Методы regexp и string
Содержание:
- Методы Javascript для работы с регулярными выражениями
- Characters
- Ленивый режим квантификатора
- Изучение регулярных выражений
- Unicode категории (category)¶
- POSIX Extended Regular Expressions
- Символы¶
- Короткая запись
- Разделители¶
- Anchors
- 2 Практический раздел. Ссылки
- Повторения (квантификаторы)
- Строковые методы, поиск и замена
- Параметры регулярных выражений
- Perl programming language regular expression examples
Методы Javascript для работы с регулярными выражениями
В Javascript Существует 6 методов для работы с регулярными выражениями. Чаще всего мы будем использовать только половину из них.
Метод exec()
Метод RegExp, который выполняет поиск совпадения в строке. Он возвращает массив данных. Например:
var str = 'Some fruit: Banana - 5 pieces. For 15 monkeys.'; var re = /(\w+) - (\d) pieces/ig; var result = re.exec(str); window.console.log(result); // result = // Так же мы можем посмотреть позицию совпадения - result.index
В результате мы получим массив, первым элементом которого будет вся совпавшая по паттерну строка, а дальше содержимое скобочных групп. Если совпадений с паттерном нету, то .
Метод test()
Метод RegExp, который проверяет совпадение в строке, возвращает либо true, либо false. Очень удобен, когда нам необходимо проверить наличие или отсутствие паттерна в тексте. Например:
var str = 'Balance: 145335 satoshi'; var re = /Balance:/ig; var result = re.test(str); window.console.log(result); // true
В данном примере, есть совпадение с паттерном, поэтому получаем true.
Метод search()
Метод String, который тестирует на совпадение в строке. Он возвращет индекс совпадения, или -1 если совпадений не будет найдено. Очень похож на метод indexOf() для работы со строками. Минус этого метода — он ищет только первое совпадение. Для поиска всех совпадений используйте метод match().
var str = "Умея автоматизировать процессы, можно зарабатывать миллионы"; window.console.log(str.search(/можно/igm)); // 60 window.console.log(str.search(/атата/igm)); // -1
Метод match()
Метод String, который выполняет поиск совпадения в строке. Он возвращет массив данных либо null если совпадения отсутствуют.
// Без использования скобочных групп
var str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
var regexp = //gi;
var matches_array = str.match(regexp);
window.console.log(matches_array); //
// С использованием скобочных групп без флага g
var str = 'Fruits quantity: Apple - 5, Banana - 7, Orange - 12. I like fruits.';
var found = str.match(/(\d{1,2})/i);
window.console.log(found); // Находит первое совпадение и возвращает объект
// {
// 0: "5"
// 1: "5"
// index: 25
// input: "Fruits quantity: Apple -...ge - 12. I like fruits."
// }
// С использованием скобочных групп с флагом g
var found = str.match(/(\d{1,2})/igm);
window.console.log(found); //
Если совпадений нету — возвращает null.
Метод replace()
Метод String, который выполняет поиск совпадения в строке, и заменяет совпавшую подстроку другой подстрокой переданной как аргумент в этот метод. Мы уже использовали эту функцию для работы о строками, регулярные выражения привносят новые возможности.
// Обычная замена var str = 'iMacros is awesome, and iMacros is give me profit!'; var newstr = str.replace(/iMacros/gi, 'Javascript'); window.console.log(newstr); // Javascript is awesome, and Javascript is give me profit! // Замена, используя параметры. Меняем слова местами: var re = /(\w+)\s(\w+)/; var str = 'iMacros JS'; var newstr = str.replace(re, '$2, $1'); // в переменных $1 и $2 находятся значения из скобочных групп window.console.log(newstr); // JS iMacros
У метода replace() есть очень важная особенность — он имеет свой каллбэк. То есть, в качестве аргумента мы можем подавать функцию, которая будет обрабатывать каждое найденное совпадение.
Нестандартное применение метода replace():
var str = `
I have some fruits:
Orange - 5 pieces
Banana - 7 pieces
Apple - 15 pieces
It's all.
`;
var arr = []; // Сюда складируем данные о фруктах и их количестве
var newString = str.replace(/(\w+) - (\d) pieces/igm, function (match, p1, p2, offset, string) {
window.console.log(arguments);
arr.push({
name: p1,
quantity: p2
});
return match;
});
window.console.log(newString); // Текст не изменился, как и было задумано
window.console.log(arr); // Мы получили удобный массив объектов, с которым легко и приятно работать
Как вы видите, мы использовали этот метод для обработки каждого совпадения. Мы вытащили из паттерна название фрукта и количество и поместили эти значения в массив объектов, как мы уже делали ранее
Обратите внимание на аргумент функции offset — это будет индекс начала совпадения, этот параметр нам потом пригодится. В нашем случае, мы имеем 2 скобочные группы в паттерне, поэтому у нас в функции 5 аргументов, но их там может быть и больше
Метод split()
Метод String, который использует регулярное выражение или фиксированую строку чтобы разбить строку на массив подстрок.
var str = "08-11-2016";
// Разбиваем строку по разделителю
window.console.log(str.split('-')); //
// Такой же пример с регэкспом
window.console.log(str.split(/-/)); //
Characters
| Character | Legend | Example | Sample Match |
|---|---|---|---|
| \d | Most engines: one digitfrom 0 to 9 | file_\d\d | file_25 |
| \d | .NET, Python 3: one Unicode digit in any script | file_\d\d | file_9੩ |
| \w | Most engines: «word character»: ASCII letter, digit or underscore | \w-\w\w\w | A-b_1 |
| \w | .Python 3: «word character»: Unicode letter, ideogram, digit, or underscore | \w-\w\w\w | 字-ま_۳ |
| \w | .NET: «word character»: Unicode letter, ideogram, digit, or connector | \w-\w\w\w | 字-ま‿۳ |
| \s | Most engines: «whitespace character»: space, tab, newline, carriage return, vertical tab | a\sb\sc | a bc |
| \s | .NET, Python 3, JavaScript: «whitespace character»: any Unicode separator | a\sb\sc | a bc |
| \D | One character that is not a digit as defined by your engine’s \d | \D\D\D | ABC |
| \W | One character that is not a word character as defined by your engine’s \w | \W\W\W\W\W | *-+=) |
| \S | One character that is not a whitespace character as defined by your engine’s \s | \S\S\S\S | Yoyo |
Ленивый режим квантификатора
-
В этом режиме на начальном этапе, как и в жадном режиме, ищется совпадение с первым символом шаблона:
-
Далее ищется совпадение со следующим символом шаблона – любым символом:
-
В отличие от жадного режима, в ленивом ищется самое короткое совпадение в тексте, поэтому после нахождения совпадения со вторым символом шаблона, который задан точкой и соответствует символу на позиции №6 текста, будет проверять соответствие текста остатку шаблона – символу «»
-
Поскольку совпадение с шаблоном в тексте не найдено (на позиции №7 в тексте находится символ «»), добавляет еще один «любой символ» в шаблоне, так как он задан как один и более раз, и опять сравнивает шаблон с текстом на позициях с №5 по №8:
-
В нашем случае найдено совпадение, но конец текста ещё не достигнут. Поэтому с позиции №9 проверка начинается с поиска первого символа шаблона по аналогичному алгоритму и далее повторяется вплоть до окончания текста.
Алла
Алекса
Изучение регулярных выражений
Когда вы впервые начинаете изучать регулярные выражения и играться с ними, то, скорее всего, вы будете много ошибаться, у вас будет что-то не получаться и так далее. И это нормально, не волнуйтесь, ведь это всего лишь часть обучения. Чем больше у вас будет проблем, тем солиднее будет ваш опыт (при условии, что вы будете решать проблемы). Вот вам несколько советов для эффективной работы с регулярными выражениями:
Разбивайте регулярное выражение на отдельные компоненты.
Произносите вслух содержимое регулярного выражения. Например, в примере, приведенном выше, мы произносим: «Сначала мы выделяем , за которым следует или ». (Да, это может звучать глупо, но, поверьте, это работает)
Стройте регулярные выражения постепенно, тестируя каждую часть.
Unicode категории (category)¶
В стандарте Unicode есть именованные категории символов (Unicode category). Категория обозначается одной буквой, и еще одна добавляется, чтобы указать подкатегорию. Например «L» это буква в любом регистре, «Lu» — буквы в верхнем регистре, «Ll» — в нижнем.
- Cc — Control
- Cf — Формат
- Co — Частное использование
- Cs — Заменитель (Surrrogate)
- Ll — Буква нижнего регистра
- Lm — Буква-модификатор
- Lo — Прочие буквы
- Lt — Titlecase Letter
- Lu — Буква в верхнем регистре
- Mc — Разделитель
- Me — Закрывающий знак (Enclosing Mark)
- Mn — Несамостоятельный символ, как умляут над буквой (Nonspacing Mark)
- Nd — Десятичная цифра
- Nl — Буквенная цифра — например, китайская, римская, руническая и т.д. (Letter Number)
- No — Другие цифры
- Pc — Connector Punctuation
- Pd — Dash Punctuation
- Pe — Close Punctuation
- Pf — Final Punctuation
- Pi — Initial Punctuation
- Po — Other Punctuation
- Ps — Open Punctuation
- Sc — Currency Symbol
- Sk — Modifier Symbol
- Sm — Математический символ
- So — Прочие символы
- Zl — Разделитель строк
- Zp — Разделитель параграфов
- Zs — Space Separator
Метасимвол это один символ указанной Unicode категории (category). Синтаксис: или если категория обозначается одним символом, для 2-символьных категорий.
Метасимвол это символ не из Unicode категории (category).
POSIX Extended Regular Expressions
The Extended Regular Expressions or ERE flavor standardizes a flavor similar to the one used by the UNIX egrep command. “Extended” is relative to the original UNIX grep, which only had bracket expressions, dot, caret, dollar and star. An ERE support these just like a BRE. Most modern regex flavors are extensions of the ERE flavor. By today’s standard, the POSIX ERE flavor is rather bare bones. The POSIX standard was defined in 1986, and regular expressions have come a long way since then.
The developers of egrep did not try to maintain compatibility with grep, creating a separate tool instead. Thus egrep, and POSIX ERE, add additional metacharacters without backslashes. You can use backslashes to suppress the meaning of all metacharacters, just like in modern regex flavors. Escaping a character that is not a metacharacter is an error.
The quantifiers ?, +, {n}, {n,m} and {n,} repeat the preceding token zero or once, once or more, n times, between n and m times, and n or more times, respectively. Alternation is supported through the usual vertical bar |. Unadorned parentheses create a group, e.g. (abc){2} matches abcabc. The POSIX standard does not define backreferences. Some implementations do support \1 through \9, but these are not part of the standard for ERE. ERE is an extension of the old UNIX grep, not of POSIX BRE.
And that’s exactly how far the extension goes.
Символы¶
Серия символов соответствует этой серии символов во входной строке.
| RegEx | Находит |
|---|---|
Непечатные символы (escape-коды)
Для представления непечатаемого символа в регулярном выражении используется с шестнадцатеричным кодом. Если код длиннее 2 цифр (более U+00FF), то он обрамляется в фигурные скобки.
RegEx
Находит
символ с 2-значным шестнадцатеричным кодом
символ с 1-4 значным шестнадцатеричным кодом
(обратите внимание на пробел в середине)
Существует ряд предопределенных для непечатных символов, как в языке :
| RegEx | Находит |
|---|---|
| tab (HT/TAB), тоже что | |
| символ новой строки (LF), то же что | |
| возврат каретки (CR), тоже что | |
| form feed (FF), то же что | |
| звонок (BEL), тоже что | |
| escape (ESC), то же что | |
| … |
chr(0) по chr(25). |
Короткая запись
Допустим, мы хотим найти наличие цифр от 1 до 8. Мы могли бы использовать для поиска следующий диапазон: , но есть вариант получше:
Вы можете комбинировать набор символов вместе с другими символами:
В регулярном выражении, приведенном выше, мы ищем цифры 1, 2, 3, 4 или 9.
Мы также можем объединить несколько наборов. В следующем регулярном выражении мы ищем 1, 2, 3, 4, 5, a, b, c, d, e, f, x:
Использование наборов символов иногда может привести к странному поведению. Например, вы можете использовать диапазон и обнаружить, что ему соответствует символ . Это связано с таблицами символов, которые использует система. В большинстве систем есть таблица символов, в которой сначала идут все строчные буквы, а затем все заглавные (например, ). Однако некоторые системы чередуют строчные и прописные буквы (например, ). Если вы столкнулись с каким-то странным поведением и при этом используете диапазоны, то это первое, что нужно проверить.
Разделители¶
Разделители строк
| Метасимвол | Находит |
|---|---|
| любой символ в строке, может включать разделители строк | |
| совпадение нулевой длины в начале строки | |
| совпадение нулевой длины в конце строки | |
| совпадение нулевой длины в начале строки | |
| совпадение нулевой длины в конце строки | |
| похож на но совпадает перед разделителем строки, а не сразу после него, как |
Примеры:
| RegEx | Находит |
|---|---|
| только если он находится в начале строки | |
| , только если он в конце строки | |
| только если это единственная строка в строке | |
| , , и так далее |
Метасимвол совпадает с точкой начала строки (нулевой длины). — в конце строки. Если включен , они совпадают с началами или концами строк внутри текста.
Обратите внимание, что в последовательности нет пустой строки. Примечание
Примечание
Если вы используете , то / также соответствует , , , или .
Метасимвол совпадает с точкой нулевой длины в начале строки, — в конце (после символов завершения строки). Модификатор на них не влияет. тоже самое что но совпадает с точкой перед символами завершения строки (LF and CR LF).
Метасимвол по умолчанию соответствует любому символу, но если вы выключите , то не будет совпадать с разделителями строк внутри строки.
Обратите внимание, что выражение не соответствует точке между , потому что это неразрывный разделитель строк. Но оно соответствует пустой строке в последовательности , поэтому из-за неправильного порядка кодов он не воспринимается как разделитель строк и считается просто двумя символами
Примечание
Многострочная обработка может быть настроена с помощью свойств и .
Таким образом, вы можете использовать разделители стиля Unix или стиль DOS / Windows или смешивать их вместе (как описано выше по умолчанию).
Если вы предпочитаете математически правильное описание, вы можете найти его на сайте www.unicode.org.
Anchors
By default, regular expressions will match any part of a string. It’s often useful to anchor the regular expression so that it matches from the start or end of the string:
- matches the start of string.
- matches the end of the string.
To match a literal “$” or “^”, you need to escape them, , and .
For multiline strings, you can use . This changes the behaviour of and , and introduces three new operators:
-
now matches the start of each line.
-
now matches the end of each line.
-
matches the start of the input.
-
matches the end of the input.
-
matches the end of the input, but before the final line terminator, if it exists.
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
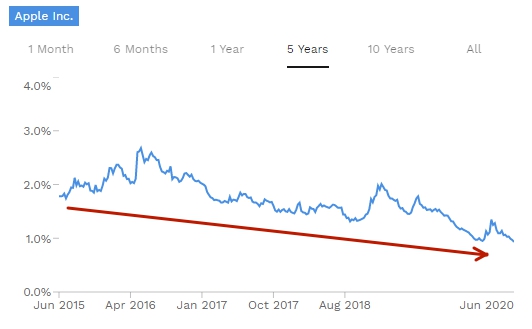
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
Повторения (квантификаторы)
Комбинация типа означает, что цифра должна повторяться два раза. Но бывают задачи, когда повторений очень много или мы не знаем, сколько именно. В таких члучаях нужно использовать специальные метасимволы.
Повторения символов или комбинаций описываются с помощью квантификаторов (метасимволов, которые задают количественные отношения). Есть два типа квантификаторов: общие (задаются с помощью фигурных скобок ) и сокращенные (сокращения наиболее распространенных квантификаторов). Фигурные скобки задают число повторений предыдущего символа (в этом случае выражение ищет от 1 до 7 идущих подряд букв «x»).
| Квантификатор | Описанте |
|---|---|
| a+ | Один и более раз a |
| a* | Ноль и более раз a |
| a? | Одна a или пусто |
| a{3} | 3 раза a |
| a{3,5} | От 3 до 5 раз a |
| a{3,} | 3 и более раз a |
Примечание: Если в выражении требуется поиск одного из метасимволов, вы можете использовать обратный слэш . Например, для поиска одного или нескольких вопросительных знаков можно использовать следующее выражение:
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Параметры регулярных выражений
Можно определить параметры, управляющие интерпретацией шаблона регулярного выражения обработчиком регулярных выражений. Многие из этих параметров можно указать в шаблоне регулярного выражения либо в виде одной или нескольких констант RegexOptions. Этот краткий справочник перечисляет только встраиваемые параметры. Дополнительные сведения о встроенных параметрах и параметрах RegexOptions см. в статье Параметры регулярных выражений.
Встроенный параметр можно задать двумя способами:
- С помощью прочих конструкций , где минус (-) перед параметром или набором параметров отключает эти параметры. Например, включает сопоставление без учета регистра (), отключает многострочный режим () и отключает захват неименованных групп (). Параметр применяется к шаблону регулярного выражения от точки, в которой определен параметр, и действует либо до конца шаблона, либо до точки, в которой другая конструкция отменяет параметр.
- С помощью конструкции группированиячасть выражения, которая определяет параметры для только для указанной группы.
Механизм регулярных выражений .NET поддерживает следующие встроенные параметры:
| Параметр | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Использовать соответствие без учета регистра. | , в | ||
| Использовать многострочный режим. и соответствуют началу и концу строки (line), а не началу и концу строки (string). | Пример см. в подразделе «Многострочный режим» раздела Параметры регулярных выражений. | ||
| Не захватывать неименованные группы. | Пример см. в подразделе «Только явные захваты» раздела Параметры регулярных выражений. | ||
| Использовать однострочный режим. | Пример см. в подразделе «Однострочный режим» раздела Параметры регулярных выражений. | ||
| Игнорировать знаки пробела в шаблоне регулярного выражения, не преобразованные в escape-последовательность. | , в |
Perl programming language regular expression examples
Below are a few examples of regular expressions and pattern matching in Perl. Many of these examples are similar or the same to other programming languages and programs that support regular expressions.
$data =~ s/bad data/good data/i;
The above example replaces any «bad data» with «good data» using a case-insensitive match. So if the $data variable was «Here is bad data» it would become «Here is good data».
$data =~ s/a/A/;
This example replaces any lowercase a with an uppercase A. So if $data was «example» it would become «exAmple».
$data =~ s//*/;
The above example replaces any lowercase letter, a through z, with an asterisk. So if $data was «Example» it would become «E******».
$data =~ s/e$/es/;
This example uses the $ character, which tells the regular expression to match the text before it at the end of the string. So if $data was «example» it would become «examples».
$data =~ s/\./!/;
In the above example, we are replacing a period with an exclamation mark. Because the period is a metacharacter if you only entered a period without the \ ( escape) it is treated as any character. In this example, if $data were «example.» it would become «example!», however, if you did not have the escape it would replace every character and become «!!!!!!!!»
$data =~ s/^e/E/;
Finally, in this above example the caret ( ^ ) tells the regular expression to match anything at the beginning of the line. In this example, any lowercase «e» at the beginning of the line is replaced with a capital «E.» Therefore, if $data was «example» it would become «Example».
Tip
If you want to explore regular expressions even more in commands like grep, or regular expressions in programming language’s check out the O’Reilly book «Mastering regular expressions.»