Особенности индексации сайтов
Содержание:
- Как выглядит мета-тег и где его посмотреть
- Директивы Meta Robots, которые стоит использовать в SEO
- Суть тега
- Пошаговый алгоритм работы с сервисом:
- Атрибуты¶
- What are robot meta tags?
- Распространенные ошибки
- What Is Robots.txt?
- Что такое файл Robots.txt?
- NOFOLLOW в ссылках
- Нужно ли удалять публикации, отмеченные мета-тегом с канала
- Как закрыть внешние ссылки от индексации
- Мета тег description
- Мета теги для социальных сетей
- How to Set Up Robots Meta Tags and X‑Robots-Tag
- Выводы
Как выглядит мета-тег и где его посмотреть
Вообще мета-тег — это обычный тег html, который используется при создании веб-страниц для хранения информации, предназначенной для браузеров и поисковых систем. Теоретически в мета-теге может содержаться абсолютно любая информация, но в контексте публикаций в Дзене обычно имеются в виду мета-теги <meta name=»robots» content=»noindex» /> или <meta property=»robots» content=»none» />.
Чтобы посмотреть, есть ли мета-тег на обычной странице, нужно кликнуть правой кнопкой мыши в любом месте страницы, и в меню выбрать пункт «Просмотр кода страницы».
Откроется окно с исходным кодом страницы, где среди множества понятных и не очень строчек можно найти нужные нам мета-теги.
 Здесь немного другой мета-тег — видите «all»? Об этом поговорим чуть ниже.
Здесь немного другой мета-тег — видите «all»? Об этом поговорим чуть ниже.
Мета-тега на странице может и не быть или он может быть немного другим, и это может менять его значение.
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Для решения проблемы вам следует использовать инструкцию следующего вида:
Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска. К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов
Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке html-документа следующую директиву:
Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Суть тега
Тег <noindex> – это HTML-тег, который запрещает Яндексу индексировать ту или иную область страницы сайта. Для поисковой системы Google этот тег не работает, более того, в Google вообще не предусмотрена возможность исключения части текста страницы из индекса.
Заблуждение №1. Основная ошибка людей, которые используют этот тег, заключается в убеждении, что если часть какого-либо текста помещена между открывающимся и закрывающимся тегом <noindex>, то робот Яндекса не станет читать и анализировать этот текст.
Единственное, что данный тег запрещает – это помещение содержимого в индексную базу, но это содержимое в любом случае будет прочитано и проанализировано роботом.
Пример: На странице вашего сайта расположен некоторый текст, использующий прямые вхождения предложений из других сторонних источников. Следовательно, эти предложения снижают уникальность вашего текста, а вам необходимо, чтобы уникальность была 100%. Вы решаете закрыть эти предложения тегом <noindex>, чтобы Яндекс считал ваш текст уникальным. Это заблуждение.
Абсолютно весь текст вашей страницы будет прочитан и обработан роботом, и ему будет известно, что текст вашей страницы не является уникальным.
Сама суть тега <noindex> – «не индексировать», значит запрета на чтение нет.
Предположим, что поисковый робот зашел на вашу страницу и начал сканировать содержимое. В какой-то момент робот находит открытие тега <noindex>, что является сигналом роботу – дальше текст не индексировать. Но чтобы найти то место кода, где тег <noindex> закрывается, роботу необходимо прочесть содержимое, идущее после открытия данного тега. Следовательно, даже теоретически нельзя запретить роботам читать содержимое с помощью тега <noindex>.
Для чего же тогда нужен тег <noindex>?
Он нужен непосредственно для того, чтобы запретить роботу выдавать в выдаче своей поисковой системы какую-либо информацию. Это могут быть, к примеру, контакты, которые по каким-либо причинам не должны отображаться в выдаче.
Заблуждение №2. Ещё одно заблуждение, которое часто встречается среди владельцев сайтов, – это мнение, что ссылка, помещенная в тег <noindex>, не будет учтена поисковым роботом. Как я говорил ранее, всё, что находится внутри тега <noindex>, будет прочитано и проанализировано роботом Яндекса. И ссылки не являются исключением. Единственное отличие размещенных обычным образом ссылок от ссылок в теге <noindex> – это то, что текст (анкор) ссылки не будет проиндексирован.
Существует два способа написания тега <noindex> в коде:
- <noindex>Текст, запрещённый к индексированию</noindex>
- <!–noindex–>Текст, запрещённый к индексированию<!–/noindex–>
Второй вариант более верный. Так как тег не входит в официальную спецификацию языка разметки HTML, то его присутствие в коде может вызвать недопонимание у других поисковых систем, которые будут считать его наличие за ошибку. Чтобы сделать код страницы валидным, для всех поисковых роботов рекомендуется использовать закомментированный вариант написания
Яндекс такое написание распознает, а другие поисковые роботы не будет обращать внимание на его присутствие
Пошаговый алгоритм работы с сервисом:
Создание задачи.
1. Чтобы создать задачу, необходимо перейти во вкладку Мета сканер и нажать кнопку «Создать новую задачу»:
2. Шаг первый: Название задачи.
Здесь необходимо ввести название задачи (обязательное поле) и добавить домен сайта, страницы которого вы хотите отслеживать.
Затем выберите тип оповещений. Активировав данную опцию, вы будете получать письма с уведомлениями об изменениях на сайте на указанную в вашем аккаунте почту
Обратите внимание, что для получения этого письма, вы должны быть подписаны на получение рассылки “уведомлений”. Это можно проверить в настройках на странице “Мой аккаунт”
Выберите «Все», если хотите чтобы на почту пришло уведомление об изменениях во всех зонах
Если Вам важно отслеживать изменения только в одной или нескольких зонах, а остальные не интересны — отметьте их галочкой
Далее выберите интервал проверки.
Интервалы:
- Ежедневно — задача будет обновляться ежедневно
- Еженедельно — задача будет обновляться раз в неделю
- Раз в месяц — задача будет обновляться раз в месяц
- В ручном режиме — задача будет обновляться только при ручном запуске
3. Шаг второй: Настройки сканирования
На этом шаге можно выбрать через какой USER AGENT хотите сканировать ваш сайт.
Вторая настройка на этом шаге — это игнорирование числовых значений.
Если на вашем сайте в мета-теги автоматически подставляются числовые параметры (например, цена или количество товаров) и вы не считаете это важными изменениями — включите эту опцию и наши роботы будут игнорировать такие изменения.
Пример: если цена в теге Title изменится с 999 на 1000, то вы не получите уведомление об этом изменении в Title
4.Шаг третий: URL и цена. Загружаем URL.
Можно загрузить списком, с помощью sitemap либо через файл. Поддерживаемые форматы файла: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку:
К каждому из добавленных URL можно добавить текст со страницы, который будет отслеживаться Мета сканером (максимальная длина текста составляет 256 символов).
Затем нажимаем «Запустить задачу»:
Атрибуты¶
- Задаёт кодировку документа.
- Устанавливает значение атрибута, заданного с помощью или .
- Предназначен для конвертирования метатега в заголовок HTTP.
- Имя метатега, также косвенно устанавливает его предназначение.
charset
Указывает кодировку документа. Атрибут введён в HTML5 и предназначен для сокращения формы , которая задавала кодировку в предыдущих версиях HTML и XHTML.
Синтаксис
Значения
Название кодировки, например UTF-8.
Значение по умолчанию
Нет.
content
устанавливает значение атрибута, заданного с помощью или . Атрибут может содержать более одного значения, в этом случае они разделяются запятыми или точкой с запятой.
Некоторые значения атрибута для , предназначенных для поисковых роботов, приведены в табл. 1.
| Значение | Описание |
|---|---|
| Разрешает роботу индексировать данную страницу. | |
| Запрещает роботу индексировать текущую страницу. Она не попадает в базу поисковика и её невозможно будет найти через поисковую систему. | |
| Разрешает роботу переходить по ссылкам на данной странице. | |
| Запрещает роботу переходить по ссылкам на данной странице. При этом всем ссылкам не передаётся ТИЦ (тематический индекс цитирования) и PagePank. | |
| Запрещает роботу кэшировать данную страницу. |
Допустимые значения атрибута для , которые предназначены для управления просмотром сайта на мобильных устройствах, приведены в табл. 2.
| Значение | Допустимые значения | Описание |
|---|---|---|
| device-width или целое положительное число | Устанавливает ширину области просмотра в пикселях. | |
| device-height или целое положительное число | Устанавливает высоту области просмотра в пикселях. | |
| Число от 0.0 до 10.0 | Устанавливает соотношение между шириной устройства (device-width в портретном режиме или device-height в ландшафтном режиме) и размером области просмотра. | |
| Число от 0.0 до 10.0 | Задаёт максимальное значение масштаба. Должно быть больше или равно minimum-scale, в противном случае игнорируется. | |
| Число от 0.0 до 10.0 | Задаёт минимальное значение масштаба. Должно быть меньше или равно maximum-scale, в противном случае игнорируется. | |
| yes или no | Если указано no, то пользователь не сможет масштабировать веб-страницу. По умолчанию используется yes. |
Синтаксис
Значения
Строка символов, которую надо взять в одинарные или двойные кавычки.
Значение по умолчанию
Нет.
http-equiv
Браузеры преобразовывают значение атрибута , заданное с помощью , в формат заголовка ответа HTTP и обрабатывают их, как будто они прибыли непосредственно от сервера.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Тип кодировки документа.
Устанавливает дату и время, после которой информация в документе будет считаться устаревшей.
Способ кэширования документа.
- Загружает другой документ в текущее окно браузера.
Значение по умолчанию
Нет.
name
Устанавливает идентификатор метатега для пары «». Одновременно использовать атрибуты и не допускается.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Имя автора документа.
- Описание текущего документа.
- Список ключевых слов, встречающихся на странице.
- Управляет просмотром сайта на мобильных устройствах.
Значение по умолчанию
Нет.
Robots meta directives (sometimes called «meta tags») are pieces of code that provide crawlers instructions for how to crawl or index web page content. Whereas robots.txt file directives give bots suggestions for how to crawl a website’s pages, robots meta directives provide more firm instructions on how to crawl and index a page’s content.
There are two types of robots meta directives: those that are part of the HTML page (like the meta robotstag) and those that the web server sends as HTTP headers (such as x-robots-tag). The same parameters (i.e., the crawling or indexing instructions a meta tag provides, such as «noindex» and «nofollow» in the example above) can be used with both meta robots and the x-robots-tag; what differs is how those parameters are communicated to crawlers.

Meta directives give crawlers instructions about how to crawl and index information they find on a specific webpage. If these directives are discovered by bots, their parameters serve as strong suggestions for crawler indexation behavior. But as with robots.txt files, crawlers don’t have to follow your meta directives, so it’s a safe bet that some malicious web robots will ignore your directives.
Below are the parameters that search engine crawlers understand and follow when they’re used in robots meta directives. The parameters are not case-sensitive, but do note that it is possible some search engines may only follow a subset of these parameters or may treat some directives slightly differently.
Распространенные ошибки
Мы рассмотрели разные способы закрытия от индексации, но сложности встречаются у каждого пути. Давайте рассмотрим самые популярные из них.
Неправильные способы закрытия от индексации:
- пользоваться тегом <noindex> и забыть, что только Yandex его распознает, а для Google контент будет полностью проиндексирован.
- пытаться удалить сайт из index с помощью Disallow в robots.txt. Да, к вам поисковый робот больше не зайдет, но и из поиска никуда не денется. Для полного удаления из index, воспользуйтесь Google Search Console.
- пытаться удалить страницу сайта из index с помощью robots.txt + мета-тега robots. Мы закрыли страницу от сканирования роботами, но она уже находится в index. При следующем сканировании они не смогут зайти на ресурс и увидеть мета-тег, чтобы убрать его из index. По итогу она так и останется видимой для поисковой системы.
Как этого избежать?
После прочтения данной статьи:
Определите что именно вам нужно скрыть
Это может быть директория, документ или часть контента.
Четко под свои задачи, выберите нужный способ решения.
Перечитайте о нем более детально в этой статье и возьмите во внимание нюансы использования и внедрения.
What Is Robots.txt?
A robots.txt file tells crawlers what should be crawled.
It’s part of the robots exclusion protocol (REP).
Googlebot is an example of a crawler.
Google deploys Googlebot to crawl websites and record information on that site to understand how to rank the site in Google’s search results.
You can find any site’s robots.txt file by add /robots.txt after the web address like this:
www.mywebsite.com/robots.txt
Here is what a basic, fresh, robots.txt file looks like:
The asterisk * after user-agent tells the crawlers that the robots.txt file is for all bots that come to the site.
Advertisement
Continue Reading Below
The slash / after “Disallow” tells the robot to not go to any pages on the site.
Here is an example of Moz’s robots.txt file.
You can see they are telling the crawlers what pages to crawl using user-agents and directives. I’ll dive into those a little later.
Что такое файл Robots.txt?
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Чем полезен файл Robots.txt?
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
Как создать файл Robots.txt?
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
Директивы для сканирования поисковыми системами
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
Правильное использование универсальных символов
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href=»url» rel=»nofollow»>ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте — нет.
Остановимся подробнее на распределении и передаче веса в Google.
Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel=»nofollow», а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда
Давайте представим немного, как видит всемирную паутину поисковая система. Все сайты связаны между собой ссылками, абсолютно все. Первый ссылается на второй, второй на третий … тысячный на тысяча первый и миллион какой-то в итоге обязательно будет ссылаться на первый.
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel=»nofollow». Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel=»nofollow», сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
Таким образом, если первый сайт не закрыл ссылку атрибутом rel=»nofollow», то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Выдержка из раздела Помощь Яндекса:
Выдержка из раздела Справка Google:
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel=»nofollow» не только в самих ссылках, т.е
в теге , но и везде, на что только хватает фантазии. И в теге
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel=»nofollow» можно использовать только в теге , и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel=»nofollow», а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку
Теперь уделим внимание тегу noindex.
Нужно ли удалять публикации, отмеченные мета-тегом с канала
Итак, вы обнаружили мет-тег, но обращение в техподдержку не помогло.
Давайте рассуждать логически:
- Если статья не получает показы, то её никто не увидите в Дзене.
- Если статья не индексируется поисковыми системами, то на неё не будут переходить из поиска.
Т.е. фактически статья не существует. Удалять её или нет — это ваше личное решение.
Но если у вас есть свой сайт или блог на другой платформе, то я бы рекомендовал перенести статью туда. И удалить. Зачем ей бессмысленно болтаться там, где ей не рады.
Если какой-то трафик на статье есть (а, вдруг?!), то имеет смысла подождать пока ей не исполнится три месяца и тогда удалить.
Собственно, я стал активно публиковать статьи на prozen.ru после того, как мне пришлось перенести несколько статей, получивших «ноиндекс» в Дзене.
Как закрыть внешние ссылки от индексации

Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex
Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя
Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.. Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега
Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=”nofollow”, это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
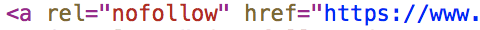
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами
Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт
Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста. В этом случае и текст и ссылка не будет доступна к индексации
Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс
На этом сегодня всё, всем удачи и до новых встреч!
Мета тег description
Мета-описание (meta description) – также находится в <head> веб-страницы и обычно (хотя далеко не всегда) отображается в сниппете поисковой выдачи вместе с заголовком и URL-адресом страницы.
Например, это мета-описание данной статьи:
И да, само по себе метаописание не является фактором ранжирования. Но для любого вебмастера, старающегося увеличить количество переходов из поиска и улучшить поисковую выдачу своего бренда, это уникальная возможность.
Description занимает большую часть сниппета поисковой выдачи и приглашает пользователей щёлкнуть именно по вашей ссылке, обещая чёткое и комплексное решение их запроса.
Описание влияет на количество получаемых вами кликов, а также может улучшить CTR и снизить показатель отказов, если содержание страницы действительно соответствует обещаниям. Вот почему описание должно быть в равной степени реалистичным, привлекательным и чётко отражать содержание.
Если ваше описание содержит ключевые слова, использованные человеком в своём поисковом запросе, они будут выделены в поисковой выдаче жирным шрифтом
Это помогает вам привлечь внимание и сообщить пользователю, что именно он найдёт на вашей странице.
Невозможно поместить каждое ключевое слово, по которому вы хотите ранжироваться, в мета-описание, и в этом нет реальной необходимости – вместо этого напишите пару связных предложений, описывающих суть вашей страницы, включая основные ключевые слова.
Лучший способ выяснить, что необходимо поместить в мета тег Description для эффективного ранжирования – провести анализ конкурентов. Вбейте главный поисковый запрос вашей будущей или текущей страницы в Яндекс и Google. Посмотрите, кто и как заполнил описание, и возьмите себе всё самое лучшее из топа.
Мета совет
Мета-описание не обязательно должно состоять из одного-двух предложений. Вы можете добавить дополнительную информацию о странице, которая обрабатывается поисковиками и позволит выделиться в SERP.
Например:
- Для авторской статьи вы можете добавить дату публикации, имя автора.
- На странице продукта вы можете указать цену и дату изготовления товара.
Мета теги для социальных сетей
Open Graph был первоначально представлен Facebook, чтобы вы могли контролировать, как страница будет выглядеть при публикации в социальной сети. Сегодня эта разметка поддерживается большинством популярных соцсетей и мессенджеров: ВКонтакте, Твиттер, LinkedIn, Телеграм, Viber, Slack и др.
Вот основные теги Open Graph:
- og:title – здесь вы помещаете заголовок, который будет отображаться при ссылке на вашу страницу.
- og:url – URL вашей страницы.
- og:description – описание вашей страницы. Помните, что, например, Facebook будет отображать всего около 300 символов описания.
- og:image – здесь вы можете поместить URL-адрес изображения, которое будет отображаться при ссылке на вашу страницу.
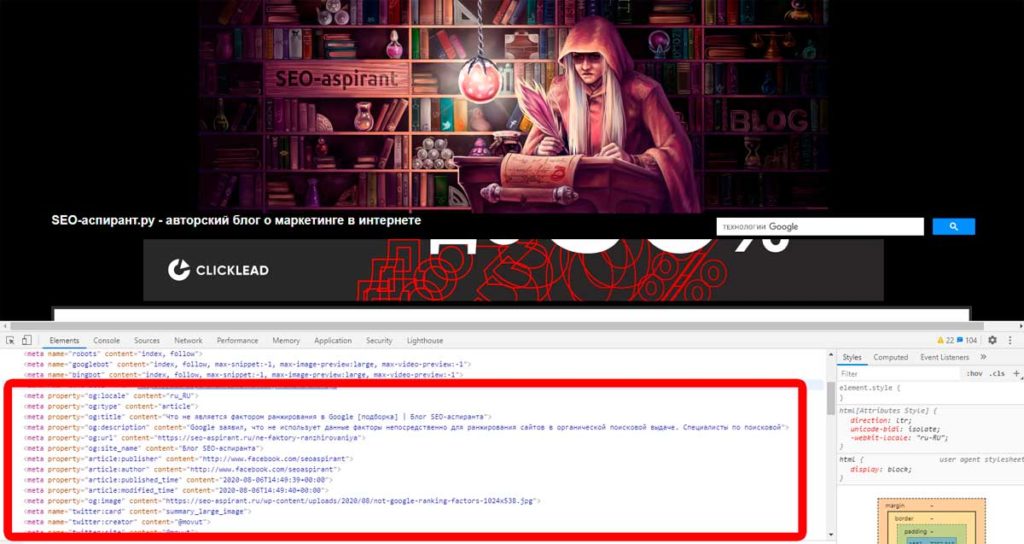
Используйте специфические метатеги социальных сетей, чтобы улучшить внешний вид ваших ссылок для подписчиков. Это не особо сложная функция и она не влияет напрямую на ранжирование. Однако, настроив красивое отображение ссылок, вы улучшите CTR и UX.
Как внедрить мета теги для социальных сетей
- Добавьте базовые и дополнительные метаданные, используя протокол Open Graph, и проверьте URL-ы, чтобы увидеть, как они будут отображаться.
- Настройте карточки для Твиттера и просмотрите результат.
- Дополнительную справку по мета тегам семантической разметки страниц можно получить в Яндексе.
- В Яндекс Вебмастере есть отдельный инструмент (валидатор) для проверки микроразметки, который подходит и под Open Graph.
- Для WordPress существует множество готовых решений. Я, например, использую плагин Yoast SEO.
How to Set Up Robots Meta Tags and X‑Robots-Tag
Setting up robots meta tags is, generally, easier than the x-robots-tag, but the implementation of both methods of controlling how search engines crawl and index your site can differ depending on your CMS and/or server type.
Here’s how yo use meta robots tags and the x-robots-tag on common setups:
Using Robots Meta Tags in HTML Code
If you can edit your page’s HTML code, simply add your robots meta tags straight into the <head> section of the page.
If you want search engines not to index the page but want links to be followed, as an example, use:
Using Robots Meta Tags on WordPress
If you’re using Yoast SEO, open up the ‘advanced’ tab in the block below the page editor.
You can set the «noindex» directive by setting the «Allow search engines to show this page in search results?» dropdown to no or prevent links from being followed by setting the «Should search engines follow links on this page?» to no.
For any other directives, you will need to implement these in the «Meta robots advanced» field.
If you’re using RankMath, you can select the robots directives that you wish apply straight from the Advanced tag of the meta box:
Image courtesy of RankMath
Using Robots Meta Tags on Shopify
If you need to implement robots meta tags on Shopify, you’ll need to do this by editing the <head> section of your theme.liquid layout file.
To set the directives for a specific page, add the below code to this file:
This code will instruct search engines, not to index /page-name/ but to follow all of the links on the page.
You will need to make separate entries to set the directives across different pages.
Using X-Robots-Tag on an Apache Server
To use the x-robots-tag on an Apache web server, add the following to your site’s .htaccess file or httpd.config file.
The example above sets the file type of .pdf and instructs search engines not to index the file but to follow any links on it.
Using X-Robots-Tag on an Nginx Server
If you’re running an Nginx server, add the below to your site’s .conf file:
This will apply a noindex attribute and follow any links on a .pdf file.
Выводы
Nofollow отвечает за переход поисковых систем по этим ссылкам, как на всей странице, так и для определенной ссылки. Ранее noindex тоже выполнял аналогичную функцию, но только по отношению к Яндексу, который со временем начал понимать nofollow, в результате чего значением noindex начали закрывать от индексации контент на странице.
Владелец сайта должен грамотно использовать атрибут nofollow и понимать, в каких именно случаях это делать:
- Когда ссылка ведет на веб-ресурсы с некачественным контентом.
- Когда вы размещаете на странице коммерческий контент.
По атрибуту nofollow ссылка может индексироваться и передавать свой вес, если она стоит на качественный ресурс.
Главная задача использования nofollow — помочь указать приоритетные для сканирования ссылки, разделить продающие статьи от информационных, а также защитить сайт от спама, который, если не контролировать, может привести к снижению ранжирования или куда хуже, вылету ресурса из индекса.
Для всех других ситуаций можете смело применять dofollow ссылки, открытые для поисковых роботов. Репутация сайта ничуть не ухудшится, а даже улучшится, если вы будете оставлять ссылки на полезные для вашей целевой аудитории страницы. И никакой вес ваши документы не потеряют, а наоборот даже могут приобрести за счет .