набил эту аббревиатуру правильно и одинаково? Скорее всего, окажется, что в таблице встречаются все мыслимые вариации: «шт», «Шт», «шт.», «штук» и «штуки».
Думаю, проблема понятна. Выходом из этой ситуации будет выделение из нее двух других таблиц: справочника стран (COUNTRIES) и справочника единиц измерений (UNITS).
| Справочник единиц измерения UNITS | ||
| ID | NAME | SHORT_NAME |
| 1 | Штуки | шт |
| 2 | Килограммы | кг |
Сам справочник товаров GOODS будет теперь выглядеть совершенно по-другому (см. таблицу).
| Товарный справочник GOODS после нормализации | ||||
| ID | NAME | PRICE | UNIT_ID | COUNTRY_ID |
| 1 | Яблоки | 50.00 | 2 | 1 |
| 2 | Груши | 60.40 | 2 | 2 |
| 3 | Апельсины | 40.00 | 2 | 3 |
| 4 | Макароны | 21.00 | 1 | 2 |
| 5 | Кефир | 25.30 | 1 | 1 |
| 6 | Молоко | 30.50 | 1 | 1 |
Что изменилось? Вместо столбцов с названиями единиц измерения и стран появились столбцы UNIT_ID и COUNTRY_ID с кодами, отсылающими нас к другим таблицам. Это и есть внешние ключи. Что означает значение 2 в столбце UNIT_ID? Оно означает, что интересующая нас информация по единице измерения находится той строке таблицы UNITS, где ID = 2. Достаточно заглянуть в этот справочник, чтобы убедиться, что называется эта единица полностью «штуки», а кратко — «шт».
Объяснение всех видов и принципов нормализации выходит далеко за рамки данной статьи. Главное — почувствовать общие принципы. Единожды научившись строить базы данных правильно, вы уже не сможете иначе. Для этого не обязательно знать теорию в полном объеме — зачастую здравого смысла и интуиции бывает достаточно.
Вернемся к нашей маленькой базе данных. Ну хорошо, нормализовали мы таблицу. Сможем теперь менять названия стран, не исправляя всю таблицу. Замечательно. Но как теперь увидеть эти названия? Ведь в справочнике товаров появились коды, и таблица сразу потеряла свою наглядность.
Вот тут-то мы и подходим к понятию уже не раз упоминавшихся запросов, которые, используя связи, извлекают из них нужную информацию и выдают нам опять же в виде так называемой отчетной таблицы.
Организация информации и данных
По общему правилу, информация — это естественное явление, а данные — это сфера компетенции алгоритма, программы или разработчика. Часто не делают особого различия между терминами информация, данные и объекты базы данных.
Формализация области применения — это модель: реальный объект и предмет в этом объекте. Например, компания и ее финансовая составляющая, или компания и планирование производства. В каждой из этих двух задач отличаются не только данные, но и условия их использования.
- В бухгалтерии время и дата имеет одно значение и не может трансформироваться за пределы конкретных условий (дата сдачи отчетов в налоговую, даты платежей в бюджет, даты оплаты коммунальных услуг, выплата зарплаты…).
- В планово-производственном отделе время и дата имеет совершенно другой смысл, но она здесь никак не привязана ни к месяцу, ни к кварталу, зато имеет существенное отличие — дата может быть началом и концом периода.
Даже формат представления числовой информации может иметь важное значение и на него влияет внешнее обстоятельство. Вчера деньги измерялись тысячами и миллионами, сегодня это рубли и копейки
Вчера требовалось двадцать цифр в целой части и ноль в дробной, сегодня достаточно пяти цифр в целой части, но обязательно две цифры — в дробной. Это частности, но их в реальности возникает множество.

Беспристрастный анализ баз данных и их применений позволяет определить основной критерий для формирования правильной их организации: реально функциональная база данных — это такая система управления информацией, которая отражает ее динамику и может подстраиваться без участия программиста.
Понятие базы данных
Построение статической модели важно. Это этап формирования представлений о том, что актуально в области применения и понимания, что может в ней развиваться дальше
На современном уровне знаний динамика — это дискретная последовательность статических моделей, а точнее — серии воплощений представлений в форме доступной для понимания не только автором, то есть вне его сознания, в модели, в графике, в связях, в программных описаниях.
По общему мнению, «база данных — это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств. Информация в базах хранится в упорядоченном виде».

Энциклопедическое «знание» обычно гласит: «База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины».
Некоторые авторы по старинке (до того, как компьютеры стали персональными, переносными и карманными) выделяют особую когорту: настольные базы данных к которым относят все, что меньше одного терабайта, а также не имеет отношения к Oracle.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
- Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
- Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
- Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
- Не дать прочитать эти данные тем, кому не следует, а кому надо — дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
- Поддерживать порядок и не дать захламиться — если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
- Масштабироваться — чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
- Не потерять данные — если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.
Базы данных в оперативной памяти
Базы данных этого типа могут предоставлять в реальном времени ответ для выбора и вставки определенных записей. Большинство из них в основном хранят данные в ОЗУ, но в некоторых случаях они также предлагают постоянное хранилище на жестких дисках или твердотельных накопителях. Большинство этих баз данных работают с записями «ключ-значение», поэтому значения можно запоминать в формате, ориентированном на документы. Но некоторые базы данных также работают со столбцами и позволяют вторичное индексирование той же таблицы. Использование ОЗУ позволяет обрабатывать данные быстро, но делает их более нестабильными и дорогостоящими.
Достоинства:
- Быстрое написание
- Быстрое чтение
Недостатки:
- Труднодостижимая надёжность
- Дорогое масштабирование
Примеры: Redis, Tarantool, Apache Ignite.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Организация информации и данных
По общему правилу, информация — это естественное явление, а данные — это сфера компетенции алгоритма, программы или разработчика. Часто не делают особого различия между терминами информация, данные и объекты базы данных.
Формализация области применения — это модель: реальный объект и предмет в этом объекте. Например, компания и ее финансовая составляющая, или компания и планирование производства. В каждой из этих двух задач отличаются не только данные, но и условия их использования.
- В бухгалтерии время и дата имеет одно значение и не может трансформироваться за пределы конкретных условий (дата сдачи отчетов в налоговую, даты платежей в бюджет, даты оплаты коммунальных услуг, выплата зарплаты…).
- В планово-производственном отделе время и дата имеет совершенно другой смысл, но она здесь никак не привязана ни к месяцу, ни к кварталу, зато имеет существенное отличие — дата может быть началом и концом периода.
Даже формат представления числовой информации может иметь важное значение и на него влияет внешнее обстоятельство. Вчера деньги измерялись тысячами и миллионами, сегодня это рубли и копейки
Вчера требовалось двадцать цифр в целой части и ноль в дробной, сегодня достаточно пяти цифр в целой части, но обязательно две цифры — в дробной. Это частности, но их в реальности возникает множество.

Беспристрастный анализ баз данных и их применений позволяет определить основной критерий для формирования правильной их организации: реально функциональная база данных — это такая система управления информацией, которая отражает ее динамику и может подстраиваться без участия программиста.
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:
Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
- возьмёт имя режиссёра;
- посмотрит, какие связи и с чем у него есть;
- выдаст список фильмов;
- к этим фильмам может сразу подгрузить список актёров, которые там играют;
- и сразу же показать постеры к каждому фильму.
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.