Как инструмент «парсинг поисковых подсказок» поможет в работе seo-специалиста?
Содержание:
- Какие задачи помогает решить парсер?
- Определение LSI-копирайтинга
- Что такое ключевые запросы
- Зачем нужен Kparser?
- Программы парсеры
- Алгоритм работы парсера
- Значение ключевых слов для продвижения сайта
- Различия между Словоеб_ом и Key Collector_ом
- Онлайн парсеры
- Вместо заключения
- Правильный подбор ключевых слов
- Что такое парсинг?
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:
- Мониторинг цен. Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.
- Поиск товарных позиций. Полезная опция на тот случай, если сайт поставщика не дает возможности быстро и автоматически перенести базу данных с товарами. Можно самостоятельно «запарсить» информацию по нужным критериям и перенести ее на свой сайт. Не придется копировать данные о каждой товарной единице вручную.
- Извлечение метаданных. Специалисты по SEO-продвижению используют парсеры, чтобы скопировать у конкурентов содержимое тегов title, description и т.п. Парсинг ключевых слов – один из наиболее распространенных методов аудита чужого сайта. Он помогает быстро внести нужные изменения в SEO для ускоренного и максимально эффективного продвижения ресурса.
- Аудит ссылок. Парсеры иногда задействуют для поиска проблем на странице. Вебмастера настраивают их под поиск конкретных ошибок и запускают, чтобы в автоматическом режиме выявить все нерабочие страницы и ссылки.
Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Определение LSI-копирайтинга
LSI, латентное семантическое индексирование, основано на технологии LSA, латентном семантическом анализе. Эта методика используется для автоматической индексации текста и проверки семантической структуры на наличие логических связей.
LSA задействует обновленные алгоритмы обработки данных с целью обнаружить в тексте не просто шквал ключевых слов, соответствующих поисковому запросу пользователя, а уловить общий смысл материала. С помощью LSA Яндекс, Google и другие поисковые машины могут находить для людей релевантный и полезный контент.
Подробнее о LSA
Ключевая задача LSA как метода – выявить логические связи в тексте. Поисковые боты используют эту методику для анализа естественного языка и формирования общей идеи текста, чтобы выдать статью в результатах поиска при вводе соответствующего запроса (в тот же Google или Яндекс).
Механизм LSA представляет собой систему сопоставления запроса с встречающимися в статьях терминами, а также модель анализа часто встречающихся в тексте слов с их определениями (проверка на соответствие фразы конкретной теме). Этот процесс позволяет «понять» тематику материала и оценить его качество без оглядки на плотность используемых ключевых слов.
Кратакая история индексации статей в интернете (появление тематического ядра)
В нулевых поиск работал примерно следующим образом:
-
Вы вводите какой-то поисковой запрос. Например, «купить гитара Москва недорого».
-
Получаете на первой странице десятки статей, которые идеально подогнаны под SEO благодаря огромному количеству ключей в тексте. Но смысла и пользы в этих статьях никакой.
На ранжирование влияли именно ключи. Они вставлялись даже в том случае, если не вписывались в текст логически и визуально. Тексты трудно было читать, они не несли внятной смысловой нагрузки, но все равно были в топ-10 статей по запросу.
С появлением новых алгоритмов (после 2011 года) поисковики научились анализировать содержимое текстов и фильтровать некачественные материалы, содержащие избыток ключей в груде исковерканного текста.
В ход пошли синонимы, ассоциации, гиперонимы, любые связанные текстовые элементы. В общем, некое тематическое ядро, напрямую не зависящее от выбранных ключевых слов. Именно тематическое ядро стало главным критерием при определении релевантности и качества текстов.
Пример тематического ядра
Блогер Koma Live в своей публикации на Medium описал наглядный пример использования тематического ядра и его влияния на результаты поиска.
Представим себе часто используемый поисковой запрос – «гольф». И вы взялись писать текст на эту тему, используя только одно ключевое слово. Основываясь только на нем, поисковик не сможет понять, о чем ваша статья. Об игре? Об автомобиле? Или о длинных носках? Поэтому робот будет пытаться проанализировать контекст (то самое тематическое ядро).
По этой причине копирайтерам в ТЗ часто указывают не только основные ключевые запросы, но и дополнительные слова, которые нужно использовать, чтобы сыграть на LSI-факторе (помимо SEO).
Проблема ключевых слов с длинным хвостом
Любой запрос в интернете, даже самый длинный, является ключом. Даже что-то в духе «обзор на лучшие ноутбуки 2020 года для программистов: HP, Lenovo, MSI, Samsung». Такие фразы не видны при поиске в подсказках Google, но они существуют и могут быть использованы для оптимизации.
Проблема таких ключей заключается в их избыточном количестве. И оптимизировать текст под каждый из них не получится. Отсюда возникает вопрос: оптимизировать текст под длинные ключи или просто упомянуть эти слова в контексте всего материала? На практике, при прочих равных, лучше работает второй метод.
LSI-копирайтинг на том и построен, что автор текста без определенных намерений адаптирует текст под бесконечное множество «хвостатых ключей», создавая тематическое ядро, которое поможет поисковику найти статью и закинуть ее в топ. Главное, чтобы сам материал оставался качественным.
Что такое ключевые запросы
Ключевые запросы (keywords, ключевики, ключи, поисковые запросы и т.д.) — это слова, словосочетания или выражения, которые пользователи вводят в поисковых системах с целью получения ответа на свой запрос. Поисковая система, в свою очередь, формирует ТОП поисковой выдачи оценивая наполнение страниц сайтов, и если оно отвечает на запрос пользователя, то она считает страницу релевантной и включает ее в поисковую выдачу.
Также запросы имеют разную классификацию, распределение по определенным группам исходя из присущих запросу признаков. Перед продолжением, рекомендуем ознакомиться с краткой справкой, о том, что такое классификация поисковых запросов.
Зачем нужен Kparser?
На официальном сайте найдете несколько полезных статей с описанием способов применения Kparser. Например:
- В Youtube — осуществляет подбор тегов и ключевых слов с «длинным хвостом» для видео, которые бы отлично охарактеризовали ролик и были максимально эффективны с точки зрения продвижения.
- Google — сбор подсказок под SEO и Adwords. Используя совместно сервисы Adwords Keyword Tool и Kparser, вы достигнете лучшего результата по выборке. Причем последний выдает в разы больше информации + доступен всем пользователями.
- Google Search Console — соединение данных из двух инструментов позволит улучшить показатели органического трафа. Собирайте релевантные подсказки для тайтлов/текстов имеющихся страниц либо делайте новые под ключевые запросы с хорошим потенциалом.
- Определяйте минус слова под ваши Adwords и Direct кампании.
- Google Search Trends — ищите трендовые направления для создания актуального контента + формируйте через Kparser фразы с длинным хвостом.
- eBay + Amazon — по аналогии с Youtube и другими нишевыми продуктами рассматриваемый проект помогает определять релевантные ключи и поднять ваш товар повыше в выдаче.
Советую хорошенько изучить все эти инструкции, т.к. там весьма детально рассмотрены ситуации, в которых Kparser позволит выжать максимум из того или иного сервиса. К сожалению, пока что информация представлена только на английском.
Возьмем к примеру Youtube…
По правилам хорошей оптимизации ролика вам нужно:
- придумать наиболее релевантный ключевой запрос для видео;
- использовать его в имени загружаемого файла, заголовке и других элементах на странице;
- создать хорошее описание с вашими ключевиками и похожими по смыслу фразами;
- добавить запросы в теги, по которым должны находить данное видео;
- напоследок поделитесь роликом во всех своих социальных аккаунтах и, возможно, попросите об этом друзей либо закажите небольшую рекламу — надо постараться сделать своего рода вирусный эффект после публикации.
Теги для видоса — очень важны. Если их не указываете, то получите нулевую оценку параметра vidIQ. С заполненными полями результат явно получше:
Теги добавляются дабы поисковики понимали о чем ваше видео и, соответственно, по каким запросам в Youtube оно будет ранжироваться.
Если у вас новый канал, старайтесь использовать менее конкурентные ключевики с длинным хвостом — так больше шансов побороться за трафик. Популярным авторам есть смысл вклиниться в борьбу по крутым тегам. Найти подходящие варианты вам как раз и поможет текущий инструмент.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
- Сначала пользователь указывает вводные данные для парсинга на сайте.
- Затем указывает список страниц или ресурсов, на которых нужно осуществить поиск.
- После этого программа в автоматическом режиме проводит глубокий анализ найденного контента и систематизирует его.
- В итоге пользователь получает отчет в заранее выбранном формате.
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах. Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Значение ключевых слов для продвижения сайта
Оптимизация сайта и его раскрутка строится на анализе ключевых слов. С помощью ключевого слова «опознают» тему и направление веб-ресурса, а также его содержимое. Поисковые запросы в виде ключевиков выдают пользователям нужную страницу. Грамотно подобранные путем анализа семантики варианты ключевых слов заводят людей на сайт, удовлетворяют их любопытство и тем самым подталкивают к покупке.
Можно подобрать ключевые слова без семантического анализа. Но в этом случае велик шанс, что запрос не «выстрелит», соответственно, такой ключевик прибыли не принесет. Чтобы слова были эффективны, нужно понимать принципы работы с ними.
Ключевое слово – что это такое?
Ключевое слово используется в двух случаях:
- во-первых, для поиска в интернете фразы;
- во-вторых, для описания товаров на сайте.
Ключевые слова в первом и втором случае обычно совпадают. При этом запросы пользователей – штука тонкая, тут обязательно нужен анализ. Иногда они бывают совсем не такими, какими их видят специалисты по сео-продвижению или владельцы веб-ресурсов. Из-за этого несоответствия в итоге продукт на сайте не покупают. Поэтому анализ ключевых слов сайта полезен тем, что он максимально устраняет различия между запросами пользователей и описаниями на интернет-площадке.
Примерно лет десять назад копирайтеры стремились как можно плотнее «напичкать» статьи ключевыми словами. В настоящее время акцент делается на качественном полезном контенте, который соответствует определенным потребительским запросам. В тренде уже новейший уровень поисковых запросов – с помощью голоса в мобильных устройствах, в частности с вопросительной интонацией.
Какие бывают ключевые слова
Существуют низкочастотные, среднечастотные и высокочастотные ключевики. В конкретной ситуации любая из этих категорий может быть результативной. Высокочастотные ключи, состоящие из одного-двух слов – носители наиболее объемного трафика, но в то же время они сильно конкурентны. Низкочастотники, состоящие из пяти и более слов, являются менее запрашиваемыми, но как раз именно они приводят целевых потребителей.
В зависимости от цели различают четыре формы запросов. Они могут быть направлены на физическое или виртуальное действие, на получение определенной информации, на посещение отдельно взятого веб-ресурса. На сайт приходят разные типы потребителей, каждый из которых совершает покупки. Поэтому в идеале сочетать все четыре формы запросов на сайте.
Первичные ключевые слова – как их найти?
Стартовая рабочая база ключевиков создается несколькими способами.
- Мозговой штурм – отличный метод в том случае, когда работники компании разбираются в своей нише деятельности и ориентируются в предпочтениях клиентов. В случае с новым товаром накидывается список идей, которые предполагают действия пользователей по поиску продукта.
- Анализ связанных слов проводится с помощью подсказок поисковых систем или в сервисе LSIGraph. Когда фраза вводится в Яндекс или Гугл, уже с первых букв поисковик выдает возможные словосочетания. Внизу поиска можно найти фразы, которые также использовались для запросов. Главное, сформулировать начальный запрос, а дальше уже выстраивается цепочка словосочетаний.
- Фиксация ключевиков, приводящих на веб-ресурс пользователей. Для анализа наиболее часто вводимых ключевых слов используются Google Analytics и Яндекс.Wordstat.
Искать ключевые фразы можно с помощью комментариев и хештегов в соцсетях и блогах, ссылок на геолокацию.
Специальные программы для работы с ключевыми словами
Специальные программы упрощают жизнь сео-оптимизаторам: они обрабатывают все слова и фразы, касающиеся продвигаемого товара. Существуют сервисы, которые давно и успешно зарекомендовали себя как отличный инструмент анализа ключей.
- Google Adwords – планировщик ключевиков. В нем каждый месяц формируются отчеты по статистике, в том числе локальной.
- Кластеризатор Seoquick формирует ключевые слова по темам, чтобы потом сделать работу с ними проще, что актуально, например, для разработки тех же рекламных объявлений.
- Яндекс.Wordstat иллюстрирует популярность тех или иных ключевых слов и помогает подобрать похожие фразы.
Данные инструменты бесплатные, несложные в применении, имеют дружественный интерфейс. Применяются как по отдельности, так и все вместе.
Использование ключевых фраз
Работа со скрупулезно сформированным семантическим ядром ведется осторожно, с использованием синонимов, без переспама и наложения ключевиков – словом, так, чтобы итоговый текст был качественный для ботов и интересный для обычных читателей.
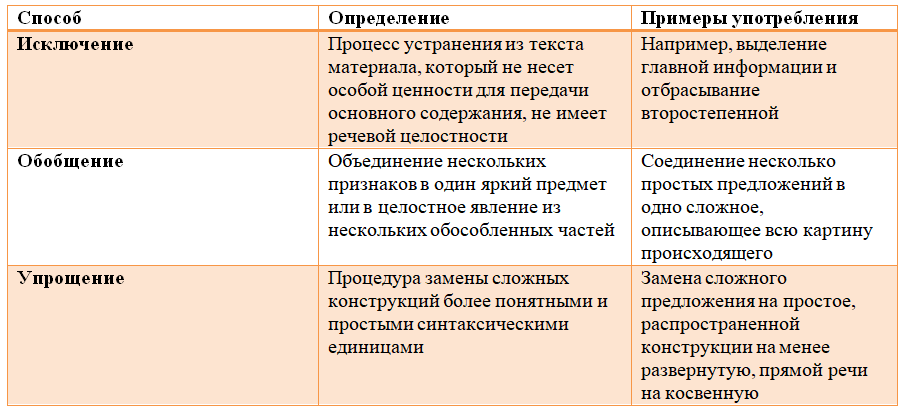
Различия между Словоеб_ом и Key Collector_ом
Разницу между программами Словоёб и Key Collector вы можете увидеть в на следующем рисунке (в виде таблицы):
Пусть программа Slovoeb не может получать позиции запросов, выполнять пакетный сбор Google AdWords, производить интеллектуальный сбор поисковых подсказок, выполнять прогноз трафика по контексту и исполнять другие функции, включенные в КейКоллектор, однако другие её функции очень полезны.
Парсинг, анализ заранее введённых слов
Словоёб позволяет выполнять пакетный сбор слов из левой и правой колонки Яндекс.Вордстат, а также пакетный сбор из Рамблер.Адстат, а также собирать в пакетном режиме поисковые подсказки. Далее, полученные слова можно проанализировать — получить частотности, узнать количество вхождений в заголовки внутренних и главных страниц.
Анализ можно провести также для самостоятельно введённых слов.
Прокси-серверы в Словоеб_е
Словоеб поддерживает работу через HTTP прокси-сервера (в том числе и с защитой доступа по паролю). Доступна загрузка списка прокси-серверов из файла или их ручная формировка. После создание списка в ручном режиме, его можно будет экспортировать в файл, нажимая кнопку «Сохранить в файл». Чтобы указать программе прокси-сервер, который следует использовать, нужно отметить строку с этим сервером галочкой. Доступные настройки вы можете увидеть на рисунке:
«Использовать прокси-серверы» — если отметить, то программа начинает использовать прокси-сервера из таблицы прокси-серверов (зелёные, отмеченные флажками).
«Деактивировать на 360 сек. не прошедшие проверку прокси-серверы» — если эта опция включена и программа получила ошибку, то после выполнения быстрой проверки на доступность прокси-сервера и получения сообщения о его недоступности, сервер исключается из очереди прокси-серверов на 360 секунд.
«Отключать в настройках отброшенные при парсинге прокси-серверы» — указание для программы автоматически выключать отброшенный прокси-сервер в таблице прокси-серверов.
«Отключать в настройках деактивированные из-за капчи прокси-серверы» — если вы используете хорошие прокси, то капчу лучше распознавать, нежели отклонять её.
Системные требования
Если подразумевается обработка большого числа данных (количество ключевых слов исчисляется десятками и сотнями тысяч штук), то желательно иметь высокопроизводительный компьютер. В таком случае также важна оперативная память ПК — чем больше, тем лучше. Наиболее оптимальной оперативной памятью является 3Гб, но и при меньших объёмах программа будет работать, правда медленно и менее устойчиво.
Также есть минимальные рекомендуемые системные требования:
- Операционная система Windows 7/8/8.1/10 или Windows XP/Vista
- Объём оперативной памяти от 2 Гб
- Тактовая частота процессора от 1,8 ГГц
- Также требуются дополнительные модули Microsoft.NET Framework 4.5 Full(для Windows 7/8/8.1/10) или Microsoft.NET Framework 4.0 Full(для других версий Windows).
О том, как настроить и использовать эту программу читайте в следующих статьях!
Онлайн парсеры
Подобные сервисы появились относительно недавно. Их преимущество – не нужно скачивать и устанавливать локально программные комплексы. Это экономит время, но сказывается на точности выборки КС. Причина – онлайн-парсеры не работают напрямую с базами данных Wordstat, а периодически скачивают их. Недостаток – не все запросы попадают в информационное поле сервиса.
Букварикс онлайн версия
Первым онлайн-сервисом с расширенными возможностями для SEO-оптимизаторов стал «Букварикс». До недавнего времени его использование было полностью бесплатным. Но с вводом нового функционала появилась платная подписка. Ее преимущества – фильтрация по частотности, количеству символов и слов. Есть ограничения для незарегистрированных пользователей. Но эта процедура бесплатная, возможна авторизация через социальные сети.
Особенности работы с «Букварикс»:
- максимальное количество поисковых фраз – 300 для платной версии;
- возможность скачивания отчета в формате .csv;
- группировка словоформ;
- дополнительные инструменты – анализ доменов, нормализатор, дубликатор и комбинатор слов.
Сервис значительно уступает по возможностям аналогичным программам, но прост в использовании. Рекомендован для начинающих оптимизаторов.
Вместо заключения
В результате, при правильном подходе к созданию семантического ядра, описанном в данном руководстве, а также нашим советам по SEO — вы в кратчайшие сроки получите максимально полное семантическое ядро для вашего сайта. К тому же запросы, сгруппированные по методу подобия поисковой выдачи с большой вероятностью попадут в ТОП выдачи поисковых систем уже в момент индексации (или переиндексации) страниц, на которые они продвигаются.
Успехов при работе с семантическим ядром. Мы рады, что вы с нами и используете наши инструменты, в которые мы вкладываем очень много труда!
____
Команда Rush Analytics
Правильный подбор ключевых слов
Далее стоит посмотреть на то, по каким словам продвигаются конкуренты, какие вопросы затрагиваются на тематических форумах и в сообществах. Всё это идеи для сайта.
Кроме самих ключевых слов, обязательно уделите внимание их синонимам, так как слова или фразы, выражающие одно и то же понятие, одинаково востребованы и по ним будут переходить пользователи. Количество задействованных формулировок прямо влияет на релевантность страницы
Выбирая те или иные ключевые слова, ориентируйтесь в первую очередь на статистику, предоставляемую поисковыми системами, так как посторонние программы редко дают реальную картину. Данные Яндекса или Google объективны и помогут вам подобрать правильные список ключевых запросов, и чем точнее тематика подобранных слов, тем логичнее будет структурирован ваш интернет-ресурс.
Иногда количество ключевых слов при формировании семантического ядра ограниченно, так как низкочастотные слова непопулярны. Однако старайтесь собрать у себя как можно больше ключевых слов, даже если статистика свидетельствует о том, что по низкочастотным запросам ваш сайт посещают очень редко. Если такими словами пренебрегать, то это приводит к плохим результатам, и вы сами уменьшите популярность сайта.
Отдельного разговора заслуживает подбор ключей на уже работающем сайте, когда надо нарастить трафик.
Просто собрать семантику и подготовить тексты — мало. Семантику надо актуализировать, хотя бы раз в пол года, в некоторых нишах — чаще. Новые запросы, подсказки, вариации старых, тренды, новинки и т.д. В тоже время, если вы видите,ч то конкуренты вяло реагируют на изменения (а это очень частый случай) — это ваш шанс пробиться даже вопреки конкуренции старых трастовых сайтов.
Что такое парсинг?
Начнем с определения. Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.
Парсинг позволяет взять файл в одном формате и преобразовать его данные в более удобоваримую форму, которую можно использовать в своих целях. К примеру, у вас может оказаться под рукой HTML-файл. С помощью парсинга информацию в нем можно трансформировать в «голый» текст и сделать понятной для человека. Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Но в нашем случае парсингу подойдет более узкое и точное определение. Назовем этот процесс методом обработки данных на веб-страницах. Он подразумевает анализ текста, вычленение оттуда необходимых материалов и их преобразование в подходящий вид (тот, что можно использовать в соответствии с поставленными целями). Благодаря парсингу можно находить на страницах небольшие клочки полезной информации и в автоматическом режиме их оттуда извлекать, чтобы потом переиспользовать.
Ну а что такое парсер? Из названия понятно, что речь идет об инструменте, выполняющем парсинг. Кажется, этого определения достаточно.