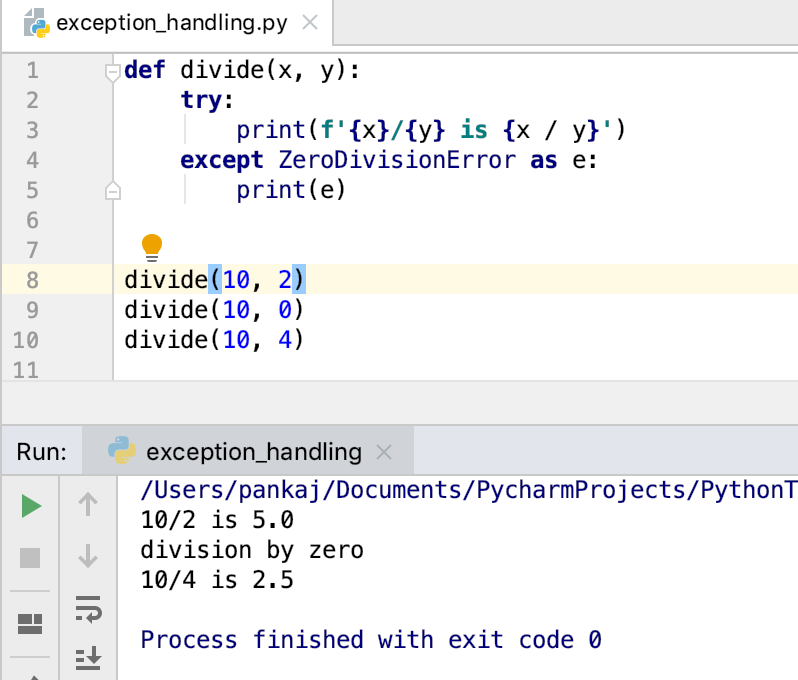
Сравнение списков в python
Содержание:
- Как создаются списки в Python
- Методы списков
- Python Подсчитывает уникальные значения в списке обычным методом грубой силы
- Как получить доступ к элементам из списка?
- Повторите список в Python С Помощью Модуля Numpy
- Python list function
- Как лучше выбирать элементы из списка?
- Вопрос 9. Чем список отличается от других структур?
- Спискок — это последовательность
- Вопрос 10. Как объединить два списка в список кортежей?
- Python reversing list elements
- Прохождение по списку
Как создаются списки в Python
Существует несколько способов создания списков в Python. Чтобы лучше понять компромиссы связанные с использованием list comprehension, давайте сначала рассмотрим способы создания списков с помощью этих подходов.
Использование цикла for
Наиболее распространенным типом цикла является цикл for. Использование цикла for можно разбить на три этапа:
- Создание пустого списка.
- Цикл по итерируемому объекту или диапазону элементов range.
- Добавляем каждый элемент в конец списка.
Допустим на надо создать список squares, то эти шаги будут в трех строках кода:
>>> squares = [] >>> for i in range(10): ... squares.append(i * i) >>> squares
Здесь мы создаем пустой список squares. Затем используем цикл for для перебора range(10). Наконец умножаем каждое число отдельно и добавляете результат в конец списка.
Использование объектов map()
map() предоставляет альтернативный подход, основанный на функциональном программировании. Мы передаем функцию и итерируемый объект (iterable), а map() создаст объект. Этот объект содержит выходные данные, которые мы получаем при запуске каждого итерируемого элемента через предоставленную функцию.
Немного запутано, поэтому в качестве примера рассмотрим ситуацию, в которой необходимо рассчитать цену после вычета налога для списка транзакций:
>>> txns = >>> TAX_RATE = .08 >>> def get_price_with_tax(txn): ... return txn * (1 + TAX_RATE) >>> final_prices = map(get_price_with_tax, txns) >>> list(final_prices)
Здесь у вас есть итерируемый объект txns (в нашем случае простой список) и функция get_price_with_tax(). Мы передаем оба этих аргумента в map() и сохраняем полученный объект в final_prices. Мы можем легко преобразовать этот объект map в список, используя list().
Использование List Comprehensions
List comprehensions — это третий способ составления списков. При таком элегантном подходе мы можем переписать цикл for из первого примера всего в одну строку кода:
>>> squares = >>> squares
Вместо того, чтобы создавать пустой список и добавлять каждый элемент в конец, мы просто определяем список и его содержимое одновременно, следуя этому формату:
new_list =
Каждое представление списков в Python включает три элемента:
- какое либо вычисление, вызов метода или любое другое допустимое выражение, которое возвращает значение. В приведенном выше примере выражение i * i является квадратом значения члена.
- является объектом или значением в списке или итерируемым объекте (iterable). В приведенном выше примере значением элемента является i.
- список, множество, последовательность, генератор или любой другой объект, который может возвращать свои элементы по одному. В приведенном выше примере iterable является range(10).
Поскольку требования к expression (выражению) настолько гибки, представление списков хорошо работает во многих местах, где вы будете использовать map(). Вы так же можем переписать пример ценообразования:
>>> txns = >>> TAX_RATE = .08 >>> def get_price_with_tax(txn): ... return txn * (1 + TAX_RATE) >>> final_prices = >>> final_prices
Единственное различие между этой реализацией и map() состоит в том, что list comprehension возвращает список, а не объект map.
Преимущества использования представления списков
Представление списков часто описываются как более Pythonic, чем циклы или map(). Но вместо того, чтобы слепо принимать эту оценку, стоит понять преимущества использования list comprehension по сравнению с альтернативами. Позже вы узнаете о нескольких сценариях, в которых альтернативы являются лучшим выбором.
Одним из основных преимуществ использования является то, что это единственный инструмент, который вы можете использовать в самых разных ситуациях. В дополнение к созданию стандартного списка, списки могут также использоваться для отображения и фильтрации. Вам не нужно использовать разные подходы для каждого сценария.
Это основная причина, почему list comprehension считаются Pythonic, поскольку Python включает в себя простые и мощные инструменты, которые вы можете использовать в самых разных ситуациях. Дополнительным преимуществом является то, что всякий раз, когда вы используете представления списков, вам не нужно запоминать правильный порядок аргументов, как при вызове map().
List comprehensions также более декларативны, чем циклы, что означает, что их легче читать и понимать. Циклы требуют, чтобы вы сосредоточились на создание списока. Вы должны вручную создать пустой список, зациклить элементы и добавить каждый из них в конец списка. Используя представления списков, вы можете вместо этого сосредоточиться на том, что хотите добавить в список, и положиться, на то что Python позаботится о том, как происходит построение списка.
Методы списков
len()
Метод возвращает длину объекта (списка, строки, кортежа или словаря).
принимает один аргумент, который может быть или последовательностью (например, строка, байты, кортеж, список, диапазон), или коллекцией (например, словарь, множество, frozenset).
list1 = # список
print(len(list1)) # в списке 3 элемента, в выводе команды будет "3"
str1 = 'basketball' # строка
print(len(str1)) # в строке 9 букв, в выводе команды будет "9"
tuple1 = (2, 3, 4, 5) # кортеж
print(len(tuple1)) # в кортеже 4 элемента, в выводе команды будет "4"
dict1 = {'name': 'John', 'age': 4, 'score': 45} # словарь
print(len(dict1)) # в словаре 3 пары ключ-значение, в выводе команды будет "3"
index()
возвращает индекс элемента. Сам элемент передается методу в качестве аргумента. Возвращается индекс первого вхождения этого элемента (т. е., если в списке два одинаковых элемента, вернется индекс первого).
numbers =
words =
print(numbers.index(9)) # 4
print(numbers.index(2)) # 1
print(words.index("I")) # 0
print(words.index("JavaScript")) # возвращает ValueError, поскольку 'JavaScript' в списке 'words' нет
Первый результат очевиден. Второй и
третий output демонстрируют возврат индекса
именно первого вхождения.
Цифра «2» встречается в списке дважды,
первое ее вхождение имеет индекс 1,
второе — 2. Метод index() возвращает индекс
1.
Аналогично возвращается индекс 0 для элемента «I».
Если элемент, переданный в качестве аргумента, вообще не встречается в списке, вернется ValueError. Так получилось с попыткой выяснить индекс «JavaScript» в списке .
Опциональные аргументы
Чтобы ограничить поиск элемента
конкретной подпоследовательностью,
можно использовать опциональные
аргументы.
words =
print(words.index("am", 2, 5)) # 4
Метод index() будет искать элемент «am» в диапазоне от элемента с индексом 2 (включительно) до элемента с индексом 5 (этот последний элемент не входит в диапазон).
При этом возвращаемый индекс — индекс
элемента в целом списке, а не в указанном
диапазоне.
pop()
Метод удаляет и возвращает последний элемент списка.
Этому методу можно передавать в качестве параметра индекс элемента, который вы хотите удалить (это опционально). Если конкретный индекс не указан, метод удаляет и возвращает последний элемент списка.
Если в списке нет указанного вами индекса, метод выбросит exception .
cities = print "City popped is: ", cities.pop() # City popped is: San Francisco print "City at index 2 is : ", cities.pop(2) # City at index 2 is: San Antonio
Базовый функционал стека
Для реализации базового функционала
стека в программах на Python часто
используется связка метода pop() и метода
append():
stack = []
for i in range(5):
stack.append(i)
while len(stack):
print(stack.pop())
Python Подсчитывает уникальные значения в списке обычным методом грубой силы
Мы называем этот метод подходом грубой силы . Этот метод не так эффективен, так как в нем больше времени и больше пространства. Этот подход будет принимать пустой список и переменную count, которая будет установлена в 0. мы пройдем от начала до конца и проверим, нет ли этого значения в пустом списке. Затем мы добавим его и увеличим переменную count на 1. Если его нет в пустом списке, то мы не будем его считать, не будем добавлять в пустой список.
# take an input list as lst
lst =
print("Input list : ",lst)
#Empty list
lst1 = []
count = 0
# traverse the array
for i in lst:
if i not in lst1:
count = count + 1
lst1.append(i)
# printing the output
print("Output list : ",lst1)
print("No. of unique items are:", count)
Выход:
Input list : Output list : No. of unique items are: 6
Объяснение:
Здесь, во-первых, мы взяли входной список и напечатали входной список. Во-вторых, мы взяли пустой список и переменную count, которая установлена в 0. В-третьих, мы прошли список с самого начала и проверили, нет ли значения в пустом списке или нет. Если значение отсутствует в пустом списке, мы увеличиваем значение счетчика на 1 и добавляем это значение в пустой список. Если мы обнаруживаем, что элементы присутствуют в списке, мы не добавляем их в пустой список и не увеличиваем значение счетчика на 1. Наконец, мы напечатали пустой список, который теперь содержит уникальные значения и количество списка. Таким образом, мы можем видеть все уникальные элементы в списке.
Как получить доступ к элементам из списка?
Существуют различные способы доступа к элементам списка.
Доступ по индексу
блок 1
Для доступа к элементу списка можно использовать оператор индекса []. Индекс начинается с 0. Итак, список из 5 элементов будет иметь индексы от 0 до 4.
Попытка получить доступ к элементу, который не существует, вызовет ошибку IndexError. Индекс должен быть целым числом. Нельзя использовать float или другие типы данных в качестве индекса, это приведет к ошибке TypeError.
Доступ к вложенному списку осуществляется с помощью дополнительных индексов.
my_list = # Вывод первого элемента: p print(my_list) # Вывод третьего элемента: o print(my_list) # Вывод последнего (пятого) элемента: e print(my_list) # Ошибка, индексом может быть только целое число # my_list # Пример вложенного списка n_list = ] # Индексы вложенных списков # Вывод второго символа первого элемента списка: a print(n_list) # вывод четвертого элемента второго вложенного списка: 5 print(n_list)
Отрицательные индексы списка
Python допускает отрицательную индексацию для элементов списка. Индекс -1 выведет последний элемент, -2 — второй элемент с конца и т.д.
my_list = # Вывод последнего элемента: e print(my_list) # Вывод последнего элемента с конца (первого): p print(my_list)
Срезы списков в Python
Вы можете получить доступ к ряду элементов в списке, используя оператор среза (двоеточие).
my_list = # Элементы с 3го по 5й print(my_list) # Элементы с начала до 4го print(my_list) # Элементы с 6го до последнего print(my_list) # Элементы с первого до последнего print(my_list)
Повторите список в Python С Помощью Модуля Numpy
Третий способ перебора списка в Python – это использование модуля Numpy. Для достижения нашей цели с помощью этого метода нам нужны два метода numpy, которые упоминаются ниже:
- numpy.nditer()
- numpy.arange()
Iterator object nditer предоставляет множество гибких способов итерации по всему списку с помощью модуля numpy. Функция href=”http://numpy.org/doc/stable/reference/generated/numpy.nditer.html”>nditer() – это вспомогательная функция, которая может использоваться от очень простых до очень продвинутых итераций. Это упрощает некоторые фундаментальные проблемы, с которыми мы сталкиваемся в итерации. href=”http://numpy.org/doc/stable/reference/generated/numpy.nditer.html”>nditer() – это вспомогательная функция, которая может использоваться от очень простых до очень продвинутых итераций. Это упрощает некоторые фундаментальные проблемы, с которыми мы сталкиваемся в итерации.
Нам также нужна другая функция для перебора списка в Python с помощью numpy, которая является numpy.arrange().numpy.arange возвращает равномерно распределенные значения в пределах заданного интервала. Значения генерируются в пределах полуоткрытого интервала [start, stop) (другими словами, интервала, включающего start, но исключающего stop).
Синтаксис:
Синтаксис numpy.nditer()
Синтаксис numpy.arrange()
- start: Параметр start используется для предоставления начального значения массива.
- stop: Этот параметр используется для предоставления конечного значения массива.
- шаг: Он обеспечивает разницу между каждым целым числом массива и генерируемой последовательностью.
Объяснение
В приведенном выше примере 1 программа np.arange(10) создает последовательность целых чисел от 0 до 9 и сохраняет ее в переменной x. После этого мы должны запустить цикл for, и, используя этот цикл for и np.nditer(x), мы будем перебирать каждый элемент списка один за другим.
Пример 2:
В этом примере мы будем итерировать 2d-массив с помощью модуля numpy. Для достижения нашей цели нам здесь нужны три функции.
- numpy.arange()
- numpy.reshape()
- numpy.nditer()
import numpy as np .arange(16) .reshape(4, 4) for x in np.nditer(a): print(x)
Объяснение:
Большая часть этого примера похожа на наш первый пример, за исключением того, что мы добавили дополнительную функцию numpy.reshape(). Функция numpy.reshape() обычно используется для придания формы нашему массиву или списку. В основном на непрофессиональном языке он преобразует размеры массива-как в этом примере мы использовали функцию reshape(), чтобы сделать массив numpy 2D-массивом.
Python list function
The function creates a list from an iterable
object. An iterable may be either a sequence, a container that
supports iteration, or an iterator object. If no parameter is
specified, a new empty list is created.
list_fun.py
#!/usr/bin/env python
# list_fun.py
a = []
b = list()
print(a == b)
print(list((1, 2, 3)))
print(list("ZetCode"))
print(list())
In the example, we create an empty list, a list from a tuple,
a string, and another list.
a = [] b = list()
These are two ways to create an empty list.
print(a == b)
The line prints . This confirms that and
are equal.
print(list((1, 2, 3)))
We create a list from a Python tuple.
print(list("ZetCode"))
This line produces a list from a string.
print(list())
Finally, we create a copy of a list of strings.
$ ./list_fun.py True
This is example output.
Как лучше выбирать элементы из списка?
Если вы хотите продуктивно работать со списками, то должны уметь получать доступ к данным, хранящимся в них.
Обычно мы получаем доступ к элементам списков, чтобы изменять определенные значения, обновлять или удалять их, или выполнять какие-либо другие операции с ними. Мы получаем доступ к элементам списков и, собственно, ко всем другим типам последовательностей, при помощи оператора индекса . Внутри него мы помещаем целое число.
# Выбираем первый элемент списка oneZooAnimal = biggerZoo # Выводим на экран переменную `oneZooAnimal` print(oneZooAnimal)
Запустите данный код и убедитесь, что вы получите первый элемент списка, сохраненного в переменную . Это может быть поначалу несколько непривычно, но нумерация начинается с числа , а не .
Как получить последний элемент списка?
Ответ на этот вопрос является дополнением к объяснению в предыдущем разделе.
Попробуйте ввести отрицательное значение, например, или , в оператор индекса, чтобы получить последние элементы нашего списка !
# Вставляем -1 monkeys = biggerZoo print(monkeys) # А теперь -2 zebra = biggerZoo print(zebra)
Не правда ли, не слишком сложно?
Что означает ошибка «Index Out Of Range»?
Эта ошибка одна из тех, которые вы будете видеть достаточно часто, особенно если вы новичок в программировании.
Лучший способ понять эту ошибку — попробовать ее получить самостоятельно.
Возьмите ваш список и передайте в оператор индекса либо очень маленькое отрицательное число, либо очень большое положительное число.
Как видите, вы можете получить ошибку «Индекс вне диапазона» в случаях, когда вы передаете в оператор индекса целочисленное значение, не попадающее в диапазон значений индекса списка. Это означает, что вы присваиваете значение или ссылаетесь на (пока) несуществующий индекс.
Срезы в списках
Если вы новичок в программировании и в Python, этот вопрос может показаться одним из наиболее запутанных.
Обычно нотация срезов используется, когда мы хотим выбрать более одного элемента списка одновременно. Как и при выборе одного элемента из списка, мы используем двойные скобки. Отличие же состоит в том, что теперь мы еще используем внутри скобок двоеточие. Это выглядит следующим образом:
# Используем нотацию срезов someZooAnimals = biggerZoo # Выводим на экран то, что мы выбрали print(someZooAnimals) # Теперь поменяем местами 2 и двоеточие otherZooAnimals = biggerZoo # Выводим на экран полученный результат print(otherZooAnimals)
Вы можете видеть, что в первом случае мы выводим на экран список начиная с его элемента , который имеет индекс . Иными словами, мы начинаем с индекса и идем до конца списка, так как другой индекс не указан.
Что же происходит во втором случае, когда мы поменяли местами индекс и двоеточие? Вы можете видеть, что мы получаем список из двух элементов, и . В данном случае мы стартуем с индекса и доходим до индекса (не включая его). Как вы можете видеть, результат не будет включать элемент .
В общем, подводя итоги:
# элементы берутся от start до end (но элемент под номером end не входит в диапазон!) a # элементы берутся начиная со start и до конца a # элементы берутся с начала до end (но элемент под номером end не входит в диапазон!) a
Совет: передавая в оператор индекса только двоеточие, мы создаем копию списка.
В дополнение к простой нотации срезов, мы еще можем задать значение шага, с которым будут выбираться значения. В обобщенном виде нотация будет иметь следующий вид:
# Начиная со start, не доходя до end, с шагом step a
Так что же по сути дает значение шага?
Ну, это позволяет вам буквально шагать по списку и выбирать только те элементы, которые включает в себя значение вашего шага. Вот пример:
Обратите внимание, что если вы не указали какое-либо значение шага, оно будет просто установлено в значение . При проходе по списку ни один элемент пропущен не будет
Также всегда помните, что ваш результат не включает индекс конечного значения, который вы указали в записи среза!
Как случайным образом выбрать элемент из списка?
Для этого мы используем пакет .
# Импортируем функцию `choice` из библиотеки `random` from random import choice # Создадим список из первых четырех букв алфавита list = # Выведем на экран случайный элемент списка print(choice(list))
Если мы хотим выбрать случайный элемент из списка по индексу, то можем использовать метод из той же библиотеки .
# Импортируем функцию `randrange` из библиотеки `random` from random import randrange # Создадим список из первых четырех букв алфавита randomLetters = # Выбираем случайный индекс нашего списка randomIndex = randrange(0,len(randomLetters)) # Выводим случайный элемент на экран print(randomLetters)
Совет: обратите внимание на библиотеку , она может вам пригодиться во многих случаях при программировании на Python
Вопрос 9. Чем список отличается от других структур?
Сложность: (> ⌒ <)
Такие вопросы надо отбивать особенно чётко. Если спрашивающий не услышит конкретные ключевые слова, его подозрительность повысится, а ваши шансы, наоборот, снизятся.
Список и кортеж (tuple)
Список можно менять после создания (например, с помощью функции append()), а кортеж нет: он защищает данные от изменений после создания. По этой причине кортеж можно использовать в качестве ключа в словарях, а список нельзя. Кроме того, кортеж обрабатывается интерпретатором Python чуть быстрее.
Список и множество (set)
Список упорядочен: каждый элемент списка имеет индекс, а элемент множества — нет. Список может содержать одинаковые значения, а во множестве каждое значение уникально. Проверка, принадлежит ли элемент множеству, выполняется быстрее, чем такая же проверка элемента списка.
Список и словарь (dictionary)
Словарь состоит из пар «ключ-значение», а список может состоять и из одиночных элементов, и из пар, и из троек — если элементами будут другие списки или кортежи. Ключи у словаря должны быть уникальными и иметь неизменяемый тип, у списка таких ограничений нет. Поиск по словарю быстрее, чем по списку.
Список и массив (array)
Для использования массива нужно вызывать библиотеку array, а списки встроены в Python. В массиве могут содержаться элементы только одного типа. Массив не может содержать другие массивы или списки. Массив занимает меньше памяти и поэтому быстрее, чем одномерный список.
Спискок — это последовательность
Выше было сказано, что если в качестве аргумента функции передать любую последовательность языка Python, то она будет преобразована в список. Последовательностями считаются любые типы данных, которые поддерживают:
- оператор извлечения срезов — ;
- оператор вхождения ;
- возможность определения длины (размера) с помощью функции ;
- возможность выполнять итерации по элементам;
Списки считаются последовательностями поскольку удовлетворяют всем вышеперечисленным требованиям. Функция возвращает длину (размер) списка:
Но будьте внимательны, не учитывает длину вложенных элементов, например, список состоит из трех элементов: числа, строки и списка.
Извлекать данные можно с помощью оператора :
Проверить вхождение какого-нибудь элемента в список можно с помощью оператора :
Кстати, если вам нужно, наоборот, убедиться в том, что какой-нибудь элемент не содержится внутри списка, то можно воспользоваться конструкцией :
Возможность выполнения итераций по элементам так же возможна благодаря конструкции
Любопытно, то что благодаря механизму распаковывания последовательностей возможно выполнение итераций по вложенным спискам одинаковой длины:
Вопрос 10. Как объединить два списка в список кортежей?
Сложность: (> ⌒ <)
Для объединения двух списков в список кортежей можно использовать функцию zip, причём не только для двух, но и для трёх и более списков. Это полезно для формирования, например, матриц из векторов.
В первых двух строчках мы создали два списка, которые надо объединить. В третьей с помощью конструкции, похожей на двойной генератор, создали список, состоящий из кортежей вида (k, v), где k и v берутся из двух наших списков с помощью функции zip(). К слову, она не зря носит такое название: в переводе zip означает «застёжка-молния», и эта функция как бы сшивает два списка в один.
Python reversing list elements
We can reverse elements in a list in a few ways in Python.
Reversing elements should not be confused with sorting in a
reverse way.
reversing.py
#!/usr/bin/env python
# reversing.py
a1 =
a2 =
a3 =
a1.reverse()
print(a1)
it = reversed(a2)
r = list()
for e in it:
r.append(e)
print(r)
print(a3)
In the example, we have three identical string lists.
We reverse the elements in three different ways.
a1.reverse()
The first way is to use the method.
it = reversed(a2)
r = list()
for e in it:
r.append(e)
The function returns a reverse iterator.
We use the iterator in a for loop and create a new reversed list.
print(a3)
The third way is to reverse the list using the slice syntax, where the
step parameter is set to -1.
$ ./reversing.py
All the three lists were reversed OK.
Прохождение по списку
enumerate(iterable )
Возвращает генератор, отдающий пары счётчик(индекс)-элемент для указанного итерируемого объекта.
Параметры:
— последовательность, итератор или объекты, поддерживающие итерирование.
– значение, с которого начинается отсчет. Необязательный аргумент, по умолчанию равен нулю.
Возвращаемое значение:
enumerate object — генератор, отдающий пары счётчик(индекс)-элемент для указанного итерируемого объекта.
Примечание:
Вы можете преобразовать enumerate object в список или кортеж, используя функции и соответственно.
Примеры:
Пример 1: Работа с .
grocery = enumerateGrocery = enumerate(grocery) # <class 'enumerate'> print(type(enumerateGrocery)) # print(list(enumerateGrocery)) enumerateGrocery = enumerate(grocery, 10) # print(list(enumerateGrocery))
Пример 2: Прохождение по enumerate object.
grocery =
for item in enumerate(grocery):
print(item)
print('\n')
for count, item in enumerate(grocery):
print(count, item)
print('\n')
# изменение значения start
for count, item in enumerate(grocery, 100):
print(count, item)
Результат:(0, ‘bread’)(1, ‘milk’)(2, ‘butter’)
0 bread1 milk2 butter
100 bread101 milk102 butter