Http сервисы: путь к своему сервису. часть 1
Содержание:
- What Are the Various Types of HTTP Request Methods?
- HTTP PUT
- Структура URI
- POST Method
- Сравнение GET и POST
- Этап поиска DNS
- 5 последних уроков рубрики «Разное»
- HTTP-заголовки
- Что такое HTTP¶
- HTTP-запросы
- Examples of Request Message
- Glossary
- 2 Метод GET
- Методы
- HTTP DELETE
- Методы объекта XMLHttpRequest
- HEAD Method
- Тестирование API без документации
- Exec — Выполнение кода, консоль запросов и не только!
- Зачем
- Параметры запроса
What Are the Various Types of HTTP Request Methods?
GET
GET is used to retrieve and request data from a specified resource in a server. GET is one of the most popular HTTP request techniques. In simple words, the GET method is used to retrieve whatever information is identified by the Request-URL.
HEAD
The HEAD technique requests a reaction that is similar to that of GET request, but doesn’t have a message-body in the response. The HEAD request method is useful in recovering meta-data that is written according to the headers, without transferring the entire content. The technique is commonly used when testing hypertext links for accessibility, validity, and recent modification.
POST
Another popular HTTP request method is POST. In web communication, POST requests are utilized to send data to a server to create or update a resource. The information submitted to the server with POST request method is archived in the request body of the HTTP request. The HTTP POST method is often used to send user-generated data to a server. One example is when a user uploads a profile photo.
PUT
PUT is similar to POST as it is used to send data to the server to create or update a resource. The difference between the two is that PUT requests are idempotent. This means that if you call the same PUT requests multiple times, the results will always be the same.
DELETE
Just as it sounds, the DELETE request method is used to delete resources indicated by a specific URL. Making a DELETE request will remove the targeted resource.
PATCH
A PATCH request is similar to POST and PUT. However, its primary purpose is to apply partial modifications to the resource. And just like a POST request, the PATCH request is also non-idempotent. Additionally, unlike POST and PUT which require a full user entity, with PATCH requests, you may only send the updated username.
TRACE
TRACE requests are used to invoke a remote, application loop-back test along the path to the target resource. The TRACE method allows clients to view whatever message is being received at the other end of the request chain so that they can use the information for testing or diagnostic functions.
CONNECT
The CONNECT request method is used by the client to create a network connection to a web server over a particular HTTP. A good example is SSL tunneling. In a nutshell, CONNECT request establishes a tunnel to the server identified by a specific URL.
HTTP PUT
Use PUT APIs primarily to update existing resource (if the resource does not exist, then API may decide to create a new resource or not). If a new resource has been created by the PUT API, the origin server MUST inform the user agent via the HTTP response code response and if an existing resource is modified, either the or ) response codes SHOULD be sent to indicate successful completion of the request.
If the request passes through a cache and the Request-URI identifies one or more currently cached entities, those entries SHOULD be treated as stale. Responses to this method are not cacheable.
The difference between the POST and PUT APIs can be observed in request URIs. POST requests are made on resource collections, whereas PUT requests are made on a single resource.
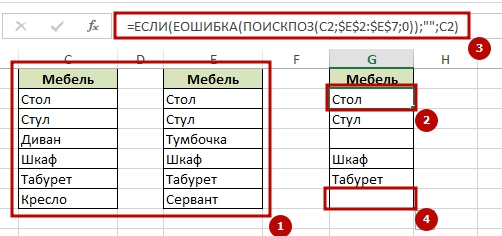
Структура URI
Нагородить можно всякое, но лучшая практика — чтобы все URI имели вид
/:entity
ну, или если у вас api лежит в какой-то папке,
/api/:entity
Здесь:
- entity — название сущности, например, класса или таблицы/представления в БД. Примеры: ,
- id opt. — первичный ключ объекта. Если первичный ключ составной, то части указываются через слэш. Примеры: ,
- params opt. — дополнительные параметры выборки для списочных запросов (фильтрация, сортировка, паджинация и пр.). Форматируются по правилам HTTP GET параметров (функции encodeURIComponent и пр.)
Для разбора части URI до знака вопроса можно использовать регулярку
Ведущий слэш обязателен, т.к. неизвестно, с какого URL будет осуществлён запрос.
POST Method
The POST method is used when you want to send some data to the server, for example, file update, form data, etc. The following example makes use of POST method to send a form data to the server, which will be processed by a process.cgi and finally a response will be returned:
POST /cgi-bin/process.cgi HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Content-Type: text/xml; charset=utf-8 Content-Length: 88 Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
<?xml version="1.0" encoding="utf-8"?> <string xmlns="http://clearforest.com/">string</string>
The server side script process.cgi processes the passed data and sends the following response:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
<html> <body> <h1>Request Processed Successfully</h1> </body> </html>
Сравнение GET и POST
В следующей таблице сравниваются два метода HTTP: GET и POST.
| GET | POST | |
|---|---|---|
| Возврат Кнопка/Перезагрузка | Безвредный | Данные будут повторно отправлены (браузер должен предупредить пользователя о том, что данные будут повторно отправлены) |
| Закладка | Могут быть закладки | Не могут быть закладки |
| Кэширование | Может быть кэширован | Не кэшировать |
| Тип кодировки | application/x-www-form-urlencoded | application/x-www-form-urlencoded или multipart/form-data. Использовать кодировку для двоичных данных |
| История | Параметры остаются в истории браузера | Параметры не сохраняются в истории браузера |
| Ограничения на длину данных | Да, при отправке данных метод GET добавляет данные в URL; длина URL адреса ограничена (Максимальная длина URL составляет 2048 символов) | Не ограничивать |
| Ограничения типа данных | Только символы ASCII | Не ограничивать. Двоичные данные также разрешены |
| Безопасность | GET менее безопасен по сравнению с POST, поскольку отправляемые данные являются частью URL Никогда не используйте GET при отправке паролей или другой конфиденциальной информации! |
POST немного безопаснее, чем GET, потому что параметры не хранятся в истории браузера или в журналах веб сервера |
| Видимость | Данные видны всем в URL | Данные не отображаются в URL |
Этап поиска DNS
Браузер запускает поиск DNS, чтобы получить IP-адрес сервера.
Доменное имя — удобный способ для нас, людей, но Интернет организован таким образом, что компьютеры могут искать точное местоположение сервера по его IP-адресу, который представляет собой набор чисел, например 222.324.3.1 (IPv4).
Во-первых, он проверяет локальный кэш DNS, чтобы узнать, был ли домен разрешен недавно.
В Chrome есть удобный визуализатор DNS-кэша, который вы можете увидеть в
Если там ничего не найдено, браузер использует распознаватель DNS, используя системный вызов gethostbyname POSIX для получения информации о хосте.
gethostbyname
Сначала gethostbyname просматривает локальный файл hosts, который в macOS или Linux находится в /etc/hosts , чтобы проверить, предоставляет ли система информацию локально.
Если это не дает никакой информации о домене, система отправляет запрос на DNS-сервер.
Адрес DNS-сервера сохраняется в системных настройках.
Это 2 популярных DNS-сервера:
- 8.8.8.8: публичный DNS-сервер Google
- 1.1.1.1: DNS-сервер CloudFlare
Большинство людей используют DNS-сервер, предоставленный их интернет-провайдером.
Браузер выполняет DNS-запрос по протоколу UDP.
TCP и UDP являются двумя основополагающими протоколами компьютерных сетей. Они находятся на том же концептуальном уровне, но TCP ориентирован на соединение, а UDP — это протокол без установления соединения, более легкий, используемый для отправки сообщений с небольшими издержками.
DNS-сервер может иметь IP-адрес домена в кэше. Если нет, он спросит корневой DNS-сервер . Это система (состоящая из 13 реальных серверов, распределенных по всей планете), которая управляет всем интернетом.
DNS-сервер не знает адреса каждого доменного имени на планете.
Он знает, где находятся DNS-преобразователи верхнего уровня .
Домен верхнего уровня — это расширение домена: .com , .it , .pizza и так далее.
Как только корневой DNS-сервер получает запрос, он перенаправляет запрос на этот DNS-сервер домена верхнего уровня (TLD).
Скажем, вы ищете ip-calculator.ru. DNS-сервер корневого домена возвращает IP-адрес TLD-сервера .ru.
Теперь наш распознаватель DNS будет кэшировать IP-адрес этого сервера TLD, поэтому ему не нужно будет снова запрашивать его у корневого DNS-сервера.
DNS-сервер TLD будет иметь IP-адреса официальных серверов имен для домена, который мы ищем.
Это DNS-серверы хостинг-провайдера. Их обычно больше 1, чтобы служить резервной копией.
Например:
- ns1.example.com
- ns2.example.com
- ns3.example.com
DNS-распознаватель запускается с первого и пытается запросить IP-адрес домена (также с поддоменом), который вы ищете.
Это основной источник правды для IP-адреса.
Теперь, когда у нас есть IP-адрес, мы можем продолжить наше путешествие.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
HTTP-заголовки
HTTP-сообщение состоит из начальной строки, за которой следуют набор заголовков, пустая строка и некоторые данные. Начальная строка задает действие, требуемое от сервера, тип возвращаемых данных или код состояния.
HTTP-заголовки можно подразделить на три крупные категории: заголовки, посылаемые в запросе, заголовки, посылаемые в ответе, и те, которые можно включать как в запросы, так и в ответы. Заголовки запросов указывают возможности клиента, например, типы документов, которые может обработать клиент, в то время как заголовки ответов предоставляют информацию о возвращенном документе.
Заголовки запросов
К числу наиболее важных HTTP-заголовков, которые можно включать в запросы, но нельзя включать в ответы, относятся:
- Заголовок Accept
-
Это список MIME-типов, принимаемых клиентом, в формате тип/подтип. Элементы списка должны разделяться запятыми:
Accept: text/html, image/gif, */*
Элемент */* указывает, что все типы будут приняты и обработаны клиентом. Если тип запрошенного файла не может быть обработан клиентом, возвращается ошибка HTTP 406 «Not acceptable» (недопустимо).
- Заголовок From
-
Указывает адрес электронной почты в Интернете учетной записи пользователя, под которой работает клиент, направивший запрос:
From: alexerohinzzz@gmail.com
- Заголовок Referer
-
Позволяет клиенту указать адрес (URI) ресурса, из которого получен запрашиваемый URI. Этот заголовок дает возможность серверу сгенерировать список обратных ссылок на ресурсы для будущего анализа, регистрации, оптимизированного кэширования и т.д. Он также позволяет прослеживать с целью последующего исправления устаревшие или введенные с ошибками ссылки:
Referer: http://www.professorweb.ru
- Заголовок User-Agent
-
Представляет собой строку, идентифицирующую приложение-клиент (обычно браузер) и платформу, на которой оно выполняется. Общий формат имеет вид: программа/версия библиотека/версий, но это не неизменный формат:
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17
Эта информация может использоваться в статистических целях, для отслеживания нарушений протокола и для автоматического распознавания клиента. Она позволяет приспособить ответ так, чтобы не нарушить ограниченные возможности конкретного клиента, например неспособность поддерживать HTML-таблицы.
Заголовки ответов
В ответы могут включаться следующие заголовки:
- Заголовок Content-Type
-
Используется для указания типа данных, отправляемых получателю или, в случае метода HEAD, тип данных, который был бы отправлен в ответ на запрос GET:
Content-Type: text/html
- Заголовок Expires
-
Представляет собой момент времени, после которого информация в документе становится недостоверной. Клиенты, использующие кэширование, в частности прокси-серверы, не должны хранить в кэше эту копию ресурса после заданного времени, если только состояние копии не было обновлено более поздним обращением к исходному серверу:
Expires: Fri, 19 Aug 2012 16:00:00 GMT
- Заголовок Location
-
Определяет точное расположение другого ресурса, к которому может быть перенаправлен клиент. Если это значение представляет собой полный URL, сервер возвращает клиенту «redirect» для непосредственного извлечения указанного объекта:
Location: http://www.samplesite.com
Если ссылка на другой файл относится к серверу, должен указываться частичный URL.
- Заголовок Server
-
Содержит информацию о программном обеспечении, используемом исходным сервером для обработки запроса:
Server: Microsoft-IIS/7.0
Общие заголовки
Несколько заголовков могут включаться как в запрос, так и в ответ, например:
- Заголовок Date
-
Используется для установки даты и времени создания сообщения:
Date: Tue, 16 Aug 2012 18:12:31 GMT
- Заголовок Connection
-
В НТТР/1.0 мы могли использовать в запросе заголовок Connection, указывая, что хотим сохранить соединение после отправки ответа. Теперь такое поведение принято по умолчанию, и в HTTP/1.1 можно использовать заголовок Connection, чтобы указать, что постоянное соединение не нужно:
Connection: close
Что такое HTTP¶
HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». Изначально этот протокол использовался для передачи гипертекстовых документов в формате HTML. Сегодня он используется для передачи произвольных данных.
В основе HTTP — клиент-серверная структура передачи данных․ Клиент формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передается клиенту.
HTTP не шифрует передаваемую информацию. Для защиты передаваемых данных используется расширение HTTPS (Hyper Text Transfer Protocol Secure), которое “упаковывает” передаваемые данные в криптографический протокол SSL или TLS.
HTTP-запросы
Каждый клиент посылает запрос, и сервер на него отвечает. Все запросы и ответы состоят из трех частей, а именно: строки запроса или ответа, секции заголовков и тела сущности (любого содержания, отправляемого вместе с сообщением, например, страницы HTML для отображения в браузере или данных формы, пересылаемых на сервер).
Клиент связывается с сервером в назначенном номере порта (по умолчанию равном 80) и запрашивает у сервера документ, задавая HTTP-команду, называемую методом, за которой следует адрес документа и номер версии HTTP. Клиент также отправляет серверу необязательную информацию в заголовках, чтобы сообщить серверу о своей конфигурации и приемлемых для него форматах документов. Информация заголовка дается в одной строке вместе с именем и значением заголовка. После заголовков клиент посылает пустую строку. Затем клиент отправляет дополнительные данные. Это могут быть данные формы, отправляемые на сервер методом POST, или файл, копируемый на сервер методом PUT.
Запросы клиентов подразделяются на три секции. Первая строка сообщения всегда должна содержать HTTP-команду, называемую методом, за которой следует URI, идентифицирующий файл или ресурс, запрашиваемый клиентом, и номер версии HTTP:
GET /default.aspx HTTP/1.1
Теперь исследуем каждую из этих секций. Метод — это HTTP-команда, начинающая первую строку запроса клиента. Метод информирует сервер о цели запроса клиента. Для HTTP определены семь методов: GET, HEAD, POST, OPTIONS, PUT, DELETE и TRACE, но HTTP-серверы могут также реализовать методы расширения, не определенные протоколом HTTP. Заметим, что названия методов зависят от регистра клавиатуры, поэтому, например, слово get не будет распознано как допустимый метод.
Метод GET используется для запроса информации, расположение которой на сервере определяется заданным URI. Этот метод широко применяется браузерами, чтобы извлекать документы для просмотра. Результат запроса GET генерируется разными способами. Это может быть файл, доступный с сервера, вывод программы, вывод, полученный на устройстве, и т. д.
Когда клиент в своем запросе использует метод GET, сервер отправляет ответ, содержащий строку состояния, заголовки и метаданные. Если сервер не может обработать запрос из-за ошибки или отсутствия авторизации, он отправляет объяснение в текстовом виде, помещая его в ответе в секцию данных.
Секция тела о сути запроса GET всегда остается пустой. Запрошенный клиентом ресурс (файл или программа) идентифицируется по его полному пути на сервере. Любая дополнительная информация, например, значения из формы, которую клиенту нужно отправить серверу, присоединяется вслед за URI как строка запроса:
GET /default.aspx?name=Alex HTTP/1.1
Метод HEAD функционально аналогичен методу GET, не считая того, что сервер ничего не помещает в секцию данных ответа. Методом HEAD запрашивается только заголовочная информация по файлу или ресурсу. Для запроса HEAD HTTP-сервер должен отправить в заголовках ту же информацию, которую он бы отправил в ответ на запрос GET. Данный метод используется, если клиенту нужна информация о документе, но не нужно получать сам документ.
Метод POST позволяет отправить данные серверу в клиентском запросе. Эти данные посылаются программе обработки данных, к которой у сервера есть доступ. Метод POST может использоваться для многих приложений, например, для обеспечения входных данных сетевых служб, программ интерфейса командной строки и т.д. Данные отправляются на сервер в секции тела сути клиентского запроса. Обработав запрос POST и заголовки, сервер передает это тело программе, указанной в URI.
В методе OPTIONS запрашивается информация о поддержке HTTP на Web-cepвeре. Метод OPTIONS может применяться с URL, чтобы извлечь информацию о конкретном документе или, с групповым символом *, чтобы получить информацию о возможностях сервера в целом. Информация возвращается в заголовках ответа.
Examples of Request Message
Now let’s put it all together to form an HTTP request to fetch hello.htm page from the web server running on tutorialspoint.com
GET /hello.htm HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
Here we are not sending any request data to the server because we are fetching a plain HTML page from the server. Connection is a general-header, and the rest of the headers are request headers. The following example shows how to send form data to the server using request message body:
POST /cgi-bin/process.cgi HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Content-Type: application/x-www-form-urlencoded Content-Length: length Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive licenseID=string&content=string&/paramsXML=string
Here the given URL /cgi-bin/process.cgi will be used to process the passed data and accordingly, a response will be returned. Here content-type tells the server that the passed data is a simple web form data and length will be the actual length of the data put in the message body. The following example shows how you can pass plain XML to your web server:
POST /cgi-bin/process.cgi HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Content-Type: text/xml; charset=utf-8 Content-Length: length Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive <?xml version="1.0" encoding="utf-8"?> <string xmlns="http://clearforest.com/">string</string>
Previous Page
Print Page
Next Page
Glossary
Safe Methods
As per HTTP specification, the GET and HEAD methods should be used only for retrieval of resource representations – and they do not update/delete the resource on the server. Both methods are said to be considered “safe“.
This allows user agents to represent other methods, such as POST, PUT and DELETE, in a unique way so that the user is made aware of the fact that a possibly unsafe action is being requested – and they can update/delete the resource on server and so should be used carefully.
Idempotent Methods
The term idempotent is used more comprehensively to describe an operation that will produce the same results if executed once or multiple times. Idempotence is a handy property in many situations, as it means that an operation can be repeated or retried as often as necessary without causing unintended effects. With non-idempotent operations, the algorithm may have to keep track of whether the operation was already performed or not.
In HTTP specification, The methods GET, HEAD, PUT and DELETE are declared idempotent methods. Other methods OPTIONS and TRACE SHOULD NOT have side effects, so both are also inherently idempotent.
References:
https://www.w3.org/Protocols/rfc2616/rfc2616.txthttp://tools.ietf.org/html/rfc6902
2 Метод GET
Напишем наш запрос.
GET http://www.site.ru/news.html HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n \r\n
Данный запрос говорит нам о том, что мы хотим получить содержимое страницы по адресу http://www.site.ru/news.html, использую метод GET. Поле Host говорит о том, что данная страница находится на сервере www.site.ru, поле Referer говорит о том, что за новостями мы пришли с главной страницы сайта, а поле Cookie говорит о том, что нам была присвоена такая-то кука. Почему так важны поля Host, Referer и Сookie? Потому что нормальные программисты при создании динамических сайтов проверяют данные поля, которые появляются в скриптах (РНР в том числе) в виде переменных. Для чего это надо? Для того, например, чтобы сайт не грабили, т.е. не натравливали на него программу для автоматического скачивания, или для того, чтобы зашедший на сайт человек всегда попадал бы на него только с главной страницы и.т.д.
Теперь давайте представим, что нам надо заполнить поля формы на странице и отправить запрос из формы, пусть в данной форме будет два поля: login и password (логин и пароль),- и, мы естественно знаем логин и пароль.
GET http://www.site.ru/news.html?login=Petya%20Vasechkin&password=qq HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n \r\n
Логин у нас «Petya Vasechkin» Почему же мы должны писать Petya%20Vasechkin? Это из=за того, что специальные символы могут быть распознаны сервером, как признаки наличия нового параметра или конца запроса и.т.д. Поэтому существует алгоритм кодирования имен параметров и их значений, во избежание оштбочных ситуаций в запросе. Полное описание данного алгоритма можно найти здесь, а в PHP есть функции rawurlencode и rawurldecode для кодирования и декодирования соответственно. Хочу отметеить, что декодирование РНР делает сам, если в запросе были переданы закодированные параметры. На этом я закону первую главу знакомства c протоколом HTTP. В следуючей главе мы рассмотрим построение запросов типа POST (в переводе с английского — «отправить»), что будет гораздо интереснее, т.к. именно данный тип запросов используется при отправке данных из HTML форм.
Методы
С помощью URL, мы определяем точное название хоста, с которым хотим общаться, однако какое действие нам нужно совершить, можно сообщить только с помощью HTTP метода. Конечно же существует несколько видов действий, которые мы можем совершить. В HTTP реализованы самые нужные, подходящие под нужды большинства приложений.
Существующие методы:
GET: получить доступ к существующему ресурсу. В URL перечислена вся необходимая информация, чтобы сервер смог найти и вернуть в качестве ответа искомый ресурс.
POST: используется для создания нового ресурса. POST запрос обычно содержит в себе всю нужную информацию для создания нового ресурса.
PUT: обновить текущий ресурс. PUT запрос содержит обновляемые данные.
DELETE: служит для удаления существующего ресурса.
Данные методы самые популярные и чаще всего используются различными инструментами и фрэймворками. В некоторых случаях, PUT и DELETE запросы отправляются посредством отправки POST, в содержании которого указано действие, которое нужно совершить с ресурсом: создать, обновить или удалить.
Также HTTP поддерживает и другие методы:
HEAD: аналогичен GET. Разница в том, что при данном виде запроса не передаётся сообщение. Сервер получает только заголовки. Используется, к примеру, для того чтобы определить, был ли изменён ресурс.
TRACE: во время передачи запрос проходит через множество точек доступа и прокси серверов, каждый из которых вносит свою информацию: IP, DNS. С помощью данного метода, можно увидеть всю промежуточную информацию.
OPTIONS: используется для определения возможностей сервера, его параметров и конфигурации для конкретного ресурса.
HTTP DELETE
As the name applies, DELETE APIs are used to delete resources (identified by the Request-URI).
A successful response of DELETE requests SHOULD be HTTP response if the response includes an entity describing the status, if the action has been queued, or if the action has been performed but the response does not include an entity.
DELETE operations are idempotent. If you DELETE a resource, it’s removed from the collection of resources. Repeatedly calling DELETE API on that resource will not change the outcome – however, calling DELETE on a resource a second time will return a 404 (NOT FOUND) since it was already removed. Some may argue that it makes the DELETE method non-idempotent. It’s a matter of discussion and personal opinion.
If the request passes through a cache and the Request-URI identifies one or more currently cached entities, those entries SHOULD be treated as stale. Responses to this method are not cacheable.
Example request URIs
- HTTP DELETE http://www.appdomain.com/users/123
- HTTP DELETE http://www.appdomain.com/users/123/accounts/456
Методы объекта XMLHttpRequest
open()
Варианты вызова:
- open( method, URL )
- open( method, URL, async )
- open( method, URL, async, userName )
- open( method, URL, async, userName, password )
Первый параметр method — HTTP-метод. Как правило, используется GET либо POST, хотя доступны и более экзотические, вроде TRACE/DELETE/PUT и т.п.
URL — адрес запроса. Можно использовать не только HTTP/HTTPS, но и другие протоколы, например FTP и FILE://. При этом есть ограничения безопасности, так называемая
«same origin policy»: запрос со страницы можно отправлять только на тот домен и порт, с которого она пришла.
Ниже это ограничение и способы обхода будут рассмотрены подробнее.
async = true задает асинхронные запросы, эта тема была поднята выше.
userName, password — данные для HTTP-авторизации.
send()
Отсылает запрос. Аргумент — тело запроса. Например, GET-запроса тела нет, поэтому используется , а для POST-запросов тело содержит параметры запроса.
abort()
Вызов этого метода xmlhttp.abort() обрывает текущий запрос.
Здесь есть одно НО для браузера Internet Explorer. Успешный вызов abort() на самом деле может не обрывать соединение,
а оставлять его в подвешенном состоянии на некоторый таймаут (20-30 секунд). Отловить такие повисшие соединения можно через прокси для отладки, например, Fiddler.
У браузера есть лимит: не более 2 одновременных соединений с одним доменом-портом. Т.е, если два соединения уже висят (и отвиснут по таймауту), то третье открыто не
будет, пока одно из них не умрет. Надеюсь, Вы с такой проблемой не столкнетесь. Ее можно обойти использованием кросс-доменных XmlHttpRequest.
setRequestHeader(name, value)
Устанавливает заголовок name запроса со значением value. Если заголовок с таким name уже есть — он заменяется.
Например,
xmlhttp.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
HEAD Method
The HEAD method is functionally similar to GET, except that the server replies with a response line and headers, but no entity-body. The following example makes use of HEAD method to fetch header information about hello.htm:
HEAD /hello.htm HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
The server response against the above HEAD request will be as follows:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
You can notice that here server the does not send any data after header.
Тестирование API без документации
Если Вам по какой-то причине предстоит проделать эту неблагодарную работу,
определетесь, насколько всё плохо. Какая у Вас есть информация об объекте
тестирования.
Известно ли какие порты для Вас открыты? Знаете ли Вы нужные endpoints?
Сканирование портов
Если дело совсем труба — просканируйте порты, например, с помощью netcat.
Открытые порты сохраните в файл
openports.txt
nc -z -v answerit.ru 1-10000 2>&1 | grep succeeded > openports.txt
Эта операция займёт довольно много времени. Можете почитать советы по работе с
Nmap и Netcat
, например, следующие:
Перебор запросов
Если Вам известен нужный порт и соответствующий endopoint переберите все возможные HTTP
. Начните с наиболее очевидных:
-
POST
-
PUT
- GET
Для ускорения процесса напишите скрипт на
Bash
или
Python
.
В худшем случае, когда ни порт ни endpoints неизвестны Вам, скорее всего придётся перебирать
все открытые порты и генерировать endpoints, которые подходят по смыслу.
Разработчики обычно не особо заморачиваются и закладывают минимально-необходиму информацию.
Так что включите воображение и попробуйте придумать endpoints опираясь на бизнес логику
и принятые в Вашей компании стандарты.
Если ни endpoints ни бизнес логика Вам неизвестны, то у меня есть подозрение, что Вы
тестируете API с не самыми хорошими намерениями.
Exec — Выполнение кода, консоль запросов и не только!
Незаменимый инструмент администратора БД и программиста:
Выполняйте произвольный код из режима 1С Предприятие; сохраняйте/загружайте часто используемые скрипты; выполняйте запросы с замером производительности запроса в целом и каждой из временных таблиц в частности, а также с просмотром содержимого временных таблиц; произвольным образом изменяйте любые объекты БД, редактируя даже не вынесенные на формы реквизиты и записывая изменения в режиме «ОбменДанными.Загрузка = Истина»; легко узнавайте ИД объектов БД; выполняйте прямые запросы к SQL с замером производительности и не только!
5 стартмани
Зачем
Надеюсь, читающий уже понимает, зачем ему вообще нужен именно REST api, а не какой-нибудь монстр типа SOAP. Вопрос в том, зачем соблюдать какие-то стандарты и практики, если браузеры вроде бы позволяют делать что хочешь.
- Стандарт HTTP это стандарт. Его несоблюдение вредно для кармы и ведёт к постоянным проблемам с безопасностью, кэшированием и прочими «закидонами» браузеров, которые совсем не закидоны, а просто следование стандарту.
- Велосипеды со всякими невозможно нормально тестировать и отлаживать
- Поддержка большим количеством готовых клиентских библиотек на все случаи жизни. Те, кто будет вашим api пользоваться, скажут большое человеческое спасибо.
- Поддержка автоматизированного интеграционного тестирования. Когда сервер на любые запросы отдаёт — ну, это такое себе развлечение.
Параметры запроса
Мы привыкли, что на нашем сайте каждый PHP-сценарий отвечает за одну страницу. Посетитель сайта вводит в адресную строку путь, который состоит из имени домена и имени PHP-сценария. Например, так: .
Но как быть, если одна страница должна показывать разную информацию?
На сайте дневника наблюдений за погодой мы сделали отдельную страницу, чтобы показывать на ней информацию о погоде из истории за один конкретный день. То есть страница одна, но показывает разные данные, в зависимости от выбранного дня.
Также пользователи хотят добавить в закладки адреса страниц с нужными им днями. Получается, что имея только один сценарий сделать страницу, способную показывать дневник погоды за любой день невозможно? Вовсе нет!
Из чего состоит URI
URI — это уникальный идентификатор ресурса. Ресурс в нашем случае — это полный путь до страницы сайта. И вот как может выглядеть ресурс для показа погоды за конкретный день:
Разберем, из чего состоит этот URI.
Во-первых, здесь есть имя домена: .
Затем идёт имя сценария:
А всё что идёт после — это параметры запроса.
Параметры запроса — это как бы дополнительные атрибуты адреса страницы. Они отделяются от имени страницы знаком запроса. В примере выше параметр запроса только один: date=2017-10-30.
Имя этого параметра:, значение: .
Параметров запроса может быть несколько, тогда они разделяются знаком амперсанда:
В примере выше указывается два аргумента: дата и единица измерения температуры.
Параметры запроса как внешние переменные
Теперь в адресе страницы используются параметры запроса, но какая нам от этого польза? Она состоит в том, что если имя страницы вызывает к исполнению соответствующий PHP-сценарий, то параметры запроса превращаются в специальные внешние переменные в этом сценарии. То есть, если в адресе присутствуют такие параметры, то их легко получить внутри кода сценария и выполнить с ними какие-нибудь действия. Например, показать погоду за конкретный день в выбранных единицах измерения.
Получение параметров запроса
Если есть внешние переменные, то как их прочитать?
Все параметры запроса находятся в специальном, ассоциативном массиве , а значит сценарий, вызванный с таким адресом: будет иметь в этом массиве два значения с ключами и .
Запрос на получение данных за выбранный день выглядит так:
В первой строчке примера выше мы получаем значение параметра , а если он отсутствует, то используем текущую дату в качестве выбранного дня.Никогда не полагайтесь на существование параметра в массиве и делайте проверку либо функцией , либо как в этом примере.
В этом задании вы сможете потренироваться использовать .
Формирование URI с параметрами запроса
Иногда нужно совершить обратную операцию: сформировать адрес страницы, включив туда нужные параметры запроса из массива.
Скажем, на странице погодного дневника надо поставить ссылку на следующий и предыдущий день. Нужно также сохранить выбранную единицу измерений. То есть необходимо сохранить текущие параметры запроса, поменять значение одного из них (день), и сформировать новую ссылку.
Вот как это можно сделать:
Здесь мы использовали две функции:
- — получает имя текущего сценария;
- — преобразует ассоциативный массив в строку запроса.