Кодировка символов windows-1251
Содержание:
- Программы для определения кодировки в Linux
- Инструменты для работы с кодировками HTML файлов
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Базы банных
- Немного из истории
- Набор символов
- Кодировка windows 1251 в html
- Кодировка символов в Windows PowerShell
- Неправильная кодировка результатов из базы данных MySQL
- Казахский вариант
- Консоль Внедренца v.3.6.2
- Комментарии
- Неправильная кодировка HTML страниц
Программы для определения кодировки в Linux
Чтобы узнать кодировку файла используется команда file с флагами -i или –mime, которые включают вывод строки с типом MIME. Пример:
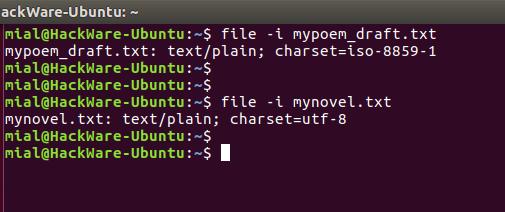
Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
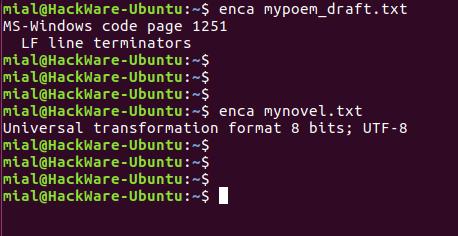
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
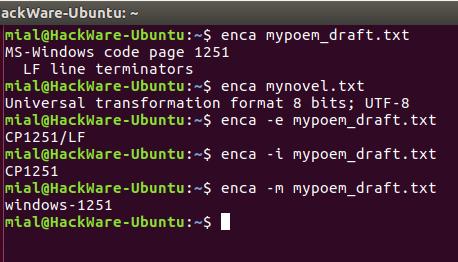
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Инструменты для работы с кодировками HTML файлов
Собственно, их всего три:
- PSPad. Бесплатный текстовый редактор, мой любимый.
- Notepad++. Еще один хороший текстовый редактор и тоже бесплатный.
- Dreamweaver. Ну с Dreamweaver-ом вы с вами знакомы из моих видеоуроков по верстке сайта.
Загружаем какой-то HTML-файл в PSPad. И как же нам понять, что за кодировка у загруженного подопытного? Очень просто в строке состояния (внизу) все четко написано.
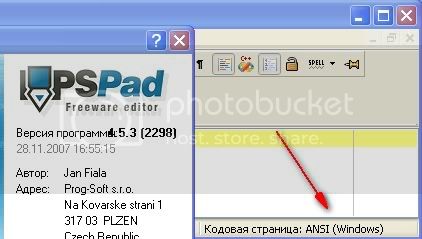
Кодировка открытого HTML-файла windows-1251
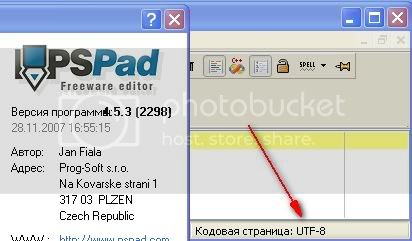
А у этого файла HTML кодировка utf-8
А теперь, создавая новый HTML-документ, позаботимся о его кодировке.
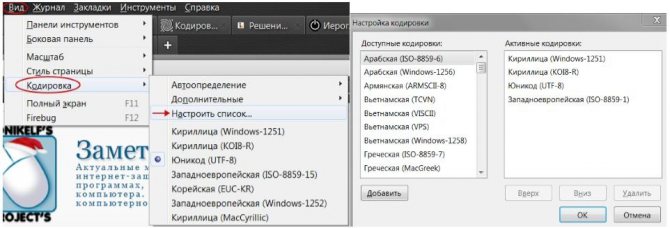
Идем в меню моего любимого PSPad-а. Нас интересует пункт Формат. В нем-то мы и поставим галку напротив кодировки utf-8.
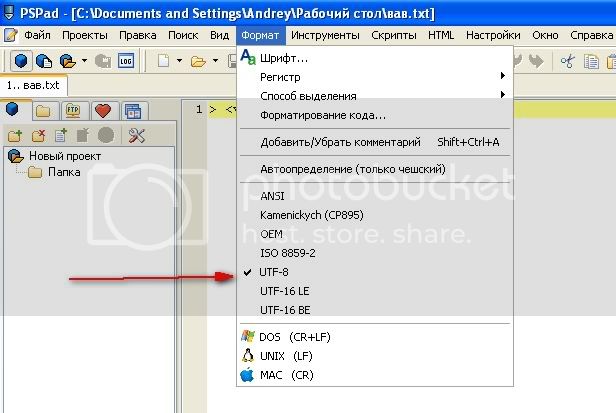
Кодировка будущего HTML-файла будет utf-8
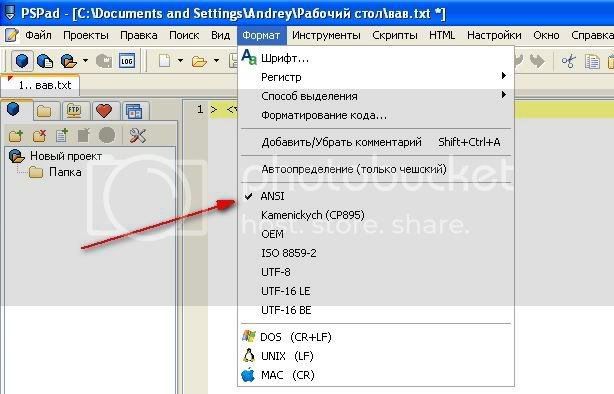
А так кодировка будующего файла — windows-1251
Теперь о том как изменить кодировку файла HTML. Да оказывается очень просто:
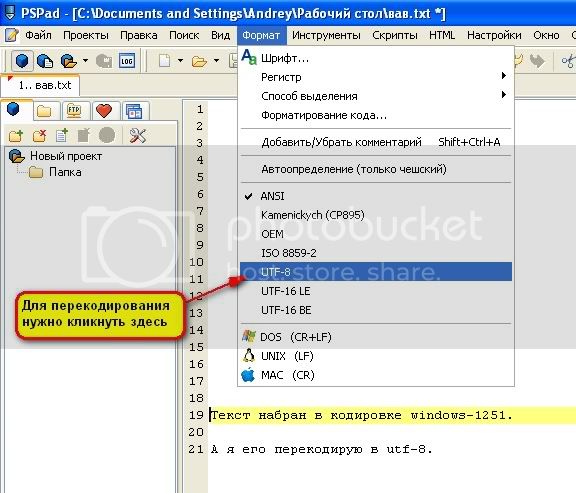
Пример перекодирования файла из кодировки windows-1251 в utf-8
Нужно кликнуть по требуемой кодировке в пункте меню Формат и кодировка сменится. После этого сохраняйте файл, он перекодирован, дело сделано.
Что касается Notepad++ все очень похоже на вышеописанную ситуацию. Только для работы с кодировками нужно использовать пункт меню Кодировки.
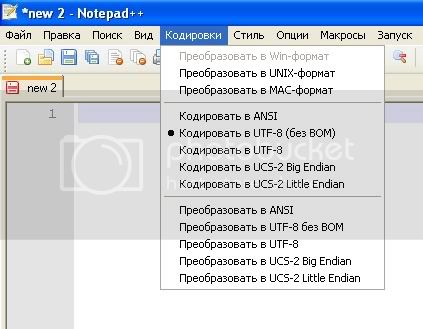 Вся разница заключается в том, что в случае Notepad++ появляются, специально разработанные для преобразования кодировок, пункты меню Преобразовать… (лишние на мой взгляд, в PSPad все проще и поэтому я им пользуюсь). Соответственно, именно по ним и нужно кликать при желании поменять кодировки у нашего HTML-файла.
Вся разница заключается в том, что в случае Notepad++ появляются, специально разработанные для преобразования кодировок, пункты меню Преобразовать… (лишние на мой взгляд, в PSPad все проще и поэтому я им пользуюсь). Соответственно, именно по ним и нужно кликать при желании поменять кодировки у нашего HTML-файла.
Кроме всего прочего, при сохранении в utf-8 у нас есть выбор: без BOM или с BOM. Нам, как веб-мастерам, нужно использовать кодировку UTF-8 (без BOM).
Вот что нам ответит Википедия на вопрос «что такое BOM»
Если прочитать приведенный текст 10 раз, почесать затылок, то становится понятно: для utf-8 BOM нам НЕ нужен. Кроме того, если сохранить файл с php-скриптом в кодировку utf-8 с BOM, то он не будет работать, потому что обработчик не поймет, что это за ерунда такая написана в начале файла-скрипта (я имею ввиду тот самый неразрывный пробел с нулевой шириной).
Так-так, осталось пристально взглянуть на Dreamweaver.
Создавая новый файл, обращайте внимание на то, в какой кодировке он будет создан. Для этого в окне создания нового документа File → New (Ctrl+N) воспользуйтесь кнопкой Preferences..
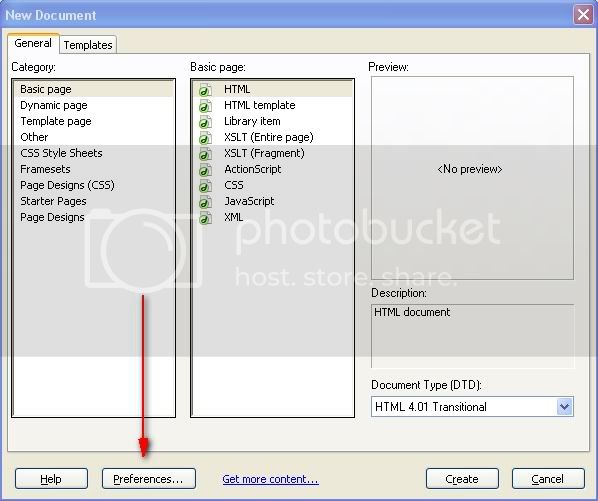
И посмотрите, что задано в качестве кодировки по умолчанию:
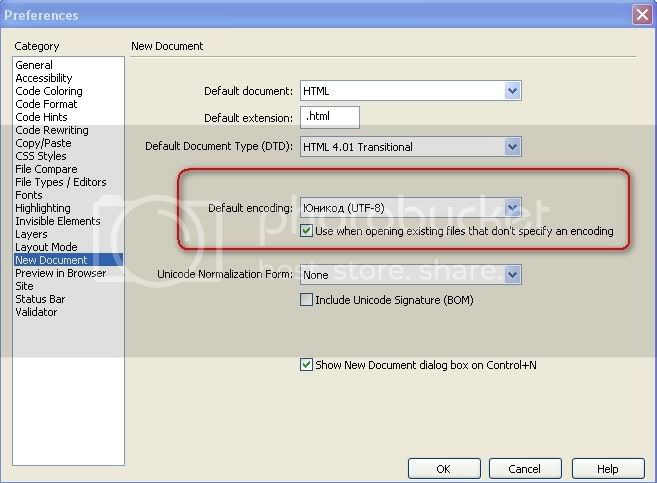
Кодировка создаваемого HTML-файла по умолчанию в Dreamweaver
Перекодировать открытый HTML-файл в Dreamweaver можно в диалоге Page Properties, который запускается из меню Modify → Page Properties (Ctrl + J).
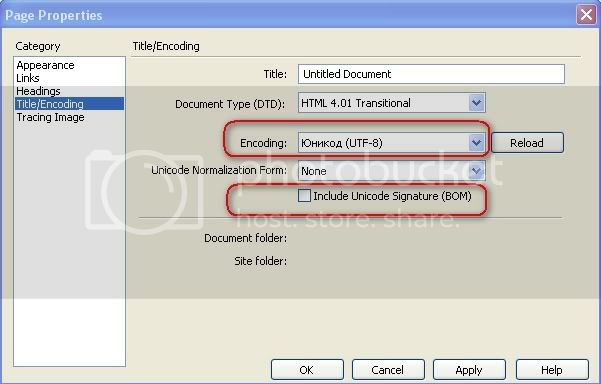
Выбирайте требуемую кодировку, нажимайте ОК и все, задача по перекодированию выполнена (а вот BOM все так же ненужен, не ставьте галку).
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
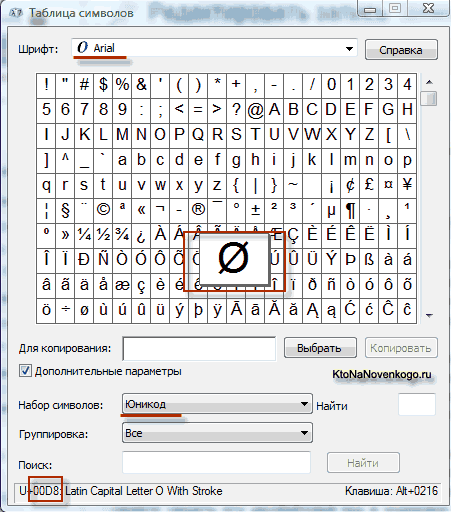
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
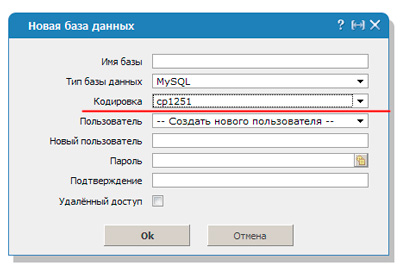
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.
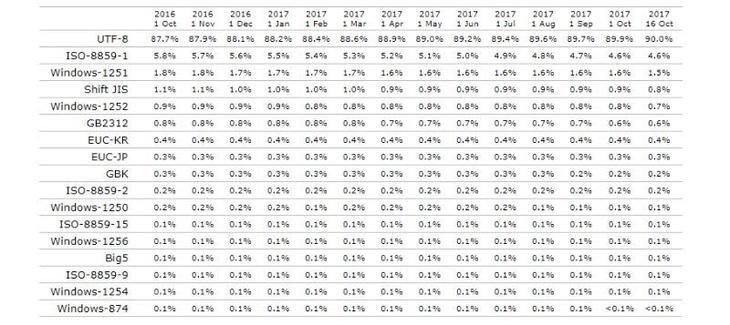
Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
Набор символов
В следующей таблице показана Windows-1251. Каждый символ отображается с его эквивалентом в Юникоде и его десятичным кодом.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ 0 | NUL 0000 | 0001 | 0002 | ETX 0003 | EOT 0004 | ENQ 0005 | ACK 0006 | BEL 0007 | 0008 | HT 0009 | LF 000A | ВТ 000Б | FF 000C | CR 000D | SO 000E | SI 000F |
| 1_ 16 | 0010 | 0011 | 0012 | 0013 | 0014 | NAK 0015 | SYN 0016 | ETB 0017 | CAN 0018 | 0019 | SUB 001A | 001B | FS 001C | GS 001D | RS 001E | США 001F |
| 2_ 32 | SP 0020 | ! 0021 | 0022 | # 0023 | 0024 долл. США | % 0025 | & 0026 | ‘ 0027 | ( 0028 | ) 0029 | * 002A | + 002B | , 002C | — 002D | . 002E | 002F |
| 3_ 48 | 0030 | 1 0031 | 2 0032 | 3 0033 | 4 0034 | 5 0035 | 6 0036 | 7 0037 | 8 0038 | 9 0039 | 003A | ; 003B | < 003C | = 003D | > 003E | ? 003F |
| 4_ 64 | @ 0040 | A 0041 | B 0042 | C 0043 | D 0044 | E 0045 | F 0046 | G 0047 | H 0048 | I 0049 | J 004A | K 004B | L 004C | M 004D | № 004E | O 004F |
| 5_ 80 | P 0050 | Q 0051 | R 0052 | S 0053 | Т 0054 | U 0055 | V 0056 | W 0057 | X 0058 | Y 0059 | Z 005A | 005B | \ 005C | 005D | ^ 005E | _ 005F |
| 6_ 96 | ` 0060 | а 0061 | b 0062 | c 0063 | d 0064 | e 0065 | f 0066 | г 0067 | h 0068 | я 0069 | j 006A | k 006B | l 006C | м 006D | № 006E | o 006F |
| 7_ 112 | p 0070 | q 0071 | r 0072 | с 0073 | t 0074 | u 0075 | v 0076 | w 0077 | х 0078 | y 0079 | z 007A | { 007B | | 007C | } 007D | ~ 007E | DEL 007F |
| 8_ 128 | Ђ 0402 | Ѓ 0403 | ‚ 201A | ѓ 0453 | „ 201E | … 2026 г. | † 2020 г. | ‡ 2021 г. | € 20AC | ‰ 2030 г. | Љ 0409 | ‹ 2039 | Њ 040A | Ќ 040C | Ћ 040B | Џ 040F |
| 9_ 144 | ђ 0452 | ‘ 2018 | ‘ 2019 | 201C | ” 201D | • 2022 г. | — 2013 г. | — 2014 г. | 2122 | љ 0459 | › 203A | њ 045A | ќ 045C | ћ 045B | џ 045F | |
| A_ 160 | NBSP 00A0 | Ў 040E | ў 045E | Ј 0408 | ¤ 00A4 | Ґ 0490 | ¦ 00A6 | § 00A7 | Ё 0401 | 00A9 | Є 0404 | 00AB | ¬ 00AC | SHY 00AD | 00AE | Ї 0407 |
| B_ 176 | ° 00B0 | ± 00B1 | І 0406 | і 0456 | ґ 0491 | µ 00B5 | ¶ 00B6 | · 00B7 | ё 0451 | № 2116 | є 0454 | 00BB | ј 0458 | Ѕ 0405 | ѕ 0455 | ї 0457 |
| C_ 192 | А 0410 | Б 0411 | В 0412 | Г 0413 | Д 0414 | Е 0415 | Ж 0416 | З 0417 | И 0418 | № 0419 | К 041A | Л 041B | М 041C | Н 041D | О 041E | П 041F |
| D_ 208 | Р 0420 | С 0421 | Т 0422 | У 0423 | Ф 0424 | Х 0425 | Ц 0426 | Ч 0427 | Ш 0428 | Щ 0429 | Ъ 042A | Ы 042B | Ь 042C | Э 042D | Ю 042E | Я 042F |
| E_ 224 | а 0430 | б 0431 | в 0432 | г 0433 | д 0434 | е 0435 | ж 0436 | з 0437 | и 0438 | 0439 | к 043A | л 043B | м 043C | н 043D | о 043E | п 043F |
| F_ 240 | р 0440 | с 0441 | т 0442 | у 0443 | ф 0444 | х 0445 | ц 0446 | ч 0447 | ш 0448 | щ 0449 | ъ 044A | ы 044B | ь 044C | э 044D | ю 044E | я 044F |
Письмо Число Пунктуация Символ Неопределенный
Кодировка windows 1251 в html
Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина « кодировка страницы ».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:

— между тегом и закрывающим его нужно прописать — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Кодировка windows 1251 в htaccess
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
В нем для установки кодировки следует прописать следующие строки:
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка
Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов
Кодировка символов в Windows PowerShell
В PowerShell 5,1 параметр Encoding поддерживает следующие значения:
- Использует кодировку ASCII (7-разрядных).
- Использует UTF-16 с обратным порядком байтов.
- Использует UTF-32 с обратным порядком байтов.
- Кодирует набор символов в последовательность байтов.
- Использует кодировку, соответствующую активной кодовой странице системы (обычно ANSI).
- Использует кодировку, соответствующую текущей кодовой странице OEM системы.
- аналогичен .
- Использует UTF-16 с прямым порядком байтов.
- аналогичен .
- Использует UTF-32 с прямым порядком байтов.
- Использует UTF-7.
- Использует UTF-8 (с BOM).
В общем случае Windows PowerShell по умолчанию использует кодировку Юникод UTF-16LE . Однако кодировка по умолчанию, используемая командлетами в Windows PowerShell, не согласуется.
Примечание
При использовании любой кодировки Юникода, за исключением , всегда создает спецификацию.
Для командлетов, записывающих выходные данные в файлы:
-
и операторы перенаправления и создают UTF-16LE, который, в свою очередь, отличается от и .
-
а также создавать файлы UTF-16LE.
-
Если целевой файл пуст или не существует, и Используйте кодировку. — это кодировка, определяемая кодовой страницей устаревшей версии ANSI на языке активного системы.
-
создает файлы, но использует другую кодировку при использовании параметра append (см. ниже).
-
по умолчанию создает файлы UTF-8 с BOM.
-
создает файл UTF-8 с кодировкой BOM.
-
по умолчанию использует кодировку.
-
создает файлы с помощью спецификации. При использовании параметра append кодировка может отличаться (см. ниже).
Для команд, которые добавляют к существующему файлу:
-
и оператор перенаправления не пытается сопоставить кодировку содержимого существующего целевого файла. Вместо этого они используют кодировку по умолчанию, если не используется параметр Encoding . При добавлении содержимого необходимо использовать исходную кодировку файлов.
-
При отсутствии явного параметра кодировки обнаруживает существующую кодировку и автоматически применяет ее к новому содержимому. Если имеющееся содержимое не имеет BOM, используется кодировка ANSI. Поведение аналогично в PowerShell Core (V6 и более поздних версиях), кроме кодировки по умолчанию — .
-
соответствует существующей кодировке, если целевой файл содержит СПЕЦИФИКАЦИю. В отсутствие спецификации используется Кодировка.
-
соответствует существующей кодировке файлов, включающих СПЕЦИФИКАЦИю. При отсутствии спецификации по умолчанию используется Кодировка. Такая кодировка может привести к утере данных или повреждению символов, если данные в записи содержат многобайтовые символы.
Для командлетов, считывающих строковые данные в отсутствие спецификации:
-
и использует кодировку ANSI. ANSI также используется механизмом PowerShell при чтении исходного кода из файлов.
-
, и предполагают отсутствие спецификации.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Казахский вариант
Измененная версия Windows-1251 была стандартизирована в Казахстане как казахстанский стандарт STRK1048 и известна под этикеткой . Он отличается в строках, показанных ниже:
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8_ 128 | Ђ 0402 | Ѓ 0403 | ‚ 201A | ѓ 0453 | „ 201E | … 2026 г. | † 2020 г. | ‡ 2021 г. | € 20AC | ‰ 2030 г. | Љ 0409 | ‹ 2039 | Њ 040A | Қ 049A | Һ 04BA | Џ 040F |
| 9_ 144 | ђ 0452 | ‘ 2018 | ‘ 2019 | 201C | ” 201D | • 2022 г. | — 2013 г. | — 2014 г. | 2122 | љ 0459 | › 203A | њ 045A | қ 049B | һ 04BB | џ 045F | |
| A_ 160 | NBSP 00A0 | Ұ 04B0 | ұ 04B1 | Ә 04D8 | ¤ 00A4 | Ө 04E8 | ¦ 00A6 | § 00A7 | Ё 0401 | 00A9 | 0492 Ғ | 00AB | ¬ 00AC | SHY 00AD | 00AE | Ү 04AE |
| B_ 176 | ° 00B0 | ± 00B1 | І 0406 | і 0456 | ө 04E9 | µ 00B5 | ¶ 00B6 | · 00B7 | ё 0451 | № 2116 | 0493 ғ | 00BB | ә 04D9 | Ң 04A2 | ң 04A3 | ү 04AF |
Консоль Внедренца v.3.6.2
Идея данной обработки заключается в создании простого, функционального и универсального инструментария для внедренцев и программистов 1С, который будет работать как в толстом клиенте на обычных и на управляемых формах, так и в тонком клиенте. Интерфейс и логика работы максимально идентичны у обычных форм и управляемых. Инструментарий включает в себя: Консоль кода, Консоль запросов, Консоль отчетов (СКД), Универсальную обработку объектов, Средства для работы с таблицами базы данных 1С, Редактирование регистров сведений базы, Инструмент по работе с табличными документами — загрузка данных из табличного документа.
1 стартмани
Комментарии
Добрый день! Необходимо конвертировать текст из ASCII (отрезанный старший бит) в Windows-1251. Каким образом можно модифицировать макрос для решения задачи?
Добрый день. Парни, есть такая проблема, сам я из Казахстана, юзер пишет текст в ворде, например слово «СЛОВО», где буква С была написана на англ.языке, а все остальное слово на русском, или есть такие слова где русский язык и казахский (с казахской клавиатуры). Теперь при проверке на плагиат выходит ошибка кодировки, программа не понимает таких слов из двух или более языков, посоветуйте пожалуйста выход из такой ситуации, слышал что можно с помощью макросов, вот только с макросами не дружу, но в целом с понятия имею.
Огромное СПАСИБО за такой функционал! Полдня истратил, пока нашел, как же из Excel перевести данные в UTF-8. И тут такой подарок! Это просто супер!
Здравствуйте, подскажите как пересохранить xls файл в формат csv с кодировкой utf8 без BOM разделитель ; с именем исходного файла
Алексей, ну есть же в конце статьи отдельная функция для вашего случая. Вызывается так:
Скажите пожалуйста, хотелось бы на выходе получить файл в кодировке UTF-8 без BOM вызываю так: ChangeFileCharset filename, «UTF-8», «Windows-1251» все нормально, но файл получается UTF-8 а хотелось бы UTF-8 без BOM Это возможно? Если да, то как указать во втором параметре вызова функции?
Здравствуйте, Павел В общем случае, кодировку txt файла никак не угадать (не проверить) Можно лишь попробовать угадать, анализируя первые байты текста (правда, верно угадать можно с вероятностью, очень близкой к 100%)
Изменить кодировку без перезаписи файла — никак. Смена кодировки текстового файла — это изменение байтового представления этого текста (после перекодировки, файл может увеличиться или уменьшаться в размере в 2 раза)
Готовый макрос предложить не могу (ни разу подобное не делал, и кода немало получится)
Варианты решения проблемы: 1) ручная обработка, при помощи текстового редактора Notepad++ В нём можно открыть сразу кучу файлов, а потом, переключаясь между ними, смотреть текущую кодировку, и, при необходимости, перекодировать одним нажатием кнопки (см. меню Кодировки в Notepad++)
У меня почему-то при кодировании анси в уникод, не прокатил параметр «utf-8», а получилось только с «Unicode».
Источник
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8