Как посмотреть, как раньше выглядела страница вконтакте
Содержание:
- Архивы веб-страниц, постоянные
- Чем может грозить отсутствие копии в Яндексе
- Что такое Wayback Machine и Архивы Интернета
- Сайт «компьютерной фирмы»
- Сайт студента-программиста
- Работа с дроп- и освобожденными доменами
- Кто такой Тим Бернерс Ли
- r-tools.org
- Возможности использования веб-архивов
- Cyotek WebCopy
- Как пользоваться веб архивом
- archive.md
Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper. Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы (или расширения), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы, которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов. Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер. Также можно использовать Google Cloud Print. На сервис добавлен новый виртуальный принтер «Сохранить в Google Drive«. В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print, вы сможете сохранить ее PDF-копию в Google Drive. Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от
Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive. Дополнение может сохранять веб-страницы в формате веб-архива (MHT), который поддерживается в IE и Firefox.
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения. Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is. Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива. Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы, а также связанные с ней изображения, CSS и JavaScript. Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB, чтобы загрузить любую веб-страницу в формате EPUB или MOBI. Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве, но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов, решением может стать Wget. Также существует Google Script для автоматической загрузки веб-страниц в Google Drive, но таким образом можно сохранить только HTML-контент.
Чем может грозить отсутствие копии в Яндексе
Само по себе отсутствие копии не будет влиять как-то негативно на продвижение. А вот причины, которые привели к отсутствию могут повредить, поэтому разберитесь с ними.
Чем действительно может обернуться проблема с копиями страниц, так это затруднениями при работе с биржами ссылок.
Например, в Сеопульте сегодня есть параметр, который осуществляет контроль над тем, есть ли сохраненная копия Яндексе. Данный параметр называется NIC — No Index Cache. Он свидетельствует о том, что страница не имеет сохраненной копии. С такого ресурса не будут покупать ссылки, никому не хочется рисковать и платить за то, что может не принести пользы.
Как вы видите, сохраненная копия в Яндексе позволяет решить ряд проблем и оптимизировать использование интернет-трафика. Данные рекомендации позволят оперативно открывать и просматривать их.
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Сайт «компьютерной фирмы»

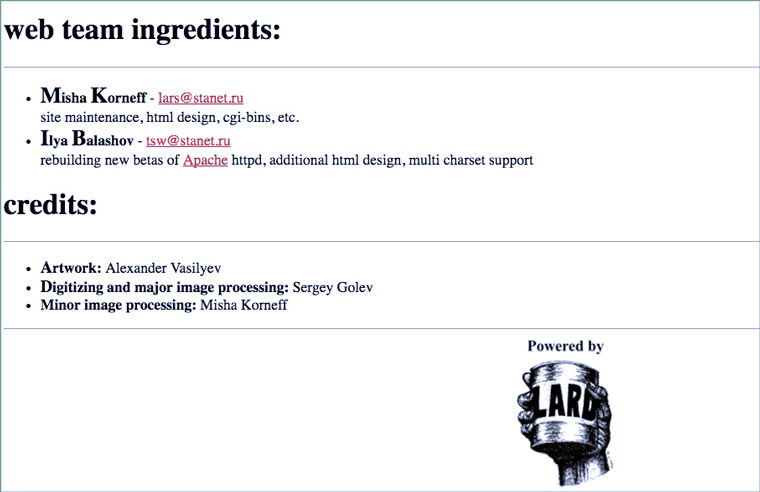
Одно из самых модных и прибыльных занятий в то время было иметь бизнес, связанный с компьютерами. Если компания по продаже колготок могла в то время спокойно жить без сайта (все равно некому заходить), то IT-компаниям собственная страница в интернете была необходима «по статусу».
У таких сайтов были два типичных признака. Первый — страница приветствия с огромным логотипом, контактами и ссылками для переключения на версии сайтах в разных кодировках текста. Если кракозябры превращались в надпись «Вы видите русские буквы?», то значит кодировка выбрана верно и можно смотреть остальные страницы.
Еще на таких сайтах обязательно был раздел с указанием людей, которые работали над его созданием (даже если на нем только две страницы). В данном примере он называется web team ingredients, а Михаил Корнев представляется как Misha Korneff. Также указано, что Сергей Голев занимался Digitizing and Major Image Processing (сканировал фотки).
Сохраненная страница: 19 декабря 1996 года.
Сайт студента-программиста
Домашние страницы «Я Миша, я живу в Нью-Йорке, у меня есть кот» — основа русскоязычного интернета тех лет. Такие сайты создали эмигранты, которые искали общения с бывшими соотечественниками. До 1997 года личных страниц именно жителей России было еще мало.
Например, 22-летний Юрий Блажевич из МФТИ выкладывал на сайте свое резюме и написанные им программы для создания 3D-графики. Там же он рассказывал о своих интересах и собирал ссылки на полезные интернет-сайты.
Через несколько лет парень смог сделать хорошую карьеру и стал ведущим программистом в популярной игре «Блицкриг 2». Но, к сожалению, ушел из жизни в 2007 году.
Сохраненная страница: 7 октября 1997 года.
Работа с дроп- и освобожденными доменами
Дроп-домены — это домены, перехваченные (зарегистрированные) в момент их освобождения. Как правило, хороший домен перехватить достаточно сложно. Под хорошим доменом подразумевается домен который обладает трастом, выражаемый в наличии качественной ссылочной массы либо высокой посещаемостью. После перехвата, сайт необходимо сразу же разместить на хостинге. Но где взять файлы или сам ресурс если у вас нет исходников? Правильно, восстановить то что есть из архива, и использовать либо как временное решение, либо повесить рекламу и получать пассивный доход.
Тоже самое и с освобожденными доменами, за исключением более простой процедуры регистрации, т.к. доменное имя уже освобождено.
Если у такого веб-проекта восстановится посещаемость, то можно разместить рекламные баннеры от партнерок типа Google.Adsense или РСЯ и наслаждаться пассивным доходом. Некоторые продают ссылки.
Кто такой Тим Бернерс Ли
У Бернерса Ли идеальный образ значимой фигуры в IT-индустрии.
Он знаком с технологиями с детства. Его родители были математиками и занимались разработкой одного из первых компьютеров в мире «Марк I».
Учась в Оксфордском королевском колледже, Тим устроил хакерскую атаку на учебное заведение. За это ему запретили пользоваться университетскими десктопами.
Ломал сетку, до того как это стало мэйнстримом.
С начала запуска Веба британец настаивал, что интернет должен быть общедоступным и децентрализованным.
Он даже не попытался заработать на правах на технологию и отказался патентовать ее.
«Если бы эта технология была проприетарной, и я полностью ее контролировал, она бы, скорее всего, не взлетела. Невозможно предложить то, что было бы общедоступным, и при этом вы сохранили контроль над ним», — говорил ученый.
Тим Бернерс Ли слева, Роберт Кайо справа
Помимо причастности к созданию первого сайта, Тим Бернерс Ли считается изобретателем URI, URL, HTTP и HTML. Именно эти технологии можно найти в info.cern.ch.
Если точнее, Бернерс Ли придумал:
- язык разметки HTML для создания веб-страниц
- протокол HTTP для передачи данных в Вебе
- систему унифицированных адресов ресурсов URL для поиска документа или страницы
Эти технологии применяются в интернете и сейчас.
Главная страница сайта
Цель проекта банальна для эпохальной технологии на начальной стадии — упростить работу команде. Марк Цукерберг затем же создавал Facebook, чтобы ему и его одногруппникам было проще общаться друг с другом.
ЦЕРН отклонил идею, но Бернерс Ли проявил настойчивость и продолжил разрабатывать сайт, уже в команде с Робертом Кайо.
Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Ученый предложил сделать так, чтобы гипертекст был доступен одновременно нескольким компьютерам, подключенным к интернету.
«Меня расстраивало, на разных компьютерах содержалась разная информация. И чтобы получить к ней доступ к нескольким источникам, нужно задействовать несколько компьютеров», — говорил Бернерс Ли.
NeXT. Компьютер, на котором был создан первый веб-сайт.
У британца была и более масштабная задача. В ЦЕРН приезжали люди из университетов со всего мира, и привозили с собой компьютеры со всеми видами программного обеспечения. Проблемой была невозможность использования одной программы на компьютерах с разными видами софта.
Бернерс Ли искал ее решение. Изначально он думал о создании ряда программ, берущих информацию из одной системы и конвертирующих ее формат для показа в другой.
Но оптимизировать программы под каждый софт — долго, энергозатратно и дорого. Британец выбрал другой способ: просто дать доступ к информации всем сразу.
Интерфейс Юзнета.
До создания и развития веба популярностью пользовалась компьютерная сеть Юзнет (Usenet).
Она также использовалась для общения и передачи файлов. Но принцип был другим: отличие в том, что Юзнет состоял не из страниц, а из новостных групп и работал по протоколу NTTP.
Кстати, эта сеть стала фундаментом в развитии веба. Именно в ней появились первые интернет-сообщества. Ее пользователи ввели понятия «ник», «смайл», «флуд», «троллинг» и прочие термины, без которых мы не представляем интернет-сообщество.
Бернерс Ли выступает за реорганизацию интернета.
Сегодня Бернерс Ли активно выступает за открытость интернета. К локализации персональных данных пользователей своей страны и идеям суверенного интернета он относится скептически.
Тим говорит, что любое разделение сети на сегменты — очень плохая идея. Причина бурного развития Веба заключалась в том, что интернет был негосударственным, открытым и общедоступным
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Cyotek WebCopy
Cyotek WebCopy — инструмент, позволяющий пользователям копировать полные версии сайтов или только те части, которые им нужны. К сожалению, приложение WebCopy доступно только для Windows, но зато оно является бесплатным. Использовать WebCopy достаточно просто. Откройте программу, введите целевой URL-адрес и все.
Кроме того, WebCopy имеет большое количество фильтров и опций, позволяющих пользователям скачивать только те части сайта, которые им действительно нужны. Эти фильтры могут пропускать такие вещи, как изображения, рекламу, видео и многое другое, что может существенно повлиять на общий размер загрузки.
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».
Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).
Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.
Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Изначально, популярнейший поисковик Гугл назывался BackRub. И выглядел как-то стрёмно и совершенно непонятно.
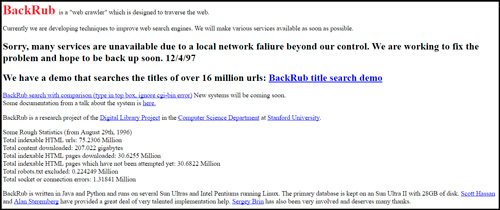
Лишь в 1998 он принял более современный внешний вид. Тогда еще, в конце слова Google стоял восклицательный знак. Представляете, это бета версия, то есть тестовая. Тогда еще разработчики исправляли ошибки и проверяли как все работает. Эх, где мои 16 лет.
Уже тогда здесь было две кнопки. Одна со стандартным поиском, а вторая выбирает случайную страницу с информацией. Если бы администраторы убрали кнопку «Мне повезет», которая пользуется бешенной популярностью и по сей день, то смогли бы получать дополнительный доход с рекламы. Он составил бы примерно 100 миллионов долларов в год. Но, они не жадные.
Кстати о деньгах, компания Mozilla ежегодно получает от гугла 300 миллионов за то, что в их браузере по умолчанию стоит поисковая система от Google.

archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.