Html parser python
Содержание:
- Quick Overview of HTTP Requests
- Объект Response
- Response Content¶
- Authentication
- PHP GET request in Laravel
- The Message Body
- Status Codes
- Производительность
- Использование Translate API
- PHP POST request in Laravel
- Python requests head method
- Our First Request
- Обработка исключений при использовании urllib.request.
Quick Overview of HTTP Requests
HTTP requests are how the web works. Every time you navigate to a web page, your browser makes multiple requests to the web page’s server. The server then responds with all the data necessary to render the page, and your browser then actually renders the page so you can see it.
The generic process is this: a client (like a browser or Python script using Requests) will send some data to a URL, and then the server located at the URL will read the data, decide what to do with it, and return a response to the client. Finally, the client can decide what to do with the data in the response.
Part of the data the client sends in a request is the request method. Some common request methods are GET, POST, and PUT. GET requests are normally for reading data only without making a change to something, while POST and PUT requests generally are for modifying data on the server. So for example, the Stripe API allows you to use POST requests to create a new charge so a user can purchase something from your app.
This article will cover GET requests only because we won’t be modifying any data on a server.
When sending a request from a Python script or inside a web app, you, the developer, gets to decide what gets sent in each request and what to do with the response. So let’s explore that by first sending a request to Scotch.io and then by using a language translation API.
Объект Response
Response — это объект для проверки результатов запроса.
Давайте сделаем тот же запрос, но на этот раз сохраним его в переменную, чтобы мы могли более подробно изучить его атрибуты и поведение:
В этом примере вы захватили значение, возвращаемое значение , которое является экземпляром Response, и сохранили его в переменной response. Название переменной может быть любым.
Код ответа HTTP
Первый кусок данных, который можно получить из ответа — код состояния (он же код ответа HTTP). Код ответа информирует вас о состоянии запроса.
Например, статус означает, что ваш запрос был успешно выполнен, а статус означает, что ресурс не найден. Есть множество других ответов сервера, которые могут дать вам информацию о том, что произошло с вашим запросом.
Используя вы можете увидеть статус, который вернул вам в ответ сервер:
вернул 200 — это значит, что запрос успешно выполнен и сервер отдал вам запрашиваемые данные.
Иногда эту информацию можно использовать в коде для принятия решений:
Если сервер возвращает 200, то программа выведет , если код ответа 400, то программа выведет .
Requests делает еще один шаг к тому, чтобы сделать это проще. Если вы используете экземпляр Response в условном выражении, то он получит значение , если код ответа между 200 и 400, и False во всех остальных случаях.
Поэтому вы можете сделать проще последний пример, переписав :
Помните, что этот метод не проверяет, что код состояния равен 200.
Причиной этого является то, что ответы с кодом в диапазоне от 200 до 400, такие как и , тоже считаются истинными, так как они дают некоторый обрабатываемый ответ.
Например, статус 204 говорит о том, что запрос был успешным, но в теле ответа нет содержимого.
Поэтому убедитесь, что вы используете этот сокращенный вид записи, только если хотите узнать был ли запрос успешен в целом. А затем обработать код состояния соответствующим образом.
Если вы не хотите проверять код ответа сервера в операторе , то вместо этого вы можете вызвать исключение, если запрос был неудачным. Это можно сделать вызвав :
Если вы используете , то HTTPError сработает только для определенных кодов состояния. Если состояние укажет на успешный запрос, то исключение не будет вызвано и программа продолжит свою работу.
Теперь вы знаете многое о том, что делать с кодом ответа от сервера. Но когда вы делаете GET-запрос, вы редко заботитесь только об ответе сервера — обычно вы хотите увидеть больше.
Далее вы узнаете как просмотреть фактические данные, которые сервер отправил в теле ответа.
Content
Ответ на Get-запрос, в теле сообщения часто содержит некую ценную информацию, известную как «полезная нагрузка» («Payload»). Используя атрибуты и методы Response, вы можете просматривать payload в разных форматах.
Чтобы увидеть содержимое ответа в байтах, используйте :
Пока дает вам доступ к необработанным байтам полезной нагрузки ответа, вы можете захотеть преобразовать их в строку с использованием кодировки символов UTF-8. Response это сделает за вас, когда вы укажите :
Поскольку для декодирования байтов в строки требуется схема кодирования, Requests будет пытаться угадать кодировку на основе заголовков ответа. Вы можете указать кодировку явно, установив перед указанием :
Если вы посмотрите на ответ, то вы увидите, что на самом деле это последовательный JSON контент. Чтобы получить словарь, вы можете взять строку, которую получили из и десериализовать ее с помощью . Однако, более простой способ сделать это — использовать .
Тип возвращаемого значения — это словарь, поэтому вы можете получить доступ к значениям в объекте по ключу.
Вы можете делать многое с кодом состояний и телом сообщений. Но если вам нужна дополнительная информация, такая как метаданные о самом ответе, то вам нужно взглянуть на заголовки ответа.
Заголовки
Заголовки ответа могут дать вам полезную информацию, такую как тип ответа и ограничение по времени, в течение которого необходимо кэшировать ответ.
Чтобы посмотреть заголовки, укажите :
возвращает похожий на словарь объект, позволяющий получить доступ к значениям объекта по ключу. Например, чтобы получить тип содержимого ответа, вы можете получить доступ к Content-Type:
Используя ключ или — вы получите одно и то же значение.
Теперь вы узнали основное о Response. Вы увидели его наиболее используемые атрибуты и методы в действии. Давайте сделаем шаг назад и посмотрим как изменяются ответы при настройке Get-запросов.
Response Content¶
We can read the content of the server’s response. Consider the GitHub timeline
again:
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r.text
'[{"repository":{"open_issues":0,"url":"https://github.com/...
Requests will automatically decode content from the server. Most unicode
charsets are seamlessly decoded.
When you make a request, Requests makes educated guesses about the encoding of
the response based on the HTTP headers. The text encoding guessed by Requests
is used when you access . You can find out what encoding Requests is
using, and change it, using the property:
>>> r.encoding 'utf-8' >>> r.encoding = 'ISO-8859-1'
If you change the encoding, Requests will use the new value of
whenever you call . You might want to do this in any situation where
you can apply special logic to work out what the encoding of the content will
be. For example, HTML and XML have the ability to specify their encoding in
their body. In situations like this, you should use to find the
encoding, and then set . This will let you use with
the correct encoding.
Authentication
Authentication helps a service understand who you are. Typically, you provide your credentials to a server by passing data through the header or a custom header defined by the service. All the request functions you’ve seen to this point provide a parameter called , which allows you to pass your credentials.
One example of an API that requires authentication is GitHub’s API. This endpoint provides information about the authenticated user’s profile. To make a request to the Authenticated User API, you can pass your GitHub username and password in a tuple to :
>>>
The request succeeded if the credentials you passed in the tuple to are valid. If you try to make this request with no credentials, you’ll see that the status code is :
>>>
When you pass your username and password in a tuple to the parameter, is applying the credentials using HTTP’s Basic access authentication scheme under the hood.
Therefore, you could make the same request by passing explicit Basic authentication credentials using :
>>>
Though you don’t need to be explicit for Basic authentication, you may want to authenticate using another method. provides other methods of authentication out of the box such as and .
You can even supply your own authentication mechanism. To do so, you must first create a subclass of . Then, you implement :
Here, your custom mechanism receives a token, then includes that token in the header of your request.
Bad authentication mechanisms can lead to security vulnerabilities, so unless a service requires a custom authentication mechanism for some reason, you’ll always want to use a tried-and-true auth scheme like Basic or OAuth.
While you’re thinking about security, let’s consider dealing with SSL Certificates using .
PHP GET request in Laravel
In the following example, we process a GET request in Laravel.
$ laravel new larareq $ cd larareq
We create a new Laravel application.
routes/web.php
<?php
use Illuminate\Support\Facades\Route;
use Illuminate\Http\Request;
Route::get('/', function (Request $request) {
$name = $request->query('name', 'guest');
$message = $request->query('message', 'hello there');
$output = "$name says $message";
return $output;
});
We get the GET parameters and create a response.
$ php artisan serve
We start the server.
$ curl 'localhost:8000/?name=Lucia&message=Cau' Lucia says Cau
We send a GET request with curl.
The Message Body
According to the HTTP specification, , , and the less common requests pass their data through the message body rather than through parameters in the query string. Using , you’ll pass the payload to the corresponding function’s parameter.
takes a dictionary, a list of tuples, bytes, or a file-like object. You’ll want to adapt the data you send in the body of your request to the specific needs of the service you’re interacting with.
For example, if your request’s content type is , you can send the form data as a dictionary:
>>>
You can also send that same data as a list of tuples:
>>>
If, however, you need to send JSON data, you can use the parameter. When you pass JSON data via , will serialize your data and add the correct header for you.
httpbin.org is a great resource created by the author of , Kenneth Reitz. It’s a service that accepts test requests and responds with data about the requests. For instance, you can use it to inspect a basic request:
>>>
Status Codes
The first thing we can do is check the status code. HTTP codes range from the 1XX to 5XX. Common status codes that you have probably seen are 200, 404, and 500.
Here’s a quick overview of what each status code means:
- 1XX — Information
- 2XX — Success
- 3XX — Redirect
- 4XX — Client Error (you messed up)
- 5XX — Server Error (they messed up)
Generally, what you’re looking for when you perform your own requests are status codes in the 200s.
Requests recognizes that 4XX and 5XX status codes are errors, so if those status codes get returned, the response object from the request evaluates to False.
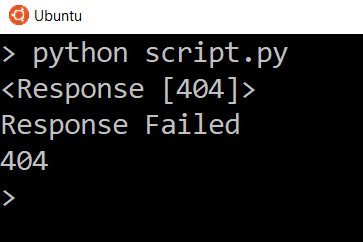
You can test if a request responded successfully by simply checking the response for truth. For example:
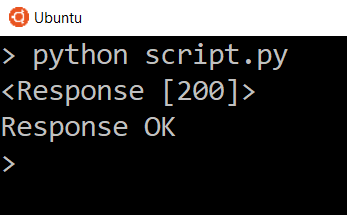
The message “Response Failed” will only appear if a 400 or 500 status code returns. Try changing the URL to some nonsense to see the response fail with a 404.
You can take a look at the status code directly by doing:
This will show you the status code directly so you can check the number yourself.
Производительность
При использовании , особенно в продакшене, важно учитывать влияние на производительность. Такие функции, как контроль времени ожидания, сеансы и ограничения повторных попыток, могут обеспечить вам бесперебойную работу приложения
Время ожидания
Когда вы отправляете запрос во внешнюю службу, вашей системе потребуется дождаться ответа, прежде чем двигаться дальше. Если ваше предложение слишком долго ожидает ответа — запросы к службе могут быть скопированы, пользовательский интерфейс может пострадать или фоновые задания могут зависнуть.
По умолчанию, будет ждать ответа до бесконечности, поэтому вы почти всегда должны указывать время ожидания. Чтобы установить время ожидания, используйте параметр . Тайм-аут может быть целым числом или числом с плавающей запятой, представляющим количество секунд ожидания ответа:
В первом запросе, время ожидания истекает через одну секунду. Во втором — через 3,05 секунд.
Вы также можете передать кортеж тайм-ауту. Первый элемент в кортеже является тайм-аутом соединения (время, которое позволяет установить клиенту соединение с сервером), а второй элемент — время ожидания чтения (время ожидания ответа после того, как клиент установил соединение):
Если запрос устанавливает соединение в течение 2 секунд и получает данные в течение 5 секунд после установки соединения, то ответ будет возвращен. Если время ожидания истекло — функция вызовет исключение :
Ваша программа может перехватить исключение и ответить соответствующим образом.
Объект Session
До сих пор вы имели дело с интерфейсами API высокого уровня, такими как и . Эти функции являются абстракциями над тем, что происходит когда вы делаете свои запросы. Они скрывают детали реализации, такие как управление соединениями, так что вам не нужно беспокоиться о них.
Под этими абстракциями находится класс . Если вам необходимо настроить контроль над выполнением запросов и повысить производительность вашего приложения — вам может потребоваться использовать экземпляр напрямую.
Сеансы используются для сохранения параметров в запросах. Например, если вы хотите использовать одну и ту же аутентификацию для нескольких запросов, вы можете использовать сеанс:
Каждый раз, когда вы делаете запрос в сеансе, после того, как он был инициализирован с учетными данными аутентификации, учетные данные будут сохраняться.
Первичная оптимизация производительности сессий происходит в форме постоянных соединений. Когда ваше приложение устанавливает соединение с сервером, используя , оно сохраняет это соединение в пуле с остальными соединениями. Когда ваше приложение снова подключиться к тому же серверу, оно будет повторно использовать соединение из пула, а не устанавливать новое.
Максимальное количество попыток
В случае сбоя запроса, вы можете захотеть, чтобы приложение отправило запрос повторно. Однако не делает этого за вас по умолчанию. Чтобы реализовать эту функцию, вам необходимо реализовать собственный .
Транспортные адаптеры позволяют вам определять набор конфигураций для каждой службы , с которой вы взаимодействуете. Например, вы хотите, чтобы все запросы к https://api.github.com, повторялись по три раза, прежде чем вызовется исключение . Вы должны сконструировать транспортный адаптер, установить его параметр и подключить его к существующему сеансу:
Когда вы монтируете и в — будет придерживаться этой конфигурации в каждом запросе к https://api.github.com.
Время ожидания, транспортные адаптеры и сеансы, предназначены для обеспечения эффективности вашего кода и отказоустойчивости приложения.
Использование Translate API
Теперь перейдем к чему-то более интересному. Мы используем API Яндекс.Перевод (Yandex Translate API) для выполнения запроса на перевод текста на другой язык.
Чтобы использовать API, нужно предварительно войти в систему. После входа в систему перейдите к Translate API и создайте ключ API. Когда у вас будет ключ API, добавьте его в свой файл в качестве константы. Далее приведена ссылка, с помощью которой вы можете сделать все перечисленное: https://tech.yandex.com/translate/
script.py
Ключ API нужен, чтобы Яндекс мог проводить аутентификацию каждый раз, когда мы хотим использовать его API. Ключ API представляет собой облегченную форму аутентификации, поскольку он добавляется в конце URL запроса при отправке.
Чтобы узнать, какой URL нам нужно отправить для использования API, посмотрим документацию Яндекса.
Там мы найдем всю информацию, необходимую для использования их Translate API для перевода текста.
Если вы видите URL с символами амперсанда (&), знаками вопроса (?) или знаками равенства (=), вы можете быть уверены, что это URL запроса GET. Эти символы задают сопутствующие параметры для URL.
Обычно все, что размещено в квадратных скобках ([]), будет необязательным. В данном случае для запроса необязательны формат, опции и обратная связь, но обязательны параметры key, text и lang.
Добавим код для отправки на этот URL. Замените первый созданный нами запрос на следующий:
script.py
Существует два способа добавления параметров. Мы можем прямо добавить параметры в конец URL, или библиотека Requests может сделать это за нас. Для последнего нам потребуется создать словарь параметров. Нам нужно указать три элемента: ключ, текст и язык. Создадим словарь, используя ключ API, текст и язык , т. к. нам требуется перевод с английского на испанский.
Другие коды языков можно посмотреть здесь. Нам нужен столбец 639-1.
Мы создаем словарь параметров, используя функцию , и передаем ключи и значения, которые хотим использовать в нашем словаре.
script.py
Теперь возьмем словарь параметров и передадим его функции .
script.py
Когда мы передаем параметры таким образом, Requests автоматически добавляет параметры в URL за нас.
Теперь добавим команду печати текста ответа и посмотрим, что мы получим в результате.
script.py
Мы видим три вещи. Мы видим код состояния, который совпадает с кодом состояния ответа, мы видим заданный нами язык и мы видим переведенный текст внутри списка. Итак, мы должны увидеть переведенный текст .
Повторите эту процедуру с кодом языка en-fr, и вы получите ответ .
script.py
Посмотрим заголовки полученного ответа.
script.py
Разумеется, заголовки должны быть другими, поскольку мы взаимодействуем с другим сервером, но в данном случае мы видим тип контента application/json вместо text/html. Это означает, что эти данные могут быть интерпретированы в формате JSON.
Если ответ имеет тип контента application/json, библиотека Requests может конвертировать его в словарь и список, чтобы нам было удобнее просматривать данные.
Для обработки данных в формате JSON мы используем метод на объекте response.
Если вы распечатаете его, вы увидите те же данные, но в немного другом формате.
script.py
Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Допустим, нам нужно получить доступ к тексту. Поскольку сейчас это словарь, мы можем использовать ключ текста.
script.py
Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
script.py
Теперь мы видим только переведенное слово.
Разумеется, если мы изменим параметры, мы получим другие результаты. Изменим переводимый текст с на , изменим язык перевода на испанский и снова отправим запрос.
script.py
Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.
PHP POST request in Laravel
In the following example, we send a POST request from an HTML form.
resources/views/home.blade.php
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Home page</title>
<style>
.alert { color: red}
</style>
</head>
<body>
@if ($errors->any())
<div class="alert">
<ul>
@foreach ($errors->all() as $error)
<li>{{ $error }}</li>
@endforeach
</ul>
</div>
@endif
<form action="process_form" method="post">
@csrf
<label for="name">Name</label> <input id="name"
value="{{old('name')}}"type="text" name="name">
<label for="message">Message</label> <input id="message"
value="{{old('message')}}" type="text" name="message">
<button type="submit">Submit</button>
</form>
</body>
</html>
We have a POST form in a Blade template. Laravel requires CSRF protection for
POST requests. We enable CSRF protection with .
routes/web.php
<?php
use Illuminate\Support\Facades\Route;
use Illuminate\Http\Request;
Route::get('/', function () {
return view('home');
});
Route::post('/process_form', function (Request $request) {
$request->validate();
$name = $request->input('name');
$message = $request->input('message');
$output = "$name says: $message";
return $output;
});
We validate and retrieve the POST parameters and send them in the response.
This example should be tested in a browser.
In this tutorial, we have worked with GET and POST requests in plain PHP,
Symfony, Slim, and Laravel.
List tutorials.
Python requests head method
The method retrieves document headers.
The headers consist of fields, including date, server, content type,
or last modification time.
head_request.py
#!/usr/bin/env python3
import requests as req
resp = req.head("http://www.webcode.me")
print("Server: " + resp.headers)
print("Last modified: " + resp.headers)
print("Content type: " + resp.headers)
The example prints the server, last modification time, and content type
of the web page.
$ ./head_request.py Server: nginx/1.6.2 Last modified: Sat, 20 Jul 2019 11:49:25 GMT Content type: text/html
This is the output of the program.
Our First Request
To start, let’s use Requests for something simple: requesting the Scotch.io site. Create a file called script.py and add the following code to it. In this article, we won’t have much code to work with, so when something changes you can just update the existing code instead of adding new lines.
So all this code is doing is sending a GET request to Scotch.io. This is the same type of request your browser sent to view this page, but the only difference is that Requests can’t actually render the HTML, so instead you will just get the raw HTML and the other response information.
We’re using the .get() function here, but Requests allows you to use other functions like .post() and .put() to send those requests as well.
You can run it by executing the script.py file.
And here’s what you get in return: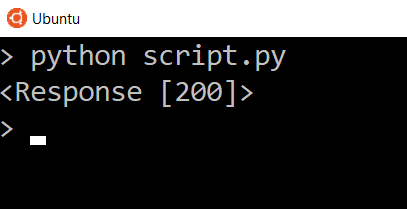
Обработка исключений при использовании urllib.request.
Функция вызывает , когда не может обработать ответ (хотя, как обычно с API Python, также могут возникать встроенные исключения, такие как , и т. д.).
— это подкласс , возникающий в конкретном случае при запросе URL-адресов по HTTP протоколу.
Классы исключений экспортируются из модуля .
Обработка ошибок .
Часто возникает из-за отсутствия сетевого подключения (нет маршрута к указанному серверу) или из-за того, что указанный сервер не существует. В этом случае возникшее исключение будет иметь атрибут, который представляет собой кортеж, содержащий код ошибки и текстовое сообщение об ошибке.
>>> req = urllib.request.Request('http://www.pretend_server.org')
>>> try urllib.request.urlopen(req)
... except urllib.error.URLError as e
... print(e.reason)
...
# (4, 'getaddrinfo failed')
Обработка ошибок .
Каждый ответ HTTP от сервера содержит числовой код ответа сервера. Иногда код этот состояния указывает на то, что сервер не может выполнить запрос. Обработчики по умолчанию будут обрабатывать некоторые из этих ответов за вас (например, если ответ представляет собой перенаправление, которое запрашивает у клиента выборку документа с другого URL-адреса, то модуль сделает это за вас). Для тех URL-адресов, с которыми модуль не может справиться, он вызывает ошибки HTTPError. Типичные ошибки включают 404 (страница не найдена), 403 (запрос запрещен) и 401 (требуется аутентификация).
Возникший экземпляр будет иметь целочисленный атрибут code, который соответствует ошибке, отправленной сервером. Поскольку обработчики по умолчанию обрабатывают перенаправления (коды в диапазоне 300), а коды в диапазоне 100–299 указывают на успех, то необходимо обрабатывать только коды ошибок в диапазоне 400–599.
Когда возникает ошибка, сервер отвечает, возвращая код ошибки HTTP и страницу с ошибкой. Можете использовать экземпляр в качестве ответа на возвращенной странице. Это означает, что помимо атрибута он также имеет методы , и , возвращаемые модулем :
>>> req = urllib.request.Request('http://www.python.org/fish.html')
>>> try
... urllib.request.urlopen(req)
... except urllib.error.HTTPError as e
... print(e.code)
... print(e.read())
...
# 404
# b'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
# "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\n\n\n<html
# ...
# <title>Page Not Found</title>\n
# ...
Итак, если необходимо обрабатывать ошибки или , есть два основных подхода. Мы предпочитаем второй подход.
Первый способ:
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
req = Request(someurl)
try
response = urlopen(req)
except HTTPError as e
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
except URLError as e
print('We failed to reach a server.')
print('Reason: ', e.reason)
else
# Все в порядке
Примечание. Исключение HTTPError должно быть первым, иначе исключение URLError также перехватит HTTPError.
Второй способ:
from urllib.request import Request, urlopen
from urllib.error import URLError
req = Request(someurl)
try
response = urlopen(req)
except URLError as e
if hasattr(e, 'reason'):
print('We failed to reach a server.')
print('Reason: ', e.reason)
elif hasattr(e, 'code'):
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
else
# все в порядке