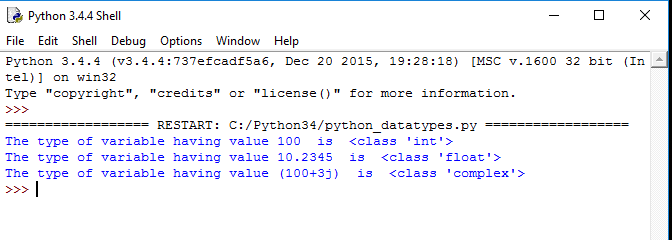
Функция sorted() в python
Содержание:
Как работает Быстрая сортировка
Быстрая сортировка чаще всего не сможет разделить массив на равные части. Это потому, что весь процесс зависит от того, как мы выбираем опорный элемент. Нам нужно выбрать опору так, чтобы она была примерно больше половины элементов и, следовательно, примерно меньше, чем другая половина элементов. Каким бы интуитивным ни казался этот процесс, это очень сложно сделать.
Подумайте об этом на мгновение — как бы вы выбрали адекватную опору для вашего массива? В истории быстрой сортировки было представлено много идей о том, как выбрать центральную точку — случайный выбор элемента, который не работает из-за того, что «дорогой» выбор случайного элемента не гарантирует хорошего выбора центральной точки; выбор элемента из середины; выбор медианы первого, среднего и последнего элемента; и еще более сложные рекурсивные формулы.
Самый простой подход — просто выбрать первый (или последний) элемент. По иронии судьбы, это приводит к быстрой сортировке на уже отсортированных (или почти отсортированных) массивах.
Именно так большинство людей выбирают реализацию быстрой сортировки, и, так как это просто и этот способ выбора опоры является очень эффективной операцией, и это именно то, что мы будем делать.
Теперь, когда мы выбрали опорный элемент — что нам с ним делать? Опять же, есть несколько способов сделать само разбиение. У нас будет «указатель» на нашу опору, указатель на «меньшие» элементы и указатель на «более крупные» элементы.
Цель состоит в том, чтобы переместить элементы так, чтобы все элементы, меньшие, чем опора, находились слева от него, а все более крупные элементы были справа от него. Меньшие и большие элементы не обязательно будут отсортированы, мы просто хотим, чтобы они находились на правильной стороне оси. Затем мы рекурсивно проходим левую и правую сторону оси.
Рассмотрим пошагово то, что мы планируем сделать, это поможет проиллюстрировать весь процесс. Пусть у нас будет следующий список.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21,44 (high)
Выберем первый элемент как опору 29), а указатель на меньшие элементы (называемый «low») будет следующим элементом, указатель на более крупные элементы (называемый «high») станем последний элемент в списке.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21 (high),44
Мы двигаемся в сторону high то есть влево, пока не найдем значение, которое ниже нашего опорного элемента.
29 | 99 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,21 (high),44
- Теперь, когда наш элемент high указывает на элемент 21, то есть на значение меньше чем опорное значение, мы хотим найти значение в начале массива, с которым мы можем поменять его местами. Нет смысла менять местами значение, которое меньше, чем опорное значение, поэтому, если low указывает на меньший элемент, мы пытаемся найти тот, который будет больше.
- Мы перемещаем переменную low вправо, пока не найдем элемент больше, чем опорное значение. К счастью, low уже имеет значение 89.
- Мы меняем местами low и high:
29 | 21 (low),27,41,66,28,44,78,87,19,31,76,58,88,83,97,12,99 (high),44
- Сразу после этого мы перемещает high влево и low вправо (поскольку 21 и 89 теперь на своих местах)
- Опять же, мы двигаемся high влево, пока не достигнем значения, меньшего, чем опорное значение, и мы сразу находим — 12
- Теперь мы ищем значение больше, чем опорное значение, двигая low вправо, и находим такое значение 41
Этот процесс продолжается до тех пор, пока указатели low и high наконец не встретятся в одном элементе:
29 | 21,27,12,19,28 (low/high),44,78,87,66,31,76,58,88,83,97,41,99,44
Мы больше не используем это опорное значение, поэтому остается только поменять опорную точку и high, и мы закончили с этим рекурсивным шагом:
28,21,27,12,19,29,44,78,87,66,31,76,58,88,83,97,41,99,44
Как видите, мы достигли того, что все значения, меньшие 29, теперь слева от 29, а все значения больше 29 справа.
Затем алгоритм делает то же самое для коллекции 28,21,27,12,19 (левая сторона) и 44,78,87,66,31,76,58,88,83,97,41,99,44 (правая сторона). И так далее.
Иллюстрация:
Для реализации сортировки оболочки необходимо выполнить следующие шаги:
Сначала возьмите список
Для этого примера мы возьмем
Принимая h=4 и создавая подсписок
Теперь мы получаем подсписок как: , , ,
На следующем шаге мы отсортируем эти подсписки с помощью сортировки вставки
После первого шага мы получаем список как
Принимая h=3 и создавая подсписок
Теперь у нас есть новый список и мы возьмем значение has 3
Подсписки, которые мы получаем: , , , ,
Теперь мы выполним сортировку вставки в каждом из этих подсписков
После этого шага список, который мы получим:
Принимая h=2 и создавая подсписок
Теперь мы возьмем значение
Созданные подсписки являются: , , , , ,
После выполнения сортировки вставки в этих списках результирующий список будет следующим:
aking h=1 и создание подсписка
Теперь мы возьмем и создадим подсписки
Подсписки, созданные на этот раз, являются: , , , , , ,
Теперь мы снова применим вставку сортировки этих отдельных подсписков, и конечный результат, который мы получим, будет
Окончательный сортированный список
Использование параметра cmp
Все версии Python 2.x поддерживали параметр для обработки пользовательских функций сравнения. В Python 3.0 от этого параметра полностью избавились. В Python 2.x в можно было передать функцию, которая использовалась бы для сравнения элементов. Она должна принимать два аргумента и возвращать отрицательное значение для случая «меньше чем», положительное — для «больше чем» и ноль, если они равны:
Можно сравнивать в обратном порядке:
При портировании кода с версии 2.x на 3.x может возникнуть ситуация, когда нужно преобразовать пользовательскую функцию для сравнения в функцию-ключ. Следующая обёртка упрощает эту задачу:
Чтобы произвести преобразование, оберните старую функцию:
В Python 2.7 функция была добавлена в модуль functools.
8
Выполняет сортировку последовательности по возростанию/убыванию.
Параметры:
- — объект, поддерживающий итерирование
- — пользовательская функция, которая применяется к каждому элементу последовательности
- — порядок сортировки
Описание:
Функция вернет новый отсортированный t-list] из итерируемых элементов. Функция имеет два необязательных аргумента, которые должны быть указаны в качестве аргументов ключевых слов.
Аргумент принимает функцию, например . Переданная функция вычисляет результат для каждого элемента последовательности, который используется для сравнения элементов при сортировке. Значением по умолчанию является , т.е. сравнивать элементы напрямую (как есть).
Аргумент имеет логическое значение. Если установлено значение , то элементы списка сортируются в обратной последовательности (по убыванию).
Используйте для преобразования функции, использующей cmp (старый стиль) в использующую key (новый стиль).
Встроенная функция sorted() является гарантированно стабильной. Это означает, что когда несколько элементов последовательности имеют равные значения, их первоначальный порядок сохраняется. Такое поведение полезно при сортировке в несколько проходов.
Примеры различных способов сортировки последовательностей.
Сортировка слов в предложении без учета регистра:
line = 'This is a test string from Andrew' x = sorted(line.split(), key=str.lower) print(x) #
Сортировка сложных объектов с использованием индексов в качестве ключей :
student =
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
# Сортируем по возрасту student
x = sorted(student, key=lambda student student2])
print(x)
#
Тот же метод работает для объектов с именованными атрибутами.
class Student
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return repr((self.name, self.grade, self.age))
student =
Student('john', 'A', 15),
Student('jane', 'B', 12),
Student('dave', 'B', 10),
x = sorted(student, key=lambda student student.age)
print(x)
#
Сортировка по убыванию:
student =
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
# Сортируем по убыванию возраста student
x = sorted(student, key=lambda i i2], reverse=True)
print(x)
#
Стабильность сортировки и сложные сортировки:
data = x = sorted(data, key=lambda data data]) print(x) #
Обратите внимание, как две записи (‘blue’, 1), (‘blue’, 2) для синего цвета сохраняют свой первоначальный порядок. Это замечательное свойство позволяет создавать сложные сортировки за несколько проходов по нескольким ключам
Например, чтобы отсортировать данные учащиеся по возрастанию успеваемости, а затем по убыванию возраста. Успеваемость будет первым ключом, возраст вторым
Это замечательное свойство позволяет создавать сложные сортировки за несколько проходов по нескольким ключам. Например, чтобы отсортировать данные учащиеся по возрастанию успеваемости, а затем по убыванию возраста. Успеваемость будет первым ключом, возраст вторым.
student =
('john', 15, 4.1),
('jane', 12, 4.9),
('dave', 10, 3.9),
('kate', 11, 4.1),
# По средней оценке
x = sorted(student, key=lambda num num2])
# По убыванию возраста
y = sorted(x, key=lambda age age1], reverse=True)
print(y)
#
А еще, для сортировок по нескольким ключам, удобнее использовать модуль . Функции модуля допускают несколько уровней сортировки. Например, как в предыдущем примере успеваемость будет первым ключом, возраст вторым.Только сортировать будем все по возрастанию:
from operator import itemgetter x = sorted(student, key=itemgetter(2,1)) print(x) #
Key Functions
Starting with Python 2.4, both list.sort() and sorted() added a key parameter to specify a function to be called on each list element prior to making comparisons.
For example, here’s a case-insensitive string comparison:
>>> sorted("This is a test string from Andrew".split(), key=str.lower)
The value of the key parameter should be a function that takes a single argument and returns a key to use for sorting purposes. This technique is fast because the key function is called exactly once for each input record.
A common pattern is to sort complex objects using some of the object’s indices as a key. For example:
>>> student_tuples = >>> sorted(student_tuples, key=lambda student: student) # sort by age
The same technique works for objects with named attributes. For example:
>>> class Student:
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return repr((self.name, self.grade, self.age))
def weighted_grade(self):
return 'CBA'.index(self.grade) / float(self.age)
>>> student_objects =
>>> sorted(student_objects, key=lambda student: student.age) # sort by age
Сортировка массива в Python
Метод Пузырька
Сортировку массива в python будем выполнять :
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import random
from random import randint
mas = randint(1,10) for i in range(n)
for i in range(n):
print(masi,sep="")
print(" ")
for i in range(n-1):
for j in range(n-2, i-1 ,-1):
if masj+1 < masj:
masj, masj+1 = masj+1, masj
for i in range(n):
print(masi,sep="")
|
Задание Python 7_4:
Необходимо написать программу, в которой сортировка выполняется «методом камня» – самый «тяжёлый» элемент опускается в конец массива.
Быстрая сортировка массива
Данную сортировку еще называют или сортировка Хоара (по имени разработчика — Ч.Э. Хоар).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import random
from random import randint
# процедура
def qSort ( A, nStart, nEnd ):
if nStart >= nEnd: return
L = nStart; R = nEnd
X = A(L+R)//2
while L <= R:
while AL < X: L += 1 # разделение
while AR > X: R -= 1
if L <= R:
AL, AR = AR, AL
L += 1; R -= 1
qSort ( A, nStart, R ) # рекурсивные вызовы
qSort ( A, L, nEnd )
N=10
A = randint(1,10) for i in range(N)
print(A)
# вызов процедуры
qSort ( A, , N-1 )
print('отсортированный', A)
|
Задание Python 7_5:
Необходимо написать программу, которая сортирует массив (быстрой сортировкой) по возрастанию первой цифры числа.
Встроенные функции
- mas.reverse() — стандартный метод для перестановки элементов массива в обратном порядке;
- mas2 = sorted (mas1) — встроенная функция для сортировки массивов (списков);
Задание Python 7_6:
Напишите программу, которая, не изменяя заданный массив, выводит номера его элементов в возрастающем порядке значений этих элементов. Использовать вспомогательный массив номеров.
Пример:
результат: 0 2 3 1 4
Задание Python 7_7:
Напишите программу, которая сортирует массив и находит количество различных чисел в нём. Не использовать встроенные функции.Пример:
Введите количество: 10 Массив: Массив отсортированный: Количество различных элементов: 9
Задание Python 7_8:
Дан массив. Назовем серией группу подряд идущих одинаковых элементов, а длиной серии — количество этих элементов. Сформировать два новых массива, в один из них записывать длины всех серий, а во второй — значения элементов, образующих эти серии.Пример:
Введите количество элементов: 15 Массив: Элементы, создающие серии: Длины серий:
Задание Python 7_9:
Напишите вариант метода пузырька, который заканчивает работу, если на очередном шаге внешнего цикла не было перестановок. Не использовать встроенные функции.
Задание Python 7_10:
Напишите программу, которая сортирует массив, а затем находит максимальное из чисел, встречающихся в массиве несколько раз. Не использовать встроенные функции.
Пример:
Введите количество: 15 Массив исходный: Массив отсортированный: Максимальное из чисел, встречающихся в массиве несколько раз: 12
Сортировка сортировки Python
Ниже приведены различные методы для сортировки элементов:
- Сортируйте список в порядке возрастания
- Сортируйте список в порядке убывания
- Сортируйте список, используя пользовательский WARDE р
- Сортировать список объектов
- Сортировка списка с использованием ключа
1. Сортировка элементов списка в порядке возрастания
Сортировать () Функция используется для сортировки элементов списка в порядке возрастания.
input =
print(f'Before sorting of elements: {input}')
input.sort()
print(f'After sorting of elements: {input}')
Выход:
Before sorting of elements: After sorting of elements:
2. Стиральные элементы списка в порядке убывания
Обратный Параметр используется для сортировки элементов списка в порядке убывания.
Синтаксис: Список name.sort (Reverse = True)
input = input.sort(reverse = True) print(input)
Выход:
3. Список сортировки Python с использованием функции ключа
Python предоставляет сортировку элементов списка, используя функцию ключа в качестве параметра. Основываясь на выходе ключевой функции, список будет отсортирован.
# takes third element for sort
def third_element(x):
return x
input =
# sort list with key
input.sort(key=third_element)
# prints sorted list
print('Sorted list:', input)
Выход:
Sorted list:
4. Сортируйте список, используя пользовательский порядок
# takes third element for sort
def third_element(x):
return x
input =
# sorts list with key in ascending order
input.sort(key=third_element)
# prints sorted list
print('Sorted list in ascending order:', input)
# sorts list with key in descending order
input.sort(key=third_element, reverse=True)
print('Sorted list in descending order:', input)
Выход:
Sorted list in ascending order: Sorted list in descending order:
5. Сортировка списка объектов
Чтобы сортировать список пользовательских объектов, использующих функцию Sorth (), нам необходимо указать функцию ключа, указав поле объекта для достижения того же.
class Details:
def __init__(self, name, num):
self.name = name
self.num = num
def __str__(self):
return f'Details'
__repr__ = __str__
D1 = Details('Safa', 12)
D2 = Details('Aman', 1)
D3 = Details('Shalini', 45)
D4 = Details('Ruh', 30)
input_list =
print(f'Before Sorting: {input_list}')
def sort_by_num(details):
return details.num
input_list.sort(key=sort_by_num)
print(f'After Sorting By Number: {input_list}')
Выход:
Before Sorting: , Details, Details, Details] After Sorting By Number: , Details, Details, Details]
Анализ
Пример пузырьковой сортировки. Начиная с начала списка, сравните каждую соседнюю пару, поменяйте их местами, если они не в правильном порядке (последняя меньше первой). После каждой итерации необходимо сравнивать на один элемент меньше (последний), пока не останется больше элементов для сравнения.
Представление
Пузырьковая сортировка имеет наихудший случай и среднюю сложность О ( n 2 ), где n — количество сортируемых элементов. Большинство практических алгоритмов сортировки имеют существенно лучшую сложность в худшем случае или в среднем, часто O ( n log n ). Даже другое О ( п 2 ) алгоритмы сортировки, такие как вставки рода , как правило , не работать быстрее , чем пузырьковой сортировки, а не более сложным. Следовательно, пузырьковая сортировка не является практическим алгоритмом сортировки.
Единственное существенное преимущество пузырьковой сортировки перед большинством других алгоритмов, даже быстрой сортировкой , но не сортировкой вставкой , заключается в том, что в алгоритм встроена способность определять, что список сортируется эффективно. Когда список уже отсортирован (в лучшем случае), сложность пузырьковой сортировки составляет всего O ( n ). Напротив, большинство других алгоритмов, даже с лучшей средней сложностью , выполняют весь процесс сортировки на множестве и, следовательно, являются более сложными. Однако сортировка вставкой не только разделяет это преимущество, но также лучше работает со списком, который существенно отсортирован (имеет небольшое количество инверсий ). Кроме того, если такое поведение желательно, его можно тривиально добавить к любому другому алгоритму, проверив список перед запуском алгоритма.
В случае больших коллекций следует избегать пузырьковой сортировки. Это не будет эффективно в случае коллекции с обратным порядком.
Кролики и черепахи
Расстояние и направление, в котором элементы должны перемещаться во время сортировки, определяют производительность пузырьковой сортировки, поскольку элементы перемещаются в разных направлениях с разной скоростью. Элемент, который должен двигаться к концу списка, может перемещаться быстро, потому что он может принимать участие в последовательных заменах. Например, самый большой элемент в списке будет выигрывать при каждом обмене, поэтому он перемещается в свою отсортированную позицию на первом проходе, даже если он начинается с начала. С другой стороны, элемент, который должен двигаться к началу списка, не может двигаться быстрее, чем один шаг за проход, поэтому элементы перемещаются к началу очень медленно. Если наименьший элемент находится в конце списка, потребуется n −1 проход, чтобы переместить его в начало. Это привело к тому, что эти типы элементов были названы кроликами и черепахами соответственно в честь персонажей басни Эзопа о Черепахе и Зайце .
Были предприняты различные попытки уничтожить черепах, чтобы повысить скорость сортировки пузырей. Сортировка коктейлей — это двунаправленная сортировка пузырьков, которая идет от начала до конца, а затем меняет свое направление, идя от конца к началу. Он может довольно хорошо перемещать черепах, но сохраняет сложность наихудшего случая O (n 2 ) . Комбинированная сортировка сравнивает элементы, разделенные большими промежутками, и может очень быстро перемещать черепах, прежде чем переходить к все меньшим и меньшим промежуткам, чтобы сгладить список. Его средняя скорость сопоставима с более быстрыми алгоритмами вроде быстрой сортировки .
Пошаговый пример
Возьмите массив чисел «5 1 4 2 8» и отсортируйте его от наименьшего числа к наибольшему, используя пузырьковую сортировку. На каждом этапе сравниваются элементы, выделенные жирным шрифтом . Потребуется три прохода;
- Первый проход
- ( 5 1 4 2 8) → ( 1 5 4 2 8). Здесь алгоритм сравнивает первые два элемента и меняет местами, поскольку 5> 1.
- (1 5 4 2 8) → (1 4 5 2 8), поменять местами, поскольку 5> 4
- (1 4 5 2 8) → (1 4 2 5 8), поменять местами, поскольку 5> 2
- (1 4 2 5 8 ) → (1 4 2 5 8 ). Теперь, поскольку эти элементы уже упорядочены (8> 5), алгоритм не меняет их местами.
- Второй проход
- ( 1 4 2 5 8) → ( 1 4 2 5 8)
- (1 4 2 5 8) → (1 2 4 5 8), поменять местами, поскольку 4> 2
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Теперь массив уже отсортирован, но алгоритм не знает, завершился ли он. Алгоритму требуется один дополнительный полный проход без какой-либо подкачки, чтобы знать, что он отсортирован.
- Третий проход
- ( 1 2 4 5 8) → ( 1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Python sort list of namedtuples
In the next example, we sort namedtuples.
namedtuple_sort.py
#!/usr/bin/env python3
from typing import NamedTuple
class City(NamedTuple):
id: int
name: str
population: int
c1 = City(1, 'Bratislava', 432000)
c2 = City(2, 'Budapest', 1759000)
c3 = City(3, 'Prague', 1280000)
c4 = City(4, 'Warsaw', 1748000)
c5 = City(5, 'Los Angeles', 3971000)
c6 = City(6, 'Edinburgh', 464000)
c7 = City(7, 'Berlin', 3671000)
cities =
cities.sort(key=lambda e: e.name)
for city in cities:
print(city)
The namedtuple has three attributes: ,
, and . The example sorts the
namedtuples by their names.
cities.sort(key=lambda e: e.name)
The anonymous function returns the name property of the namedtuple.
$ ./namedtuple_sort.py City(id=7, name='Berlin', population=3671000) City(id=1, name='Bratislava', population=432000) City(id=2, name='Budapest', population=1759000) City(id=6, name='Edinburgh', population=464000) City(id=5, name='Los Angeles', population=3971000) City(id=3, name='Prague', population=1280000) City(id=4, name='Warsaw', population=1748000)
This is the output.
Stable sort
A stable sort is one where the initial order of equal elements is preserved.
Some sorting algorithms are naturally stable, some are unstable. For instance, the
merge sort and the bubble sort are stable sorting algorithms. On the other hand, heap
sort and quick sort are examples of unstable sorting algorithms.
Consider the following values: . A stable sorting
produces the following: . The ordering of the values
3 and 5 is kept. An unstable sorting may produce the following: .
Python uses the timsort algorithm. It is a hybrid stable sorting algorithm,
derived from merge sort and insertion sort. It was implemented by Tim Peters
in 2002 for use in the Python programming language.
Понимание алгоритма сортировки пузыря
Подумайте о том, как в стакане соды пузырьки внутри поднимаются. Пузырьки представляют собой величайший/наименьший элемент в заданной последовательности, и растущие движения пузыря представляют, как величайший/наименьший элемент перемещается до конца/начала последовательности.
Вот как работает пузырька, и почему у него есть имя.
Чтобы проложить его просто, мы проходим через последовательность несколько раз, и каждый раз, когда мы поменяем несколько пар элементов таким образом, что наибольший/наименьший элемент в последовательности заканчивается на одном из концов последовательности.
Ради этого учебника мы рассмотрим данный массив, и мы отсортируем его в растущем порядке стоимости чисел.
12, 16, 11, 10, 14, 13
Теперь алгоритм пузырькового сорта работает так, как это для сортировки в увеличении порядка:
- Рассмотрим две переменные Я и J Отказ Я представляет количество элементов, которые мы сортировали или количество раз, когда мы проходили через список, потому что каждый раз, когда мы проходим через список, который мы сортируем один элемент наверняка. J представляет позицию в списке, так что если мы говорим, что J 3, тогда мы говорим о третьем номере в списке, который 11.
- Рассмотреть возможность n как количество элементов в списке.
- Пусть Я быть равным 0. Потому что мы не проходили через список, и никакие элементы не сортируются.
- Пусть J быть равным 1. Таким образом, мы начинаем с номера в первой позиции.
- Если номер в положении J больше, чем число в положении J + 1 Затем нам нужно поменять номера на позициях J и J + 1 Отказ Это связано с тем, что список находится в увеличении порядка, поэтому число, которое приходит до того, как не может быть больше, чем число, которое приходит после.
- Увеличение J К 1. Так что теперь мы можем посмотреть на следующую пару чисел.
- Если J не N-I Перейдите к шагу 5, в противном случае мы остановим петлю и перейдем к следующему шагу. В этой петле каждый раз, когда происходит своп, больший элемент перемещается к концу списка. Это поведение пузырькового сорта, величайшие элементы пузырька к концу списка. Если Я представляет количество элементов, уже отсортированных, то последний Я Элементы списка находятся в их правильном положении (потому что они пробиваются во время I Количество раз, когда мы проходили через петлю), поэтому нам не нужно проверять последний Я Элементы, так как это будет только тратить время, и, следовательно, контур заканчивается, когда j равно N-I Отказ
- Увеличение Я К 1. Если мы закончили петлю, когда J Дошел до конца, мы прошли через список еще раз, и еще один элемент отсортирован.
- Если Я не N-1 Затем перейдите к шагу 4, в противном случае мы остановим петлю с Я и перейти к следующему шагу. Как вы могли заметить, есть две петли, внутренний с J несет ответственность за сортировку еще одного элемента, и у нас есть все элементы, которые обрабатывают внешний цикл, который работает на Я Отказ Если Я становится N-1 это значит N-1 Элементы сортируются, что автоматически означает, что последний элемент также находится в его правильном положении, и это означает, что вся последовательность сортируется, и поэтому мы останавливаемся.
- Последовательность отсортирована.
Теперь вы можете попробовать это по данной последовательности, и это то, что мы сейчас сделаем.