Seo spider companion tools, aka ‘the magnificent seven’
Содержание:
- 3) XML Sitemap & Sitemap Index Crawling
- Introduction To Crawling JavaScript
- 1) ‘Fetch & Render’ (Rendered Screen Shots)
- 3) GA & GSC Not Matched Report
- Small Update – Version 10.3 Released 24th October 2018
- 5) HSTS Support
- Десктопные и облачные парсеры
- Link Building
- Regex Examples
- Чек-лист по выбору парсера
- Расширенное сканирование в режиме списка
- Serpstat
- Загрузка списка
- Exporting Data
- macOS
- 4) Cookies
- Licence Activation
- Referr.ru
- 2) Site Structure Comparison
- Netpeak Software
- 7) Updated SERP Snippet Emulator
- 2) Щелкните вкладку «Коды ответов» и выберите фильтр «Перенаправление (3XX)», чтобы просмотреть перенаправления.
- Popular Uses & Advanced Features
3) XML Sitemap & Sitemap Index Crawling
The SEO Spider already allows crawling of XML sitemaps in list mode, by uploading the .xml file (number 8 in the ‘10 features in the SEO Spider you should really know‘ post) which was always a little clunky to have to save it if it was already live (but handy when it wasn’t uploaded!).
So we’ve now introduced the ability to enter a sitemap URL to crawl it (‘List Mode > Download Sitemap’).

Previously if a site had multiple sitemaps, you’d have to upload and crawl them separately as well.
Now if you have a sitemap index file to manage multiple sitemaps, you can enter the sitemap index file URL and the SEO Spider will download all sitemaps and subsequent URLs within them!

This should help save plenty of time!
Introduction To Crawling JavaScript
Historically search engine bots such as Googlebot didn’t crawl and index content created dynamically using JavaScript and were only able to see what was in the static HTML source code.
However, there’s been a huge growth in JavaScript use, and frameworks such as AngularJS, React, Vue.JS, single page applications (SPAs) and progressive web apps (PWAs).
This has meant Google in particular has evolved significantly, deprecating their old AJAX crawling scheme guidelines of escaped-fragment #! URLs and HTML snapshots in October ’15, and are now generally able to render and understand web pages like a modern-day browser.
While Google are generally able to crawl and index most JavaScript content, they recommend server-side rendering, pre-rendering or dynamic rendering rather than relying on client-side JavaScript as its ‘difficult to process JavaScript and not all search engine crawlers are able to process it successfully or immediately’.
It’s essential today to be able to read the DOM after JavaScript has come into play and constructed the web page and understand the differences between the original response HTML, when crawling and evaluating websites.
Traditional website crawlers were not able to crawl JavaScript websites, until we launched the first ever functionality into our Screaming Frog SEO Spider software. This meant pages were fully rendered in a browser first, and the rendered HTML post-JavaScript is crawled.
We integrated the Chromium project library for our rendering engine to emulate Google as closely as possible.

In 2019 Google updated their web rendering service (WRS) which was previously based on Chrome 41 to be ‘evergreen’ and use the latest, stable version of Chrome – supporting over 1,000 more features.
The SEO Spider uses a slightly earlier version of Chrome, version 69 at the time of writing, but we recommend viewing the exact version within the app by clicking ‘Help > Debug’ and scrolling down to the ‘Chrome Version’ line as we update this frequently.
Hence, while rendering will obviously be similar, it won’t be exactly the same as there might be some small differences in supported features (there are arguments that the exact version of Chrome itself won’t be exactly the same, either). However, generally, the WRS supports the same web platform features and capabilities that the Chrome version it uses, and you can compare the differences between Chrome versions at .
This guide contains the following 3 sections. Click and jump to a relevant section, or continue reading.
- 1)
- 2)
- 3)
If you already understand the basic principles of JavaScript and just want to crawl a JavaScript website, skip straight to our guide on configuring the Screaming Frog SEO Spider tool to . Or, read on.
1) ‘Fetch & Render’ (Rendered Screen Shots)
You can now view the rendered page the SEO Spider crawled in the new ‘Rendered Page’ tab which dynamically appears at the bottom of the user interface when crawling in mode. This populates the lower window pane when selecting URLs in the top window.

This feature is enabled by default when using the new JavaScript rendering functionality and allows you to set the AJAX timeout and viewport size to view and test various scenarios. With Google’s much discussed mobile first index, this allows you to set the user-agent and viewport as Googlebot Smartphone and see exactly how every page renders on mobile.

Viewing the rendered page is vital when analysing what a modern search bot is able to see and is particularly useful when performing a review in staging, where you can’t rely on Google’s own Fetch & Render in Search Console.
3) GA & GSC Not Matched Report
The ‘GA Not Matched’ report has been replaced with the new ‘GA & GSC Not Matched Report’ which now provides consolidated information on URLs discovered via the Google Search Analytics API, as well as the Google Analytics API, but were not found in the crawl.
This report can be found under ‘reports’ in the top level menu and will only populate when you have connected to an API and the crawl has finished.
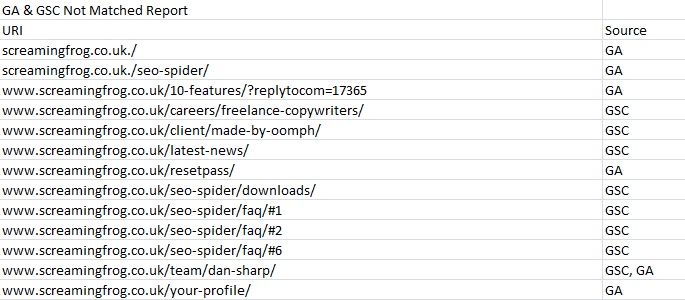
There’s a new ‘source’ column next to each URL, which details the API(s) it was discovered (sometimes this can be both GA and GSC), but not found to match any URLs found within the crawl.
You can see in the example screenshot above from our own website, that there are some URLs with mistakes, a few orphan pages and URLs with hash fragments, which can show as quick links within meta descriptions (and hence why their source is GSC rather than GA).
I discussed how this data can be used in more detail within the and it’s a real hidden gem, as it can help identify orphan pages, other errors, as well as just matching problems between the crawl and API(s) to investigate.
Small Update – Version 10.3 Released 24th October 2018
We have just released a small update to version 10.3 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Custom search now works over multiple lines.
- Introduced a ‘Contains Hreflang’ filter, inline with other tabs and elements (Canonicals, Pagination etc).
- Renamed hreflang ‘Incorrect Language Codes’ filter, to ‘Incorrect Language & Region Codes’.
- Reworked GSC account selection to improve usability.
- URLs discovered via sitemaps now go via URL rewriting.
- Be more tolerant of XML Sitemap/Sitemap index files missing the XML declaration (Google process them, so the SEO Spider now does, too).
- Include the protocol in ‘Orphan Pages’ report for GSC & XML Sitemaps URLs.
- Warn on startup if network debugging is on. This slows crawls down, and should not be enabled unless requested by our support.
- Fix “Maximum call stack size exceeded” with visualisations.
- Fix crash writing ‘Reports > Overview’.
- Fix error exporting ‘Hreflang:Inconsistent Language Confirmation Links’ from command line.
- Fix crash when running Crawl Analysis.
- Fix crash triggered by pages with invalid charset names.
- Fix scheduler issue with Hebrew text.
- Fix crash crawling AMP URLs.
- Fix macOS issue where scheduling failed if the LaunchAgents folder didn’t exist.
- Fix anti aliasing issue in Ubuntu.
5) HSTS Support
HTTP Strict Transport Security (HSTS) is a server directive that forces all connections over HTTPS. If any ‘insecure’ links are discovered in a crawl with a Strict-Transport-Security header set, the SEO Spider will show a 307 response with a status message of ‘HSTS Policy’.
The SEO Spider will request the HTTPS version as instructed, but highlight this with a 307 response (inline with browsers, such as Chrome), to help identify when HSTS and insecure links are used (rather than just requesting the secure version, and not highlighting that insecure links actually exist).
The search engines and browsers will only request the HTTPS version, so obviously the 307 response HSTS policy should not be considered as a real temporary redirect and ‘a redirect to fix’. John Mueller discussed this in a Google+ post last year.
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
- Import.io,
- Mozenda (доступна также десктопная версия парсера),
- Octoparce,
- ParseHub.
Из русскоязычных облачных парсеров можно привести такие:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Link Building
If you’ve scraped or otherwise come up with a list of URLs that needs to be vetted, you can upload and crawl them in ‘List’ mode to gather more information about the pages. When the spider is finished crawling, check for status codes in the ‘Response Codes’ tab, and review outbound links, link types, anchor text and nofollow directives in the ‘Outlinks’ tab in the bottom window. This will give you an idea of what kinds of sites those pages link to and how. To review the ‘Outlinks’ tab, be sure that your URL of interest is selected in the top window.
Of course you’ll want to use a custom filter to determine whether or not those pages are linking to you already.

You can also export the full list of out links by clicking on ‘All Outlinks’ in the ‘Bulk Export Menu’. This will not only provide you with the links going to external sites, but it will also show all internal links on the individual pages in your list.
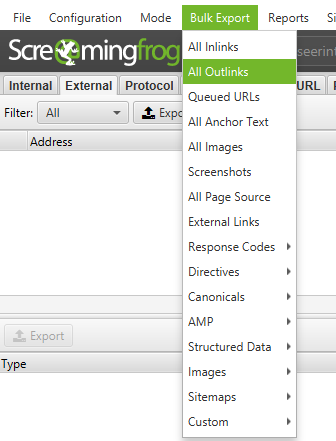
For more great ideas for link building, check out these two awesome posts on link reclamation and using Link Prospector with Screaming Frog by SEER’s own @EthanLyon and @JHTScherck.
So, you found a site that you would like a link from? Use Screaming Frog to on the desired page or on the site as a whole, then contact the site owner, suggesting your site as a replacement for the broken link where applicable, or just offer the broken link as a token of good will.
Upload your list of backlinks and run the spider in ‘List’ mode. Then, export the full list of outbound links by clicking on ‘All Out Links’ in the ‘Advanced Export Menu’. This will provide you with the URLs and anchor text/alt text for all links on those pages. You can then use a filter on the ‘Destination’ column of the CSV to determine if your site is linked and what anchor text/alt text is included.
@JustinRBriggs has a nice tidbit on checking infographic backlinks with Screaming Frog. Check out the other 17 link building tools that he mentioned, too.
Want to figure out if a group of sites are linking to each other? Check out this tutorial on visualizing link networks using Screaming Frog and Fusion Tables by @EthanLyon.
Set a custom filter that contains your root domain URL, then upload your list of backlinks and run the spider in ‘List’ mode. When the spider has finished crawling, select the ‘Custom’ tab to view all of the pages that are still linking to you.
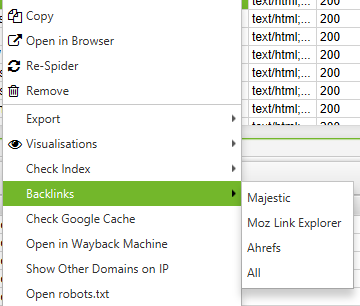
Did you know that by right-clicking on any URL in the top window of your results, you could do any of the following?
- Copy or open the URL
- Re-crawl the URL or remove it from your crawl
- Export URL Info, In Links, Out Links, or Image Info for that page
- Check indexation of the page in Google, Bing and Yahoo
- Check backlinks of the page in Majestic, OSE, Ahrefs and Blekko
- Look at the cached version/cache date of the page
- See older versions of the page
- Validate the HTML of the page
- Open robots.txt for the domain where the page is located
- Search for other domains on the same IP
Likewise, in the bottom window, with a right-click, you can:
Copy or open the URL in the ‘To’ for ‘From’ column for the selected row
How to Edit Meta Data
SERP Mode allows you to preview SERP snippets by device to visually show how your meta data will appear in search results.
- Upload URLs, titles and meta descriptions into Screaming Frog using a .CSV or Excel document
- Mode → SERP → Upload File
- Edit the meta data within Screaming Frog
- Bulk export updated meta data to send directly to developers to update
How to a Crawl JavaScript Site
It’s becoming more common for websites to be built using JavaScript frameworks like Angular, React, etc. Google strongly recommends using a rendering solution as Googlebot still struggles to crawl javascript content. If you’ve identified a website built using javascript, follow the below instructions to crawl the website.
‘Configuration → Spider → Rendering → JavaScript
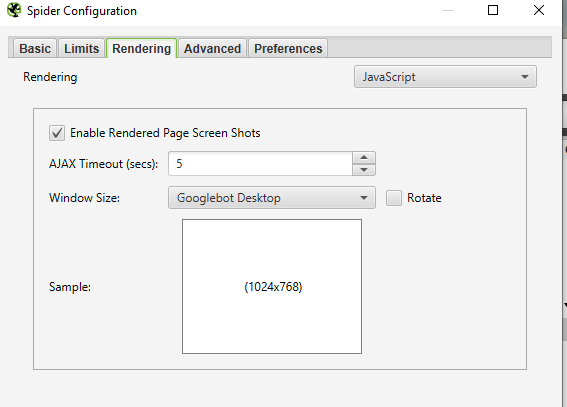
- Change rendering preferences depending on what you’re looking for. You can adjust the timeout time, window size (mobile, tablet, desktop, etc)
- Hit OK and crawl the website
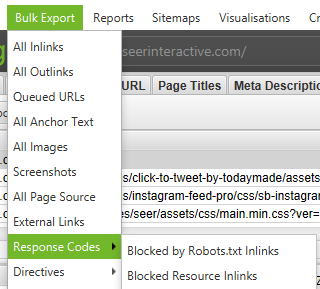
Within the bottom navigation, click on the Rendered Page tab to view how the page is being rendered. If your page is not being rendered properly, check for blocked resources or extend the timeout limit within the configuration settings. If neither option helps solve the how your page is rendering, there may be a larger issue to uncover.

You can view and bulk export any blocked resources that may be impacting crawling and rendering of your website by going to ‘Bulk Export’ → ‘Response Codes’
Regex Examples
Jump to a specific Regex extraction example:
Google Analytics and Tag Manager IDs
To extract the Google Analytics ID from a page the expression needed would be –
For Google Tag Manager (GTM) it would be –

The data extracted is –

Structured Data
If the structured data is implemented in the JSON-LD format, regular expressions rather than XPath or CSS Selectors must be used:
To extract everything in the JSON-LD script tag, you could use –
Email Addresses
The following will return any alpha numeric string, that contains an @ in the middle:
The following expression will bring back fewer false positives, as it requires at least a single period in the second half of the string:
That’s it for now, but I’ll add to this list over time with more examples, for each method of extraction.
As always, you can pop us through any questions or queries to our support.
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Расширенное сканирование в режиме списка
Режим списка действительно эффективен при правильной настройке. Есть несколько интересных продвинутых способов применения, которые помогут вам сфокусировать анализ и сэкономить время и силы.
Сканирование списка URL-адресов и другого элемента
Режим списка может быть очень гибким и позволяет сканировать список загружаемых URL и другой элемент.
Например, если вы хотите просканировать список URL-адресов и их изображений. Или вам нужно было проверить список URL-адресов и их недавно реализованные канонические, AMP или hreflang, а не весь сайт. Или вы хотели собрать все внешние ссылки из списка URL-адресов для построения неработающих ссылок. Вы можете выполнить все это в режиме списка, и процесс практически такой же.
Перейдя в режим списка, удалите , которое автоматически устанавливается равным «0». Перейдите в «Конфигурация> Паук> Ограничения» и снимите флажок с конфигурации.
Это означает, что SEO Spider теперь будет сканировать ваш список URL-адресов – и все URL-адреса в том же субдомене, на который они ссылаются.
Поэтому вам необходимо контролировать, что именно сканируется, с помощью параметров детальной конфигурации. Перейдите в “Конфигурация> Паук> Сканирование”. Отключите все «Ссылки на ресурсы» и «Ссылки на страницы» в меню конфигурации для «Сканирование».
Затем выберите элементы, которые вы хотите сканировать, рядом со списком URL-адресов. Например, если вы хотите просканировать список URL-адресов и их изображений, настройка будет такой.
А если вы загрузите один URL, например страницу SEO Spider, вы увидите, что страница и ее изображения просканированы.
Эта расширенная настраиваемость позволяет проводить лазерный аудит именно тех элементов связи, которые вам нужны.
Аудит перенаправлений
Если вы проверяете перенаправления при миграции сайта, может быть особенно полезно сканировать их целевые URL-адреса и любые встречающиеся цепочки перенаправления. Это избавляет от необходимости загружать несколько списков целевых URL-адресов каждый раз, чтобы добраться до конца.
В этом случае мы рекомендуем использовать конфигурацию «всегда следовать перенаправлениям» в разделе «Конфигурация> Паук> Дополнительно». Включение этой конфигурации означает, что «предел глубины сканирования» игнорируется, и перенаправления будут выполняться до тех пор, пока они не достигнут ответа, отличного от 3XX (или вашего, пока не будет достигнут предел «» в разделе «Конфигурация> Паук> Ограничения»).
Если вы затем воспользуетесь отчетом «Все перенаправления», он отобразит полную цепочку перенаправлений в одном отчете.
Пожалуйста, прочтите наше руководство по аудиту перенаправлений при миграции сайта для получения более подробной информации об этом процессе.
Подключение к API
В режиме списка вы можете подключиться к API-интерфейсам , , и инструментов анализа обратных ссылок для получения данных. Например, вы можете подключиться к и получить такие данные, как ссылающиеся домены, ключевые слова, трафик и ценность, которые затем отображаются на вкладке «Показатели ссылок».
Это может быть очень полезно, например, при сборе данных для конкурентного анализа.
Serpstat
Serpstat — многофункциональная платформа, которая дает возможность:
- seo-аудита сайта,
- поисковой аналитики,
- мониторинга позиций,
- исследования рынка,
- анализа ключевых фраз, платной выдачи, ссылок и конкурентов.
Помогает выявить и исправить такие seo-ошибки, как некорректные заголовки, неправильно настроенная карта сайта, ошибки в адресах страниц и др. Анализирует ссылочную массу сайта, определяет сайты-конкуренты, их позиции в поисковой выдаче и видимость, отслеживает динамические изменения различных показателей, например, объема трафика вашего сайта и конкурентов. Собирает самые эффективные ключевые слова из разных региональных баз и определяет их ценность. Осуществляет анализ рекламных компаний и контента сайтов-конкурентов, популярных запросов в той или иной бизнес-нише.
Особенности:
- есть расширения для браузеров Chrome, Mozilla, Opera,
- есть API и возможность интеграции с системами сбора информации вашего сайта,
- можно добавлять пользователей без дополнительной платы: открывать доступ к проекту или давать возможность отслеживать его показатели,
- для визуализации данных используется коннектор Serpstat и Google Data Studio, но он доступен только для пользователей с учетной записью Serpstat и лимитами для API,
- при долгосрочной подписке действуют скидки.
Загрузка списка
Когда вы находитесь в режиме списка (Режим> Список), просто нажмите кнопку «Загрузить» и выберите загрузку из файла, войдите в диалоговое окно, вставьте список URL-адресов или загрузите XML-карту сайта.

Это так просто. Но есть пара вещей, о которых вам следует знать в режиме списка при загрузке URL-адресов.
Требуется протокол
Если вы не включите ни HTTP, ни HTTPS (например, просто www.screamingfrog.co.uk/), URL-адрес не будет прочитан и выгружен.

Вы увидите очень печальное сообщение «найдено 0 URL-адресов». Поэтому всегда включайте URL-адрес с протоколом, например –
Нормализация и дедупликация
SEO Spider нормализует URL-адреса при загрузке и устраняет дублирование во время сканирования. Допустим, у вас есть следующие 4 URL-адреса для загрузки, например –
SEO Spider автоматически определит, сколько уникальных URL-адресов нужно сканировать.
Для небольшого списка легко увидеть (для большинства специалистов по поисковой оптимизации), что эти 4 URL-адреса на самом деле являются только 2-мя уникальными URL-адресами, но с более крупными списками это может быть менее очевидным.
Страница SEO Spider дублируется, а URL-адрес фрагмента (с ‘#’) не рассматривается как отдельный уникальный URL-адрес, поэтому он нормализуется при загрузке.
Если эти URL-адреса загружены в SEO Spider, он сообщит, что нашел 4 URL-адреса – и нормализует их в диалоговом окне окна –

Однако при сканировании он будет сканировать только уникальные URL-адреса (в данном случае 2).
Хотя он просканировал только 2 уникальных URL из 4 загруженных, вы все равно можете экспортировать исходный загруженный список в том же порядке.
Exporting Data
You’re able to export all data into spread sheets from the crawl. Simply click the ‘export’ button in the top left hand corner to export data from the top window tabs and filters.
To export lower window data, right click on the URL(s) that you wish to export data from in the top window, then click on one of the options.
There’s also a ‘Bulk Export’ option located under the top level menu. This allows you to export the source links, for example the ‘inlinks’ to URLs with specific status codes such as 2XX, 3XX, 4XX or 5XX responses.
In the above, selecting the ‘Client Error 4XX In Links’ option above will export all inlinks to all error pages (pages that link to 404 error pages).
macOS
Open a terminal, found in the Utilities folder in the Applications folder, or directly using spotlight and typing: ‘Terminal’.
There are two ways to start the SEO Spider from the command line. You can use either the open command or the ScreamingFrogSEOSpiderLauncher script. The open command returns immediately allowing you to close the Terminal after. The ScreamingFrogSEOSpiderLauncher logs to the Terminal until the SEO Spider exits, closing the Terminal kills the SEO Spider.
To start the UI using the open command:
open "/Applications/Screaming Frog SEO Spider.app"
To start the UI using the ScreamingFrogSEOSpiderLauncher script:
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher
To see a full list of the command line options available:
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --help

The following examples we show both ways of launching the SEO Spider.
To open a saved crawl file:
open "/Applications/Screaming Frog SEO Spider.app" --args /tmp/crawl.seospider
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher /tmp/crawl.seospider
To start the UI and immediately start crawling:
open "/Applications/Screaming Frog SEO Spider.app" --args --crawl https://www.example.com/
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --crawl https://www.example.com/
To start headless, immediately start crawling and save the crawl along with Internal->All and Response Codes->Client Error (4xx) filters:
open "/Applications/Screaming Frog SEO Spider.app" --args --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
Please see the full list of available to supply as arguments for the SEO Spider.
4) Cookies
You can now also store cookies from across a crawl. You can choose to extract them via ‘Config > Spider > Extraction’ and selecting ‘Cookies’. These will then be shown in full in the lower window Cookies tab.
You’ll need to use mode to get an accurate view of cookies, which are loaded on the page using JavaScript or pixel image tags.
The SEO Spider will collect cookie name, value, domain (first or third party), expiry as well as attributes such as secure and HttpOnly.
This data can then be analysed in aggregate to help with cookie audits, such as those for GDPR via ‘Reports > Cookies > Cookie Summary’.
You can also highlight multiple URLs at a time to analyse in bulk, or export via the ‘Bulk Export > Web > All Cookies’.
Please note – When you choose to store cookies, the auto exclusion performed by the SEO Spider for Google Analytics tracking tags is disabled to provide an accurate view of all cookies issued.
This means it will affect your analytics reporting, unless you choose to exclude any tracking scripts from firing by using the configuration (‘Config > Exclude’) or filter out the ‘Screaming Frog SEO Spider’ user-agent similar to .
Licence Activation
If you wish to use the free version, you can ignore this step. However, if you wish to crawl more than 500 URLs, save and re-open crawls and access the advanced features, then you can buy a licence.
When you purchase a licence, you are provided with a username and licence key which should be entered within the application under ‘Licence > Enter Licence Key’.

When entered correctly the licence will say it’s valid and show the expiry date. You will then be required to restart the application to remove the crawl limit and enable access to the configuration and paid features.

If the licence says it’s invalid, please read our FAQ on to troubleshoot.
Referr.ru
Крауд-маркетиновая платформа.
Помогает увеличить ссылочную массу сайта и сделать динамику ссылочного профиля положительной, исправляет анкор-лист. Решает такие вопросы, как улучшение узнаваемости сайта, обеспечение роста его позиций, повышение видимости, продвижение контента, привлечение целевой аудитории и рост репутации сайта.
Особенности:
- платформа работает на нескольких языках: русском, английском, немецком, польском, испанском, итальянском,
- не применяются автоматические решения,
- все ссылки и комментарии проходят проверку на соответствие техническому заданию,
- поддержка персонального менеджера и индивидуальный подход: стратегия, бюджет и объем кампании формируются исходя из ваших задач и возможностей,
- есть возможность разработки индивидуальных предложений и партнерская программа.
2) Site Structure Comparison
The right-hand ‘Site Structure’ tab shows a directory tree overview of how the structure of a site has evolved. It allows you to identify which directories have new or missing pages, for example, you can see new files have been found within the /sites/, /fixture/ and /news/ directories below.

This can help provide more context to how a site is changing between crawls.
It aggregates data from the previous and current crawl to show where URLs have either been added to a directory or have been removed. You can click in and drill down to see which specific URLs have changed.

You’re also able to visualise how crawl depth has changed between current and previous crawls, which helps understand changes to internal linking and architecture.

Netpeak Software
Netpeak Software включает три основных инструмента для решения seo-задач:
- Netpeak Spider для комплексного аудита сайта,
- Netpeak Checker для анализа и сравнения сайтов,
- десктопное приложение Netpeak Launcher для взаимодействия с этими двумя программами.
Netpeak Spider
Позволяет проводить быстрый seo-аудит сайта, находить ошибки технической и внутренней оптимизации, битые ссылки, дубли страниц, осуществлять парсинг сайтов, анализ нескольких десятков seo-параметров, а также исходного кода и HTTP-заголовков. Помогает рассчитать внутренний PageRank и провести более детальный анализ данных, благодаря возможности их сегментации, создать при помощи встроенного генератора карту сайта (форматы html, txt, xml) и проверить, есть ли в ней ошибки.
Особенности:
- интеграция с Google Analytics, Search Console и Яндекс.Метрики,
- парсер сайтов позволяет использовать 4 вида поиска (содержит Regexp, XPath, CSS) и до 100 условий,
- результаты аудита можно генерировать в PDF,
- возможность мультидоменного сканирования,
- есть центр поддержки,
- доступна бесплатная 14-дневная пробная версия,
- есть скидки от 5 до 40% при покупке лицензии на длительный срок (1–3 года) или нескольких лицензий,
- есть партнерская программа и возможность бесплатного использования при условии публикации обзора на продукты Netpeak Software.
Netpeak Checker
Подходит для массового анализа и сравнения сайтов. Встроенный парсер собирает данные из поисковой выдачи Google, Яндекс, Bing и Yahoo. Программа дает возможность проверять проиндексированность страниц, оценивать видимость сайтов и сравнивать их по большому количеству показателей различных seo-сервисов, проводить анализ ссылочного профиля с использованием ресурсов Serpstat, SimilarWeb, Moz, Ahrefs, Majestic, Alexa, социальных сетей и др. Функционал Netpeak Checker позволяет определять возраст сайтов, доступность доменов для покупки, осуществлять постраничный технический аудит сайта, а также проверять его скорость и адаптацию для мобильных устройств.
Особенности:
- в парсинге есть настройки по геолокации, стране, языку, типу сниппета и др.,
- поддерживает списки прокси и сервисов по решению капчи,
- доступен экспорт данных в форматы csv или xlsx, есть возможность настройки выгрузки отчетов и отображения данных,
- есть центр поддержки,
- доступна бесплатная 14-дневная пробная версия,
- при оформлении подписки на год действует скидка 20%,
- есть партнерская программа и возможность бесплатного использования при условии публикации обзора на продукты Netpeak Software.

10 крутых онлайн-курсов с сертификатами по digital-маркетингу
По теме
10 крутых онлайн-курсов с сертификатами по digital-маркетингу
7) Updated SERP Snippet Emulator
Google increased the average length of SERP snippets significantly in November last year, where they jumped from around 156 characters to over 300. Based upon our research, the default max description length filters have been increased to 320 characters and 1,866 pixels on desktop within the SEO Spider.
The lower window has also been updated to reflect this change, so you can view how your page might appear in Google.

It’s worth remembering that this is for desktop. Mobile search snippets also increased, but from our research, are quite a bit smaller – approx. 1,535px for descriptions, which is generally below 230 characters. So, if a lot of your traffic and conversions are via mobile, you may wish to update your max description preferences under ‘Config > Spider > Preferences’. You can switch ‘device’ type within the SERP snippet emulator to view how these appear different to desktop.
As outlined previously, the SERP snippet emulator might still be occasionally a word out in either direction compared to what you see in the Google SERP due to exact pixel sizes and boundaries. Google also sometimes cut descriptions off much earlier (particularly for video), so please use just as an approximate guide.
2) Щелкните вкладку «Коды ответов» и выберите фильтр «Перенаправление (3XX)», чтобы просмотреть перенаправления.
Вы можете подождать, пока сканирование не завершится и не достигнет 100%, или вы можете просто просмотреть перенаправления 3XX во время сканирования, перейдя на вкладку «Коды ответа» и используя фильтр для «Перенаправления 3XX».
Есть два способа сделать это: вы можете просто щелкнуть «вкладку» вверху и использовать раскрывающийся фильтр, или вы можете использовать панель обзора сканирования в правом окне и просто щелкнуть прямо по дереву «Перенаправление (3XX)». в папке “Коды ответов”.
Статус и код статуса показаны рядом с каждым URL-адресом, и будут отображаться как «внутренние», так и «внешние» перенаправления URL-адресов. В столбце «URI перенаправления» отображается пункт назначения перенаправления URL-адреса в столбце «Адрес».

Эта панель обзора сканирования обновляется во время сканирования, поэтому вы можете сразу увидеть количество имеющихся у вас ссылок с ошибкой клиента 3XX. В приведенном выше примере есть 93 редиректа, что составляет 13% ссылок, обнаруженных при сканировании.
Popular Uses & Advanced Features
We can’t cover every use and feature in the tool, so we recommend you explore the options available and refer to our thorough user guide where necessary.
However, we’ve compiled a list of some of the most common uses of the SEO Spider with links for additional reading.
- Find Broken Links – Crawl a website instantly and find broken links (404s) and server errors. Bulk export the errors and source URLs to fix, or send to a developer.
- Audit Redirects – Find temporary and permanent redirects, identify redirect chains and loops, or upload a list of URLs to audit in a site migration.
- Analyse & – Review page titles and meta descriptions of every page to discover unoptimised, missing, duplicate, long or short elements.
- Review & Canonicals – View URLs blocked by robots.txt, meta robots or X-Robots-Tag directives such as ‘noindex’ or ‘nofollow’, and audit canonicals.
- Find Missing Image Alt Text & Attributes – Find images that are missing alt text and view the alt text of every image in a crawl.
- Check For Duplicate Content – Analyse the website for exact duplicate pages, and near duplicate ‘similar’ content.
- Crawl JavaScript Websites – Render web pages using the integrated Chromium WRS to crawl dynamic, JavaScript rich websites and frameworks, such as Angular, React and Vue.js.
- Visualise Site Architecture – Evaluate internal linking and URL structure using interactive crawl and directory force-directed diagrams and tree graph site visualisations.
- Generate XML Sitemaps – Quickly create XML Sitemaps and Image XML Sitemaps, with advanced configuration over URLs to include, last modified, priority and change frequency.
- Audit International Set-Up (hreflang) – Find common errors and issue with hreflang annotations in HTML, via HTTP Header or in XML Sitemaps at scale.
- – Connect to the PSI API for Lighthouse metrics, speed opportunities, diagnostics and Chrome User Experience Report (CrUX) data at scale.
We have also compiled a list of some of the most popular features.
- – Schedule crawls to run automatically within the SEO Spider, as a one-off, or at chosen intervals.
- – Connect to the , and APIs and fetch user and performance data for all URLs in a crawl for greater insight.
- – Find anything you want in the source code of a website. Whether that’s Google Analytics code, specific text, or code etc.
- Extract Data With XPath – Collect any data from the HTML of a web page using CSS Path, XPath or regex. This might include social meta tags, additional headings, prices, SKUs or more.
- – Login to a staging website using basic, digest or web forms authentication.
- – Run crawls programmatically via command line to integrate with your own internal systems.