Продвинутое использование robots.txt без ошибок
Содержание:
- Введение
- Как закрыть от индексации сразу весь раздел на проекте
- Как закрыть ссылки от индексации с помощью rel=”nofollow” или nofollow
- Правила настройки
- Как поисковики сканируют страницу
- Из чего состоит robots.txt
- Опасные методы закрытия индексации в robots.txt
- Как закрыть сайт от индексации в WordPress?
- Запрет с помощью маршрутизатора
- Как заблокировать сайт в файле hosts, чтобы он не открывался
- Как исправить зависание WordPress в режиме техобслуживания
- Синтаксис robots.txt
- Понятие файла robots.txt и требования, предъявляемые к нему
- Для чего нужна проверка robots.txt
- Как закрыть от индексации определенные элементы на страницах сайта
- Разница между индексированием и показом в результатах поиска Google
- Закрыть доступ к сайту через Брандмауэр
Введение
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
Как закрыть от индексации сразу весь раздел на проекте
1 Вариант реализовать это с помощь robots.txt
User-agent: * Disallow: /razdel
Еще варианты:
Также подойдут варианты, которые используются при скрытии страницы от индекса, только в данном случае это должно распространятся на все страницы раздела — конечно же если это позволяет сделать автоматически
- Ответ сервера для всех страниц раздела
- Вариант с метатегами к каждой странице
Это все можно реализовать программно, а не в ручную прописывать к каждой странице — трудозатраты — одинаковые.
Конечно же проще всего это прописать запрет в robots, но наша практика показывает, что это не 100% вариант и поисковые системы бывает игнорируют запреты.
Как закрыть ссылки от индексации с помощью rel=”nofollow” или nofollow
Rel=”nofollow“
Несмотря на богатое прошлое элемента rel=”nofollow”, на сегодняшний день он больше не
имеет статуса тега, а является атрибутом. Какие интересные функции выполняет
данный элемент:
- позволяет скрыть подозрительную для поисковых ботов информацию, включающую комментарии к блогу, ссылки на сомнительные ресурсы, тексты с большим количеством спама;
- закрытие от индексации платных ссылок, что поможет защитить сайт от блокировки;
- поднятие в рейтинге сканирования поисковыми системами. Как известно, внешние ссылки значительно увеличивают «вес» html-страницы, а их скрытие делит «вес» на меньшие составляющие.
Большим преимуществом является тот факт, что
сервис Яндекс пока не умеет «читать» данный элемент.
Nofollow
Главное отличие данного элемента от
предыдущего лишь в историческом аспекте: ранее элемент использовался только в
качестве атрибута для тега rel. Но в некоторые моменты
истории верстки html-страниц элемент
приобрел иной статус – положение самостоятельного тега. Надо сказать, что
функции он выполняет те же, что и его собрат атрибут.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые — только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки
Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.
Такой вариант, наоборот, означает полный запрет индексации для всех.
Запрет на просмотр всего содержимого определенной папки-каталога
Для блокировки одного файла нужно указать его абсолютный путь
Директивы Sitemap, Host
В файл, как правило, добавляют ссылку на «Sitemap» (карту сайта), чтобы облегчить боту ее поиск.
Для Яндекса в директиве Host принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.
Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.
Директива Crawl-delay
С помощью нее можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено
краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта —
Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
-
Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). -
Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. -
Быстро загружаются.
Проверьте скорость загрузки
инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью
анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
«Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.ru/sitemap.xml Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Опасные методы закрытия индексации в robots.txt
Также существует достаточно грубый метод Закрытия чего — либо от роботов, а именно запрет на уровне сервера на доступ робота к конкретному контенту.
1. Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.
?
В данному случае плохим ботом можно указать Любую поисковую машину, парсер либо что либо еще.
Подобные техники используются например для скрытия от робота Ахрефса ссылки с сайта, который был создан/сломан, чтобы конкуренты сеошники не увидели истинных источников ссылочной массы сайта.
Однако это метод стоит использовать если вы точно знаете, что хотите сделать и здраво оцениваете последствия от этих действий.
2. Использование HTTP-заголовка X-Robots-Tag
Заголовок X-Robots-Tag, выступает в роли элемента HTTP-заголовка для определенного URL. Любая директива, которая может использоваться в метатеге robots, применима также и к X-Robots-Tag.
В X-Robots-Tag перед директивами можно указать название агента пользователя. Пример HTTP-заголовка X-Robots-Tag, который запрещает показ страницы в результатах поиска различных систем.
Заключение
Ситуации, когда необходимо закрыть контент от индексации случаются довольно часто, иногда нужно почистить индекс, иногда нужно скрыть какой-то нежелательный материал, иногда нужно взломать чужой сайт и в роботсе указать disalow all, чтобы выбросить сайт зеркало из индекса.
Основные и самые действенные методы мы рассмотрели, как же их применять — дело вашей фантазии и целей, которые вы преследуете.
Как закрыть сайт от индексации в WordPress?
Данный способ, наверное, самый простой, и владельцам сайтов, которые созданы на базе CMS WordPress, очень повезло. Дело в том, что в данной CMS предусмотрена возможность закрытия сайта от индексации при установке движка на хостинг. В случае если вы не сделали этого при установке, вы всегда можете это сделать в настройках. Для этого вам нужно:
- 1.В админпанели переходим в раздел «Настройки» → «Чтение».
-
2.Перелистываем открывшуюся страницу в самый низ, и отмечаем галочкой опцию показанную на скриншоте:
- 3.Сохраняем изменения.
Все. Теперь ваш сайт не будет индексироваться. Если открыть страницу в браузере и нажать комбинацию клавиш CTRL+U, мы сможем просмотреть код страницы, и увидим вот такую строку кода:
Данная запись была добавлена автоматически, после того как мы включили опцию запрета индексации в настройках.
Главное не забыть отключить эту опцию после завершения работ:)
Запрет с помощью маршрутизатора
Этот вариант считается наиболее надежным и удобным. В первую очередь, доступ к роутеру есть лишь у пары человек, знающих пароль. Дети о нем ничего не знают. К тому же разобраться в настройках этого оборудования не просто, а уж тем более найти конкретный параметр. Если воспользоваться этим вариантом, то блокировку в браузерах и файле с хостами делать не придется. Вводите один раз наименование ресурс, и он сразу становится недоступным ни для одного аппарат, подключаемого к домашней сети. Для входа в устройство нужно будет узнать его адрес и информацию для входа – пароль и логин, они расположены обычно на обратной стороне оборудования.
Далее на компьютере в браузерную строку вбиваете веб-адрес роутера, а после логин (username) и пароль (password) — они также прописаны на «наклейке». Вы попадаете на внутренний сервер устройства, где понадобится настройка фильтров.
Не получится рассказать об интерфейсе каждого изделия, так что внимательно просматривайте инструкцию к своей модели.
Как заблокировать сайт в файле hosts, чтобы он не открывался
Наиболее простым и верным вариантом, для того чтобы прикрыть доступ к одному или сразу нескольким адресам, является решение с изменениями в так называемом файле hosts. Данный объект принадлежит Windows, но открыть его можно обычным Блокнотом. Он позволяет прописывать сайты, чтобы они больше не открывались. Для этого потребуется добавлять отдельной строчкой IP своего ПК и далее вписывать наименования ресурсов. Помимо этого, хостс перенаправит пользователя на другой сайт при попытке нарушения запрета. Инструкция будет следующей:
Находите нужный системный файл по пути:
C | Window | System32 | drivers | etc
- Для его открытия необходимо нажать правую кнопку мышки. После этого будет доступно дополнительное меню с командой «Открыть с помощью…»;
- Используете простой «Блокнот».
Теперь без смены ай-пи вписываете адреса для блокировки, каждый с новой строки. После этого сохраняете изменения.
После можете протестировать свои усилия, открыть любую программу и проверить один из вписанных сайтов.
Этот способ поможет заблокировать неограниченное количество сайтов, но о нем знают лишь «продвинутые» юзеры. Вот только изменить что-то в файле hosts можно только, если открывали его в режиме администратора.
Это может пригодиться:
- Как исправить ошибку sec error revoked certificate в Firefox
- Устраняем ошибку 14098 — хранилище компонентов повреждено
- Устраняем ошибку «Системе не удается найти указанный путь» при скачивании торрентов
- Как освободить память Android, ничего не удаляя!
- Как на Айфоне почистить кэш, освободить память
Как исправить зависание WordPress в режиме техобслуживания
Если у вас не установлен плагин для техобслуживания, то первое, на что стоит обратить внимание, – это файл .maintenance. Его нужно просто удалить, и все проблемы с зависанием уйдут напрочь
Для этого выполните следующее:
- Подключитесь к сайту с помощью FTP-клиента либо по SSH.
- Найдите в корневой папке файл .maintenance и удалите его.
- Перезагрузите страницу сайта. Все должно заработать!
Вполне возможно, что сайт зависает вследствие реальной ошибки. Скорее всего, она вызвана плагином – в этом случае потребуется его удалить либо отключить. Если же отключение плагина не помогает, то попробуйте восстановить сайт из резервной копии.
Синтаксис robots.txt
Как настроить robots.txt? Примерно так может выглядеть блок robots.txt, ориентированный на Google.

Комментарии
Комментарии — это строки, которые полностью игнорируются поисковыми системами. Они начинаются со знака #. Они нужны для заметок о том, какие действия выполняют строки файла. Рекомендуется документировать каждую директиву в robots.txt, чтобы она могла быть удалена за ненадобностью или отредактирована.
Указания User-agent
Это блок, который даёт указания поисковым системам и роботам, используя директиву User-agent. Например, если вы хотите установить правила отдельно для Яндекса и Google. Тем не менее, он не применим для Facebook и рекламный сетей — на них можно повлиять только через специальный токен с применением особых правил.
Каждый робот предусматривает собственный user-agent токен.
Краулеры сперва учитывают наиболее точные директивы, разделённые дефисом, а затем переходят к объемлющим. Так, Googlebot News сначала выполнит указания для User-agent «googlebot-news», а потом уже «googlebot» и впоследствии «*».
Наиболее распространённые роботы в российском сегменте — это:
Конечно, этот список далеко не исчерпывающий. Чтобы ознакомиться с полным перечнем используемых поисковиками и другими системами роботов, лучше прочитайте их документацию.
Наименования роботов в robots.txt нечувствительны к регистру. «Googlebot» и «googlebot» вполне взаимозаменяемы.
Шаблоны адресов
Вместо того, чтобы прописывать большой перечень конечных URL для блокировки, достаточно указать только шаблоны адресов.
Для эффективного использования такой функции понадобится два знака:
* — данный символ группировки обозначает любое количество символов. Его лучше располагать в начале или внутри адреса, но не в конце. Можно использовать сразу несколько групповых символов — например, «Disallow: */notebooks?*filter=». Правила с полными адресами не должны начинаться с данного символа.
$ — знак доллара означает конец адреса. Так, «Disallow: */item$» будет соответствовать URL, заканчивающемуся на «/item», но не «/item?filter» или подобным.
Обратите внимание, что эти правила уже чувствительны к регистру. Если вы запрещаете адреса с параметром «search», роботы всё ещё будут просматривать адреса, содержащие «Search»
Директивы работают только с телом адреса и не включают протокол или сам домен. Слэш в начале адреса означает, что данная директория располагается сразу после основного каталога. Например, «Disallow: /start» будет соответствовать «www.site.ru/start
Пока вы не добавите * или в начало директивы, она не будет ничему соответствовать. «Disallow: start» не будет иметь смысла — роботы её не поймут.
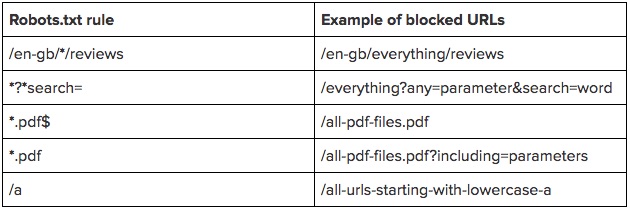
Чтобы наглядно продемонстрировать правило, приведём таблицу примеров:
Sitemap.xml
Директива Sitemap в robots.txt говорит поисковикам, где найти карту сайта в формате XML. Это поможет им лучше ориентироваться в структуре страниц.
Для Sitemap вы должны указать полный путь, как это сделано у нас: «Sitemap: https://www.calltouch.ru/sitemap.xml». Также следует отметить, что Sitemap не всегда располагается на том же домене, что и весь сайт.
Поисковые роботы прочитают указанные в robots.txt карты сайтов, но они не появятся в том же Google Search Console, пока вы не дадите на это разрешение.
Host
Этот элемент раньше работал исключительно как инструкция для Яндекса, другим поисковым системам она была непонятна. Он указывал роботу Яндекса на главное зеркало сайта, и система рассматривала его в приоритетном порядке.
Директива Host уже не поддерживается Яндексом, решение об этом было принято еще в 2018 году. Теперь вместо нее схожий функционал выполняет раздел «Переезд сайта», доступный в Яндекс.Вебмастере.
Понятие файла robots.txt и требования, предъявляемые к нему
Файл /robots.txt предназначен для указания всем поисковым роботам (spiders) индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые не описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id) и указывают для каждого робота или для всех сразу, что именно им не надо индексировать.
Синтаксис файла позволяет задавать запретные области индексирования, как для всех, так и для определенных, роботов.
К файлу robots.txt предъявляются специальные требования, не выполнение которых может привести к неправильному считыванию роботом поисковой системы или вообще к недееспособности данного файла.
Основные требования:
- все буквы в названии файла должны быть прописными, т. е. должны иметь нижний регистр:
- robots.txt – правильно,
- Robots.txt или ROBOTS.TXT – неправильно;
- файл robots.txt должен создаваться в текстовом формате Unix. При копировании данного файла на сайт ftp-клиент должен быть настроен на текстовый режим обмена файлами;
- файл robots.txt должен быть размещен в корневом каталоге сайта.
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Как закрыть от индексации определенные элементы на страницах сайта
Альтернативный вариант атрибута nofollow, придуман сотрудниками «Яндекса», не используется в официальной спецификации html, выглядит так:
<!—noindex—>Любая часть страницы сайта: код, текст, который нужно закрыть от индексации<!—/noindex—>.
Не нужно путать сеошный тег с одноименным мета-тегом, прописываемым в файле robots.txt и запрещающим ботам сканирование всей страницы. SEO-тег <noindex> означает запрет на индексацию части кода.
Что можно спрятать благодаря использованию SEO-тега <noindex>:
- неуникальный, дублирующий, динамичный текстовый контент;
- счетчики и баннеры;

- формы подписки на рассылку;
- различный «мусорный» текст.
Многие веб-мастера продолжают пользоваться названным тегом, не меньшее количество программистов считают, что он изжил себя, относят его к инструменту так называемой серой оптимизации и предпочитают использование атрибута, описание которого приведено ниже.
Атрибут rel=»nofollow».
О важности ссылочной массы для любого ресурса можно говорить долго, но важно понимать, что неграмотное использование инструмента приводит к негативным последствиям в виде понижения в выдаче и потери сайтом «весомости», поскольку вес страницы, имеющей внешнюю ссылку, делится с тем самым сторонним ресурсом, на который ссылается сайт. Конечно, обидно
Чтобы не допустить неоправданного разделения веса, можно запретить роботам индексацию некоторых ссылок. В таком случае они не станут учитывать вес ссылки на сторонний ресурс. Помогает в этом атрибут rel=»nofollow».
Итак, использование атрибута rel=»nofollow» тега <a> оправданно, если требуется:
- Запретить индексацию ссылок, оставляемых пользователями.
- Скрыть от роботов рекламные и бартерные ссылки.
- Не делиться весом с популярным ресурсом, ссылка на который необходима.
- Обозначить приоритетные направления для поисковых роботов (закрыть все ненужное, сделав работу пауков целенаправленной).
Важно, чтобы внешних ссылок не было слишком много во избежание проблем с индексацией и ранжированием, но и запретов должны использоваться умеренно, поскольку искусственный интеллект сразу начинает подозревать неладное в большом объеме «секретов».
SEOhide.
Еще один метод сокрытия контента и ссылок от поисковиков с помощью JavaScript: в коде страницы элементы скрываются, а пользователям остаются доступны.
При этом некоторые эксперты склонны рассматривать SEOhide как «черный» метод продвижения, поскольку поисковые пауки и посетители видят разные версии контента. Отсюда один из главных минусов технологии – угроза попасть под санкции за клоакинг.
Другие веб-мастера апеллируют к тому, что невозможность прочитать «Яваскрипт» – проблема поискового робота, а вовсе не программистов, поэтому санкции к сайту из-за обвинений в клоакинге применяться не могут. К тому же близок тот час, когда поисковые роботы научатся полноценно распознавать шифры JavaScript.
Что касается преимуществ технологии SEOhide, к их числу относятся:
- неограниченность в использовании для всех поисковиков;
- корректное распределение ссылочного веса;
- возможность уменьшить заспамленность текста;
- доказанная эффективность использования онлайн-магазинами, чьи каталоги могут занимать несколько сотен страниц.
Разница между индексированием и показом в результатах поиска Google
Прежде чем объяснить, почему запрет на индексирование сайта не мешает поисковику выводить его в выдаче, вспомним несколько терминов:
- Индексирование – процесс скачивания сайта или страницы контента на сервер поисковой системы, вследствие которого сайт или страница добавляется в индекс.
- Ранжирование/ отображение в поиске – отображение сайта среди результатов поиска.
 Наиболее распространенное представление о попадании сайта/страницы в результаты поиска выглядит как двухэтапный процесс: индексирование => ранжирование. Но чтобы отображаться в поиске, сайт не обязательно должен индексироваться. Если есть внешняя ссылка на страницу или домен (линк с другого сайта или с индексируемых внутренних страниц), Google перейдет по этой ссылке. Если robots.txt на этом домене препятствует индексированию страницы поисковой системой, Гугл все равно будет выводить URL в выдаче. Он ориентируется на внешние источники, которые содержат ссылку и ее описание. Раньше источником мог быть DMOZ или директория Yahoo. Сегодня я вполне могу представить, что Google использует, например, ваш профиль в My Business или данные из других сайтов.
Наиболее распространенное представление о попадании сайта/страницы в результаты поиска выглядит как двухэтапный процесс: индексирование => ранжирование. Но чтобы отображаться в поиске, сайт не обязательно должен индексироваться. Если есть внешняя ссылка на страницу или домен (линк с другого сайта или с индексируемых внутренних страниц), Google перейдет по этой ссылке. Если robots.txt на этом домене препятствует индексированию страницы поисковой системой, Гугл все равно будет выводить URL в выдаче. Он ориентируется на внешние источники, которые содержат ссылку и ее описание. Раньше источником мог быть DMOZ или директория Yahoo. Сегодня я вполне могу представить, что Google использует, например, ваш профиль в My Business или данные из других сайтов.
Если написанное выше кажется вам бессмысленным, посмотрите видео с объяснением Мэтта Каттса.
Адаптация видео:
Пользователи часто жалуются на то, что Google игнорирует запрет на индексирование страницы в robots.txt и все равно показывает ее в результатах выдачи. Чаще всего происходит следующее: когда некто отправляет роботу сигнал на запрет индексирования страницы, она появляется в поиске с необычным сниппетом – без текстового описания. Причина: краулеры не сканировали страницу. Они видели только упоминание URL. Именно потому что роботы видели ссылку, а не саму страницу, в выдаче пользователям предлагается сниппет без дескрипшна. Обратимся к примеру.
В какой-то момент California Department of Motor Vehicles, домен www.dmv.ca.gov, заблокировала все поисковые системы с помощью robots.txt. Но если пользователь ищет информацию по запросу California DMV, есть только один релевантный ответ, который поисковик должен предложить пользователю. Несмотря на robots.txt, который говорит роботу, что он не должен сканировать страницу, краулер видит, что многие сайты ссылаются на определенную страницу, используя анкоры с текстом California DMV. Роботы понимают, что эта страница – результат, наиболее релевантный запросу пользователя. Поэтому они показывают результат в выдаче даже без сканирования страницы. Желание предоставить пользователю результат, наиболее релевантный запросу, может быть единственной причиной, по который Google выводит в результатах поиска страницы, не сканированные краулерами.
Еще один пример – сайт Nissan. Долгое время Nissan использовал robots.txt для запрета индексирования всех страниц. Но мы обнаружили сайт и его описание в открытом каталоге DMOZ. Поэтому когда пользователи получали ссылку на сайт среди результатов, они видели такой же сниппет, как и у обычных страниц, которые были просканированы краулерами. Но этот сниппет был составлен не на основе результатов сканирования. Он был создан из информации DMOZ.
В итоге: Google может показать что-то, что считает полезным пользователю, без нарушения запрета на сканирование в robots.txt.
Если вы не хотите, чтобы страница отображалась в поиске, позвольте роботам просканировать страницу, а затем используйте атрибут noindex. Когда робот видит тег «noindex», он выбрасывает страницу изо всех поисковых результатов. Страница не появляется в поиске, даже если на нее ссылаются другие сайты.
Другой вариант – использовать инструмент удаления URL. Блокируйте сайт полностью в robots.txt, а после используйте инструмент удаления URL.
Что получается: закрывая сайт от сканирования, вы лишаете краулеров возможности узнать, что запретили отображение сайта в поисковой системе.
Поэтому:
Чтобы запретить появление сайта в результатах поиска, вам нужно позволить краулерам Google просканировать страницу.
Это может выглядеть противоречиво. Но только так вы сможете скрыть сайт в результатах поиска.
Закрыть доступ к сайту через Брандмауэр
Прежде чем приступать к блокировке сайтов брандмауэром вам потребуется узнать их IP- адреса. Сделать это можно при помощи специальных сервисов, например через сервис “2ip”. Здесь вам нужно просто ввести адрес интересующего вас сайта и нажать “Проверить”, после чего вы получите всю нужную информацию о нём.
Заполучив IP сайта, сделайте с ним следующее:
- Для начала запустите панель управления и найдите раздел “Брандмауэр Защитника Windows”.
- В данном разделе, на панели слева выберите пункт “Дополнительные параметры”.
- Затем в списке в левой части экрана выберите раздел “Правила для исходящего подключения”.
- Теперь в списке справа выберите пункт “Создать правило…”.
- Появится новое окно, выберите пункт “Настраиваемые” и нажмите “Далее”.
- Затем выбираем пункт “Все программы” и вновь жмём “Далее”.
- На следующей странице просто нажмите “Далее”.
- На новой странице в разделе “Укажите удалённый IP-адрес” активируйте пункт “УказанныеIP-адреса”.
- Затем нажмите “Добавить…”, в появившемся окошке введите IP блокируемого сайта и нажмите “OK”.
- Если вы хотите добавить в чёрный список несколько сайтов, то повторяйте предыдущий пункт столько раз сколько нужно, затем, когда все сайты будут добавлены, нажмите “Далее”.
- На следующей странице выберите действие “Блокировать подключение” и нажмите “Далее”.
- Затем укажите имя созданного вами правила (придумайте сами) и сохраните его.
После этого добавленные сайты будут автоматически блокироваться.