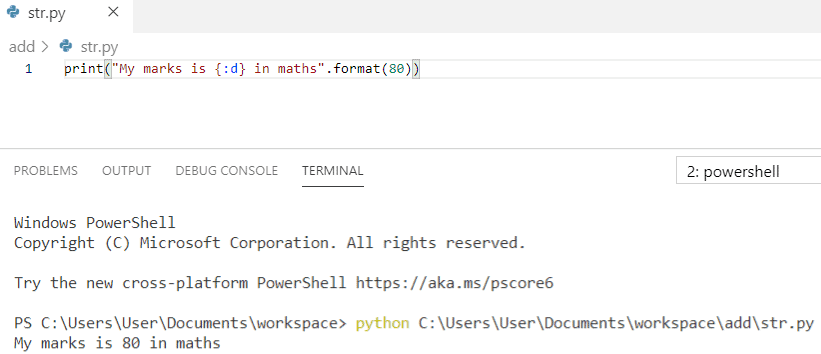
Списки (list). функции и методы списков
Содержание:
- Реверсив массив модуля массива в Python
- Как создаются списки в Python
- Что такое Двусвязный список в Python?
- Строковый тип данных в Python
- Как лучше выбирать элементы из списка?
- Массивы в Python
- 1. Определения и классификация
- Обратитесь в массив списка в Python
- Массив нарезки
- Если можно менять исходные списки
- Словарные типы данных в Python
- Создание и заполнение
Реверсив массив модуля массива в Python
Несмотря на то, что Python не поддерживает массивы, мы можем использовать Модуль массива Для создания массивных объектов различных типов данных. Хотя этот модуль обеспечивает много ограничений, когда речь идет о типе данных массива, он широко используется для работы с структурами данных массива в Python.
Теперь давайте посмотрим, как мы можем поместить массив в Python, созданный с модулем массива.
1. Использование обратного () метода
Подобно спискам, Способ также может быть использован для непосредственного изменения массива в Python модуля массива. Он меняет массив в своем первоначальном месте, поэтому не требует дополнительного места для хранения результатов.
import array
#The original array
new_arr=array.array('i',)
print("Original Array is :",new_arr)
#reversing using reverse()
new_arr.reverse()
print("Reversed Array:",new_arr)
Выход :
Original Array is : array('i', )
Resultant new reversed Array: array('i', )
2. Использование обратного () метода
Опять же Способ при прохождении с массивом, возвращает утечку с элементами в обратном порядке. Посмотрите на пример ниже, он показывает, как мы можем поместить массив, используя этот метод.
import array
#The original array
new_arr=array.array('i',)
print("Original Array is :",new_arr)
#reversing using reversed()
res_arr=array.array('i',reversed(new_arr))
print("Resultant Reversed Array:",res_arr)
Выход :
Original Array is : array('i', )
Resultant Reversed Array: array('i', )
Как создаются списки в Python
Существует несколько способов создания списков в Python. Чтобы лучше понять компромиссы связанные с использованием list comprehension, давайте сначала рассмотрим способы создания списков с помощью этих подходов.
Использование цикла for
Наиболее распространенным типом цикла является цикл for. Использование цикла for можно разбить на три этапа:
- Создание пустого списка.
- Цикл по итерируемому объекту или диапазону элементов range.
- Добавляем каждый элемент в конец списка.
Допустим на надо создать список squares, то эти шаги будут в трех строках кода:
>>> squares = [] >>> for i in range(10): ... squares.append(i * i) >>> squares
Здесь мы создаем пустой список squares. Затем используем цикл for для перебора range(10). Наконец умножаем каждое число отдельно и добавляете результат в конец списка.
Использование объектов map()
map() предоставляет альтернативный подход, основанный на функциональном программировании. Мы передаем функцию и итерируемый объект (iterable), а map() создаст объект. Этот объект содержит выходные данные, которые мы получаем при запуске каждого итерируемого элемента через предоставленную функцию.
Немного запутано, поэтому в качестве примера рассмотрим ситуацию, в которой необходимо рассчитать цену после вычета налога для списка транзакций:
>>> txns = >>> TAX_RATE = .08 >>> def get_price_with_tax(txn): ... return txn * (1 + TAX_RATE) >>> final_prices = map(get_price_with_tax, txns) >>> list(final_prices)
Здесь у вас есть итерируемый объект txns (в нашем случае простой список) и функция get_price_with_tax(). Мы передаем оба этих аргумента в map() и сохраняем полученный объект в final_prices. Мы можем легко преобразовать этот объект map в список, используя list().
Использование List Comprehensions
List comprehensions — это третий способ составления списков. При таком элегантном подходе мы можем переписать цикл for из первого примера всего в одну строку кода:
>>> squares = >>> squares
Вместо того, чтобы создавать пустой список и добавлять каждый элемент в конец, мы просто определяем список и его содержимое одновременно, следуя этому формату:
new_list =
Каждое представление списков в Python включает три элемента:
- какое либо вычисление, вызов метода или любое другое допустимое выражение, которое возвращает значение. В приведенном выше примере выражение i * i является квадратом значения члена.
- является объектом или значением в списке или итерируемым объекте (iterable). В приведенном выше примере значением элемента является i.
- список, множество, последовательность, генератор или любой другой объект, который может возвращать свои элементы по одному. В приведенном выше примере iterable является range(10).
Поскольку требования к expression (выражению) настолько гибки, представление списков хорошо работает во многих местах, где вы будете использовать map(). Вы так же можем переписать пример ценообразования:
>>> txns = >>> TAX_RATE = .08 >>> def get_price_with_tax(txn): ... return txn * (1 + TAX_RATE) >>> final_prices = >>> final_prices
Единственное различие между этой реализацией и map() состоит в том, что list comprehension возвращает список, а не объект map.
Преимущества использования представления списков
Представление списков часто описываются как более Pythonic, чем циклы или map(). Но вместо того, чтобы слепо принимать эту оценку, стоит понять преимущества использования list comprehension по сравнению с альтернативами. Позже вы узнаете о нескольких сценариях, в которых альтернативы являются лучшим выбором.
Одним из основных преимуществ использования является то, что это единственный инструмент, который вы можете использовать в самых разных ситуациях. В дополнение к созданию стандартного списка, списки могут также использоваться для отображения и фильтрации. Вам не нужно использовать разные подходы для каждого сценария.
Это основная причина, почему list comprehension считаются Pythonic, поскольку Python включает в себя простые и мощные инструменты, которые вы можете использовать в самых разных ситуациях. Дополнительным преимуществом является то, что всякий раз, когда вы используете представления списков, вам не нужно запоминать правильный порядок аргументов, как при вызове map().
List comprehensions также более декларативны, чем циклы, что означает, что их легче читать и понимать. Циклы требуют, чтобы вы сосредоточились на создание списока. Вы должны вручную создать пустой список, зациклить элементы и добавить каждый из них в конец списка. Используя представления списков, вы можете вместо этого сосредоточиться на том, что хотите добавить в список, и положиться, на то что Python позаботится о том, как происходит построение списка.
Что такое Двусвязный список в Python?
Двусвязный список в Python-это связанная структура данных с набором последовательно связанных узлов. Каждый узел имеет три поля – два поля связи, которые являются ссылками на адрес предыдущего и следующего узла в последовательности. Кроме того, одно поле данных ссылается на данные этого конкретного узла.
Часть данных: хранит данные.
Prev Part: хранит адрес предыдущего узла.
Следующая часть: хранит адрес следующего узла.
Поскольку нет узла до первого узла и после последнего узла, указатель prev первого узла и следующий указатель последнего узла указывают на NULL.
Использование Двусвязного списка, используемого в python: Двусвязные списки очень полезны там, где требуется как передняя, так и задняя навигация. Это позволяет обходить список в любом направлении. Двусвязный список требует изменения большего количества ссылок, чем односвязный список, при добавлении или удалении узлов. Но эти операции потенциально проще и эффективнее, так как не требуют отслеживания предыдущего узла, в отличие от односвязного списка. Он имеет различные приложения для реализации функций отмены и повтора.
Вот что мы подробно узнаем о Двусвязном списке в Python:
- Создание и отображение Двусвязного списка в python
- Удаление элементов из Двусвязного списка
- Переход по Двусвязному списку
- Реверсирование двусвязного списка
Строковый тип данных в Python
Строки — это неизменяемая коллекция символов. В Python строки могут хранить текстовые символы или произвольную коллекцию байтов (содержимое файла изображений). В python строковые объекты хранятся в последовательности. Последовательности поддерживают порядок слева направо среди элементов и хранятся и извлекаются по их относительному положению.В Python очень легко создавать объекты strings, любые символы, заключенные в кавычки, становятся строковыми (кавычки могут быть ‘(одинарными) или «(двойными)).
Строка в Python-это неизменяемая и упорядоченная последовательность элементов. Они могут быть определены с помощью одинарных кавычек (‘) или двойных кавычек («). Строка, охватывающая несколько строк, может быть определена с помощью тройных одинарных кавычек («‘) или тройных двойных кавычек («»»). Например:
Поскольку строки в Python упорядочены, мы можем извлекать отдельные символы из строки, используя их целочисленные индексы, начиная с 0. Первая буква строки всегда находится в позиции 0, и после этого позиции численно увеличиваются. Например:
Строки в Python также поддерживают slicing. Нарезка-это метод, который используется для извлечения части переменной с использованием обозначения , где start_position и end_position — целые числа, указывающие длину среза. Если start_position опущен, то нарезка начинается в начале строки, а если end_position опущен, то нарезка заканчивается в конце строки. Например:
Как лучше выбирать элементы из списка?
Если вы хотите продуктивно работать со списками, то должны уметь получать доступ к данным, хранящимся в них.
Обычно мы получаем доступ к элементам списков, чтобы изменять определенные значения, обновлять или удалять их, или выполнять какие-либо другие операции с ними. Мы получаем доступ к элементам списков и, собственно, ко всем другим типам последовательностей, при помощи оператора индекса . Внутри него мы помещаем целое число.
# Выбираем первый элемент списка oneZooAnimal = biggerZoo # Выводим на экран переменную `oneZooAnimal` print(oneZooAnimal)
Запустите данный код и убедитесь, что вы получите первый элемент списка, сохраненного в переменную . Это может быть поначалу несколько непривычно, но нумерация начинается с числа , а не .
Как получить последний элемент списка?
Ответ на этот вопрос является дополнением к объяснению в предыдущем разделе.
Попробуйте ввести отрицательное значение, например, или , в оператор индекса, чтобы получить последние элементы нашего списка !
# Вставляем -1 monkeys = biggerZoo print(monkeys) # А теперь -2 zebra = biggerZoo print(zebra)
Не правда ли, не слишком сложно?
Что означает ошибка «Index Out Of Range»?
Эта ошибка одна из тех, которые вы будете видеть достаточно часто, особенно если вы новичок в программировании.
Лучший способ понять эту ошибку — попробовать ее получить самостоятельно.
Возьмите ваш список и передайте в оператор индекса либо очень маленькое отрицательное число, либо очень большое положительное число.
Как видите, вы можете получить ошибку «Индекс вне диапазона» в случаях, когда вы передаете в оператор индекса целочисленное значение, не попадающее в диапазон значений индекса списка. Это означает, что вы присваиваете значение или ссылаетесь на (пока) несуществующий индекс.
Срезы в списках
Если вы новичок в программировании и в Python, этот вопрос может показаться одним из наиболее запутанных.
Обычно нотация срезов используется, когда мы хотим выбрать более одного элемента списка одновременно. Как и при выборе одного элемента из списка, мы используем двойные скобки. Отличие же состоит в том, что теперь мы еще используем внутри скобок двоеточие. Это выглядит следующим образом:
# Используем нотацию срезов someZooAnimals = biggerZoo # Выводим на экран то, что мы выбрали print(someZooAnimals) # Теперь поменяем местами 2 и двоеточие otherZooAnimals = biggerZoo # Выводим на экран полученный результат print(otherZooAnimals)
Вы можете видеть, что в первом случае мы выводим на экран список начиная с его элемента , который имеет индекс . Иными словами, мы начинаем с индекса и идем до конца списка, так как другой индекс не указан.
Что же происходит во втором случае, когда мы поменяли местами индекс и двоеточие? Вы можете видеть, что мы получаем список из двух элементов, и . В данном случае мы стартуем с индекса и доходим до индекса (не включая его). Как вы можете видеть, результат не будет включать элемент .
В общем, подводя итоги:
# элементы берутся от start до end (но элемент под номером end не входит в диапазон!) a # элементы берутся начиная со start и до конца a # элементы берутся с начала до end (но элемент под номером end не входит в диапазон!) a
Совет: передавая в оператор индекса только двоеточие, мы создаем копию списка.
В дополнение к простой нотации срезов, мы еще можем задать значение шага, с которым будут выбираться значения. В обобщенном виде нотация будет иметь следующий вид:
# Начиная со start, не доходя до end, с шагом step a
Так что же по сути дает значение шага?
Ну, это позволяет вам буквально шагать по списку и выбирать только те элементы, которые включает в себя значение вашего шага. Вот пример:
Обратите внимание, что если вы не указали какое-либо значение шага, оно будет просто установлено в значение . При проходе по списку ни один элемент пропущен не будет
Также всегда помните, что ваш результат не включает индекс конечного значения, который вы указали в записи среза!
Как случайным образом выбрать элемент из списка?
Для этого мы используем пакет .
# Импортируем функцию `choice` из библиотеки `random` from random import choice # Создадим список из первых четырех букв алфавита list = # Выведем на экран случайный элемент списка print(choice(list))
Если мы хотим выбрать случайный элемент из списка по индексу, то можем использовать метод из той же библиотеки .
# Импортируем функцию `randrange` из библиотеки `random` from random import randrange # Создадим список из первых четырех букв алфавита randomLetters = # Выбираем случайный индекс нашего списка randomIndex = randrange(0,len(randomLetters)) # Выводим случайный элемент на экран print(randomLetters)
Совет: обратите внимание на библиотеку , она может вам пригодиться во многих случаях при программировании на Python
Массивы в Python
Python массивы и списки представляют собой простой набор связанных значений, которые называются элементами. Обычно это любой тип данных, включая объекты или другие списки! При работе с массивами все данные должны быть одинаковыми — нельзя хранить вместе строки и целые числа. Вам почти всегда придется указывать, сколько элементов нужно хранить. Динамические массивы существуют, но проще начать с массивов фиксированной длиной.
Python несколько усложняет ситуацию. Он не всегда придерживается строгих определений структур данных. Большинство объектов в Python обычно являются списками, поэтому создавая массив, вы проделываете больше работы. Вот начальный код:
from array import array
numbers = array('i', )
print numbers
Первая строка импортирует модуль array, необходимый для работы с массивами. Вторая строка создает новый массив numbers и инициализирует его значениями 2, 4, 6 и 8. Каждому элементу присваивается целочисленное значение, называемое ключом или индексом. Ключи начинаются с нуля, поэтому будет обращаться к первому элементу (2):
itypecodePythonPythonPythonC-массивахPython
Нельзя хранить элементы разных типов в этих массивах. Допустим, вы захотели сохранить строку «makeuseof.com»:
numbers = array('i', )
Это вызовет исключение при работе с Python массивом строк:
print numbers
Каждый язык программирования реализует цикл, который идеально подходит для итерации (циклизации) над элементами списка.
Наиболее распространенные циклы while и for. Python делает это еще проще, предоставляя цикл for in:
for number in numbers:
print number
Обратите внимание на то, что вам не нужно обращаться к элементам по их ключу. Это лучший способ работы с массивом
Альтернативный способ перебора списка — это цикл for:
for i in range(len(numbers)):
print numbers
Этот пример делает то же самое, что и предыдущий. Но в нем нужно указать количество элементов в массиве (len (cars)), а также передать i в качестве ключа. Это почти тот же код, который выполняется в цикле for in. Этот способ обеспечивает большую гибкость и выполняется немного быстрее (хотя цикла for in в большинстве случаев более чем достаточно).
1. Определения и классификация
1.1 Что и зачем
- Генераторы выражений предназначены для компактного и удобного способа генерации коллекций элементов, а также преобразования одного типа коллекций в другой.
- В процессе генерации или преобразования возможно применение условий и модификация элементов.
- Генераторы выражений являются синтаксическим сахаром и не решают задач, которые нельзя было бы решить без их использования.
1.2 Преимущества использования генераторов выражений
- Более короткий и удобный синтаксис, чем генерация в обычном цикле.
- Более понятный и читаемый синтаксис чем функциональный аналог сочетающий одновременное применение функций map(), filter() и lambda.
- В целом: быстрее набирать, легче читать, особенно когда подобных операций много в коде.
1.3 Классификация и особенности
- выражение-генератор (generator expression) — выражение в круглых скобках которое выдает создает на каждой итерации новый элемент по правилам.
- генератор коллекции — обобщенное название для генератора списка (list comprehension), генератора словаря (dictionary comprehension) и генератора множества (set comprehension).
Обратитесь в массив списка в Python
Как мы уже обсуждали Списки и Массивы похожи в Python. Там, где основное различие между ними, в том, что массивы позволяют только элементы одного и того же типа данных, в то время как списки позволяют им быть разными.
Поскольку Python не поддерживает обычные массивы, мы можем использовать списки, чтобы изобразить то же самое и попытаться отменить их. Давайте посмотрим на разные методы, следующие, которые мы можем достичь этой задачи,
1. Использование списка нарезка, чтобы изменить массив в Python
Мы можем изменить массив списка, используя нарезка методы. Таким образом, мы фактически создаем новый список в обратном порядке как у оригинального. Давайте посмотрим, как:
#The original array
arr =
print("Array is :",arr)
res = arr #reversing using list slicing
print("Resultant new reversed array:",res)
Выход :
Array is : Resultant new reversed array:
2. Использование метода обратного ()
Python также предоставляет встроенный метод Это непосредственно меняет порядок элементов списка прямо на исходном месте.
Примечание : Таким образом, мы меняем порядок фактического списка. Следовательно, исходный порядок потерян.
#The original array
arr =
print("Before reversal Array is :",arr)
arr.reverse() #reversing using reverse()
print("After reversing Array:",arr)
Выход :
Before reversal Array is : After reversing Array:
3. Использование обратного () метода
У нас еще один метод, Что при прохождении со списком возвращает намерение имеющих только элементы списка в обратном порядке. Если мы используем Метод на этом намечном объекте мы получаем новый список, который содержит наш обратный массив.
#The original array
arr =
print("Original Array is :",arr)
#reversing using reversed()
result=list(reversed(arr))
print("Resultant new reversed Array:",result)
Выход :
Original Array is : Resultant new reversed Array:
Массив нарезки
Все идет нормально; Создание и индексация массивов выглядит знакомо.
Теперь мы подошли к нарезке массивов, и это одна из функций, которая создает проблемы для начинающих массивов Python и NumPy.
Структуры, такие как списки и массивы NumPy, могут быть нарезаны. Это означает, что подпоследовательность структуры может быть проиндексирована и извлечена.
Это наиболее полезно при машинном обучении при указании входных и выходных переменных или разделении обучающих строк из строк тестирования.
Нарезка задается с помощью оператора двоеточия ‘:’ с ‘от’ а также ‘в‘Индекс до и после столбца соответственно. Срез начинается от индекса «от» и заканчивается на один элемент перед индексом «до».
Давайте рассмотрим несколько примеров.
Одномерная нарезка
Вы можете получить доступ ко всем данным в измерении массива, указав срез «:» без индексов.
При выполнении примера печатаются все элементы в массиве.
Первый элемент массива можно разрезать, указав фрагмент, который начинается с индекса 0 и заканчивается индексом 1 (один элемент перед индексом «до»)
Выполнение примера возвращает подмассив с первым элементом.
Мы также можем использовать отрицательные индексы в срезах. Например, мы можем нарезать последние два элемента в списке, начав срез с -2 (второй последний элемент) и не указав индекс «до»; это берет ломтик до конца измерения.
Выполнение примера возвращает подмассив только с двумя последними элементами.
Двумерная нарезка
Давайте рассмотрим два примера двумерного среза, которые вы, скорее всего, будете использовать в машинном обучении.
Разделение функций ввода и вывода
Распространено загруженные данные на входные переменные (X) и выходную переменную (y).
Мы можем сделать это, разрезая все строки и все столбцы до, но перед последним столбцом, затем отдельно индексируя последний столбец.
Для входных объектов мы можем выбрать все строки и все столбцы, кроме последнего, указав ‘:’ в индексе строк и: -1 в индексе столбцов.
Для выходного столбца мы можем снова выбрать все строки, используя ‘:’, и индексировать только последний столбец, указав индекс -1.
Собрав все это вместе, мы можем разделить 3-колоночный 2D-набор данных на входные и выходные данные следующим образом:
При выполнении примера печатаются разделенные элементы X и y
Обратите внимание, что X — это двумерный массив, а y — это одномерный массив
Сплит поезд и тестовые ряды
Обычно загруженный набор данных разбивают на отдельные наборы поездов и тестов.
Это разделение строк, где некоторая часть будет использоваться для обучения модели, а оставшаяся часть будет использоваться для оценки мастерства обученной модели.
Для этого потребуется разрезать все столбцы, указав «:» во втором индексе измерения. Набор обучающих данных будет содержать все строки от начала до точки разделения.
Тестовым набором данных будут все строки, начиная с точки разделения до конца измерения.
Собрав все это вместе, мы можем разделить набор данных в надуманной точке разделения 2.
При выполнении примера выбираются первые две строки для обучения и последняя строка для набора тестов.
Если можно менять исходные списки
Предположим, что после слияния старые списки больше не нужны (как обычно и случается). Тогда можно написать еще один способ. Будем как и раньше сравнивать нулевые элементы списков и вызывать у списка с меньшим, пока один из списков не закончится.
Получили простенькую функцию на 4 строчки, но использовать дальше исходные списки не получится. Можно их скопировать, потом работать с копиями, но это потребует много дополнительного времени. Здесь будут проблемы с тем, что удаление нулевого элемента очень дорогое. Поэтому еще одна модификация будет заключаться в том, что мы будем вместо удаления из начала списка использовать удаление из конца, но придется в конце развернуть списки.
Словарные типы данных в Python
Словари в Python-это списки пар Ключ: Значение. Это очень мощный тип данных для хранения большого количества связанной информации, которая может быть связана с помощью ключей . Основная операция словаря заключается в извлечении значения на основе имени ключа . В отличие от списков, где используются индексные номера, словари позволяют использовать ключ для доступа к его членам. Словари также можно использовать для сортировки, итерации и сравнения данных.
Словари создаются с помощью фигурных скобок ({}) с парами, разделенными запятой (,), и ключевыми значениями, связанными с двоеточием(:). В словарях Ключ должен быть уникальным. Вот краткий пример того, как можно использовать словари:
Мы используем ключ для получения соответствующего значения. Но не наоборот.
Обязательно прочтите: Реализация стека в Python
Создание и заполнение
Перед тем как добавить (создать) новый массив в Python 3, необходимо произвести импорт библиотеки, отвечающей за работу с таким объектом. Для этого потребуется добавить строку в файл программы. Как уже было сказано ранее, массивы ориентированы на взаимодействие с одним постоянным типом данных, вследствие чего все их ячейки имеют одинаковый размер. Воспользовавшись функцией array, можно создать новый набор данных. В следующем примере демонстрируется заполнение массива Python — запись целых чисел при помощи метода, предложенного выше.
from array import *
data = array('i', )
Как можно заметить, функция array принимает два аргумента, первым из которых становится тип создаваемого массива, а на месте второго стоит начальный список его значений. В данном случае i представляет собой целое знаковое число, занимающее 2 байта памяти. Вместо него можно использовать и другие примитивы, такие как 1-байтовый символ (c) или 4-байтовое число с плавающей точкой (f).
При этом важно помнить, что массив способен хранить только данные одного типа, иначе вызов программы завершится ошибкой. Обратиться к элементу можно при помощи квадратных скобок, к примеру, data
Обратиться к элементу можно при помощи квадратных скобок, к примеру, data.