Кейс: поисковые подсказки яндекса для расширения семантического ядра сайта
Содержание:
- Что такое поисковые подсказки и зачем они нужны
- Обработка результатов#
- VLOOKUP — ищем значения в другом диапазоне данных
- Пословный саджест
- IMPORTXML — парсим данные с веб-страниц
- Сбор поисковых подсказок, используем сервис Пиксель Тулс и программу Кей Коллектор
- Где найти поисковые подсказки в виде вопросов и как собрать
- Что делать с подсказками дальше
- Инструмент парсинга поисковых подсказок от Click.ru
- Что это
- Определение LSI-копирайтинга
- Как происходит формирование поисковых подсказок (ПП) в Яндексе и Гугле
- IMPORTRANGE — импортируем данные из других таблиц
- Примеры запросов#
- Зачем нужны парсеры
- Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
- Сетевые истории
Что такое поисковые подсказки и зачем они нужны
Поисковые подсказки — это фразы, которые появляются в виде списка автозаполнения, как только пользователь начинает вводить искомую фразу в поисковой строке.
Поисковые подсказки в Google:

Поисковые подсказки в Яндексе:

Поисковые подсказки в YouTube:

По одной и той же фразе поисковики выдают разные подсказки. Дело в том, что каждый поисковик формирует подсказки по собственным алгоритмам. Но есть ряд общих факторов, которые объединяют все поисковые системы.
Что учитывают поисковые системы при подборе поисковых подсказок:
- Популярность поискового запроса в данный момент времени (актуальные и трендовые запросы вроде «что такое инаугурация» или «что такое криптовалюта» выводятся в первую очередь).
- История пользовательского поиска (каждый пользователь склонен просматривать страницы определенных тематик чаще других, и поисковики формируют подсказки в зависимости от интересов).
- Местоположение пользователя (учитывается актуальность запросов для конкретного региона).
- Фактор разнообразия (поисковые системы «подмешивают» варианты подсказок из разных тематик, чтобы повысить вероятность того, что пользователь воспользуется автоподстановкой).
Подсказки обновляются не реже одного раза в день, в отличие от баз Вордстата и Keyword Planner. Поэтому они более актуальны на данный момент времени, отражают текущие тренды и потребности аудитории.
Фразы из подсказок значительно расширяют и дополняют базовую семантику (в том числе LSI-фразами), позволяют поймать «горячий» и сезонный трафик. Среди них вы наверняка найдете ключи, которых не выдаст ни Вордстат, ни Keyword Planner.

В итоге у вас целый перечень дополнительных LSI-фраз (названия популярных моделей газонокосилок Bosch и комплектующих), которые стоит упомянуть в тексте.
Обработка результатов#
A-Parser позволяет обрабатывать результаты непосредственно во время парсинга, в этом разделе мы привели наиболее популярные кейсы для парсера SE::Yandex::Suggest
Опция Парсить до уровня (Parse to level)
Опция указывает парсеру переходить по соседним страницам сайта в глубину до указанного уровня, например:
- Если указан 1-ый уровень то парсер перейдёт по всем ссылкам указанным на исходной странице
- Если указан 2-ой уровень то парсер перейдёт по всем ссылкам указанным на исходной странице + по всем ссылкам собранным со страниц на первом уровне
- и т.д.
Простыми словами — это минимальное число кликов между исходной страницей и конечной
Т.к. на соседних страницах скорее всего будут ссылки на исходную страницу или повторы ссылок, то для того чтобы парсер не зациклился, и не ходил по кругу, необходимо обязательно включать уникальность запросов (Unique queries)
Скачать пример
eJx1VFtv2jAU/iuRhdRVYohSeFjeKBrSJlZYaR8m4MGrD5FXx85sh1FF+e89xwlJ
WOmL5XP7zncudsE8dy9uZcGBdyzeFCwLdxaz9dc4/sW1gGMcr/MkAeejz9GKWweR
N5GCA6gIjjzNFLA+y8hgCWNzKRQ9BOx5rvBWMP+aAaYwB7BWCgqXAuW9sSn3SCC4
sQNXObn1Ko0bVPZPVz1XgW63+uqalR3AzEuj3QkvcFoQ0RbtZlh+TEDZTtrRaMLK
3a7P6vTzkJ34ZDeDuk2Ncc0P8GioBhnacYpB6Z6noQrBPZD1VMb1wB8JgQshiTZX
VQbqYZv1Scu/gY7zVuoE/VG0EtzcmhTVHgIIKV9PDDesF2SGMHmI/1nFsNjbHPrM
Ids5Ry6iMey5cmiRHiz3xi7rTsYFM3qqVOhi6xbg73KpBM58usegb3XgZZflO4yy
qbCbCufxzyKHBiVId8sfbZQwC5Ng4dpg2Uqm0qPsZibXNJshKl8AsqZt9+SWGgtN
mhq5zo67n4Gm4bdTm2at6qyMs8mcK5+N3stkWS/UyTPXj/jAlnpm6JlQXTpXCqfi
4KHdkKmrx0BCS/D/4FlIgbSal8S8Mcp9X1dUMytxAydEMMVOdrPWkM9cqaeHRdfC
2o1CYZsPx+MhnbeTcB937pU+nONRFAQIpwjn79Z8+6XSM0rpITG4i9iQctf8E82X
U1z8LeKixFH/cavKm/pCvqjDBjucIz7k8g0dHqJw
Скопировать
Фильтрация результатов (использование минус-слов)
Использовав минус-слова возможно стразу убирать реультаты которые вам не нужны.
Аналогично используя фильтр можно и оставлять только те результаты которые содержат нужные слова.

Скачать пример
eJx1VFtv0zAU/iuVNWlMGlWvEuStq6gEKutYuwfU9sFrToKZYwfbKZ1C/jvHl1zK
yot1rt+5uySG6hf9oECD0STaliR3NInI+lMUfacihlMUrYs0BW1673sLxg2oHpxo
lnMgtySnSoOyvttLLmgRQ0ILjlRJzGsOCC2PoBSLrTuLkU+kyqjBwM6MHCkvrNmV
l+i+17+7vtIedLcT1zek6gDmhkmhazyX0xKOwFu04aD6fwJcdcKORtMuduIqRn3I
L9oGyoYLCZH9bbDbeCcFQhrM+fCjA7wrBpPJxL7jD+59dpKDow9/HDN0zNTRg46p
p5+d0XjUUUxah7Gtx7cCo5Fqv6+T1gvXQdvTfNgPI26Ua3qEjfSlQivGUcM9zdwk
YmrAautR3PTNySLQOGY2HuU+gt2DNuqTYL9c5dooJlK0R1Yx0AslMxQbcCBW+Fpn
uCVXjrctLZz/N+9DIqMKwJZjtguKucSNIqFco4Zh/6mRahW2ISqJFDPO3Sa0Zg7+
rmA8xr2dJej0OTheNlm9waiaCruhcKd+K8yhQXHc3epr6xXLpUyxcCGxbM4yZpDX
c1kIO5sBCl8A8qZt99YskwqaMAE5RMe7zUHYBW6nNstb0VkZZ5M5Fx6kSFi6CkdR
WxZig5/DSsylPXVblyg4x6loeGw3ZKbDGCzTJviv89yFwLSa34AYKbn+svap5orh
Bk5tghl2shs1QB4o50+Py66GtBtVn9egcz+TN7fk3smo56/FvXF7ieHIPno5sSEN
pBJ3ERtS7Zu/rvkuy4s/XlRWOOqf+sFb275YW5Rhg7U7zmH1F8zL3Bw=
Скопировать
VLOOKUP — ищем значения в другом диапазоне данных
Функция выполняет поиск ключа в первом столбце диапазона и возвращает значение указанной ячейки в найденной строке.
Синтаксис:
Пример 1. Есть два массива ключевых фраз, полученных из разных источников. Нужно найти ключи в первом массиве, которые не встречаются во втором массиве. Для этого используем формулу:
Что мы сделали:
- задали диапазон A2:A, из которого берем ключи для сравнения;
- задали диапазон B2:B, с которым сравниваем ключи из столбца А;
- задали номер столбца (1), из которого подтягиваем ключи при совпадениях;
- false — указали, что сортировка нам не нужна.
Функция VLOOKUP часто используется при поиске данных на разных листах или в разных документах.
Пример 2. Мы выгрузили данные из Яндекс.Вебмастера и Google Search Console об индексации страниц сайта. Наша задача — сопоставить данные и определить, какие страницы индексируются в одном поисковике, но не индексируются в другом.
Заносим результаты выгрузок в файл Google Sheets. На одном листе — URL из Google, на втором — из Яндекса.
В ячейке C2 прописываем функцию VLOOKUP. Сразу заключаем в функцию в ARRAYFORMULA для автоматического протягивания вниз:
Теперь мы сразу видим, какие страницы проиндексированы в Google, но не проиндексированы в Яндексе.
Что мы сделали:
- задали диапазон A2:A текущего листа, из которого берем значение для сравнения;
- задали диапазон Yandex!A2:A листа с выгрузкой из Яндекса, с которым будем сравнивать значения URL из Google;
- указали номер столбца листа с выгрузкой из Яндекса, значения из которого подтягиваем при совпадении значений из сравниваемых диапазонов;
- false — указали, что сортировка нам не нужна.
Каким пользоваться этим инструментом и в каких ситуациях он полезен, читайте в этом гайде.
Пословный саджест
К началу 2016 года Поиск Яндекса на мобильных подошёл с так называемым tap-ahead вариантом саджеста. Если на десктопе мы как показывали, так и продолжаем показывать обычный «строчный» вариант саджеста, в котором при нажатии на строчку с подсказкой немедленно задаётся запрос, в tap-ahead варианте саджеста механика сложнее.
Идея заключается вот в чём. Десктопные клавиатуры – удобные и, как правило, пользователи набирают тексты с их использованием довольно быстро. На мобильных ситуация другая и поэтому, если в подсказках нет нужного пользователю варианта, ему намного сложнее просто дописать недостающую часть запроса. Поэтому первое слово каждого запроса решили сопроводить плюсиком и специально пометить. При нажатии на это выделение слово добавлялось к уже набранному тексту запроса, а перехода в поиск при этом не происходило. Так можно было слово за словом набрать нужный запрос.
Проблема с tap-ahead саджестом в том, что пользователи его не понимают. Признаться, я его тоже не понимаю, даже спустя полтора года работы в саджесте. Чем запоминать, в какие места можно нажимать, а в какие – нет, проще просто ввести запрос целиком. Вот и пользователи тоже так делали.
Намного проще для восприятия было бы визуально разнести элементы, имеющие разную функциональность. Так появился пословный саджест, который работает в мобильном поиске Яндекса с февраля 2016 года. На тот момент он выглядел вот так:
В таком варианте вообще исчезла возможность сразу задать длинный запрос целиком. Можно сказать, что так и было задумано: на мобильных экранах чрезвычайно мало места, и концы длинных запросов неминуемо терялись из виду. В итоге, пользователи вообще не понимали, что они спрашивают, и им приходилось часто изменять текст уже введённого запроса.
IMPORTXML — парсим данные с веб-страниц
«Развесистая» функция для парсинга данных с веб-страниц с помощью XPath.
Синтаксис:
Вот лишь несколько вариантов использования этой функции:
- извлечение метаданных из списка URL (title, description), а также заголовков h1-h6;
- сбор e-mail со страниц;
- парсинг адресов страниц в соцсетях.
Пример. Нам нужно собрать содержимое тегов title для списка URL. Запрос XPath, который мы используем для получения этого заголовка, выглядит так: «//title».
Формула будет такой:
IMPORTXML не работает с ARRAYFORMULA, так что вручную копируем формулу во все ячейки.
Вот другие запросы XPath, которые вам будут полезны:
- выгрузить заголовки H1 (и по аналогии — h2-h6): //h1
- спарсить мета-теги description: //meta/@content
- спарсить мета-теги keywords: //meta/@content
- извлечь e-mail адреса: //a/@href
- извлечь ссылки на профили в соцсетях: //a[contains(href, ‘vk.com/’) or contains(href, ‘twitter.com/’) or contains(href, ‘facebook.com/’) or contains(href, ‘instagram.com/’) or contains(href, ‘youtube.com/’)]/@href
Если вам нужно узнать XPath-запрос для других элементов страницы, откройте ее в Google Chrome, перейдите в режим просмотра кода, найдите элемент, кликните по нему правой кнопкой и нажмите Copy / Copy XPath.
Сбор поисковых подсказок, используем сервис Пиксель Тулс и программу Кей Коллектор
В этом разделе статьи, мы рассмотрим сервис Пиксель Тулс для сбора подсказок и программу Кей Коллектор. Для того чтобы собирать ключевые подсказки в Пиксель Тулс, Вам необходимо там зарегистрироваться, и пополнить баланс на сумму 300 рублей. Этого вполне хватит для покупки лимитов сервиса для обслуживания.
После входа на данный ресурс, у Вас станет доступна его панель управления. С левой стороны сайта ищем в самом низу две функции: поисковые подсказки Яндекса и Гугла. Далее, нажимаем на одну из них и пишем в специальном поле, ключевое слово (Скрин 3).
После этого кликаете «Проверить». Когда проверка закончится, Вы получите результаты. Это будут готовые поисковые подсказки Яндекса.
Утилита Кей Коллектор в данный момент является платной программой. Её основной лицензионный софт стоит 1800 рублей. Если её покупать оптом, ее стоимость составит 1100 рублей — цены можно посмотреть здесь – (www.key-collector.ru). Покупайте программу, скачивайте и устанавливаете её на компьютер.
Далее, заходите в раздел «Настройки» программы и устанавливаете там поисковые системы Яндекс, Гугл. Затем, в разделе «Подсказки» нужно установить регион поиска «Авто-определение» и «Сохранить изменения». Далее, загружаете из файла заготовленные ключевые слова и запускаете программу с помощью кнопки «Начать сбор». В конце работы, она также, как и сервис Пиксель Тулс выдаст Вам все поисковые запросы.
Где найти поисковые подсказки в виде вопросов и как собрать
Эти сервисы по-своему удобны. Но есть сервис, наиболее подходящий для работы SEO-оптимизатора по созданию семантического ядра для конкретного сайта. Этот сервис называется Prodvigator.
Его особенность в том, что он дает возможность получить рекомендации в виде вопросов. Эти вопросы — реальные запросы пользователей. Отвечая на эти вопросы, можно привлечь большое количество посетителей на ресурс. Пользоваться сервисом достаточно просто:
- Нужно ввести в строку поиска заданный запрос, выбрать поисковую систему и перейти во вкладку «Поисковые подсказки», выйдет большое количество ключевых фраз.
- Более точные данные позволит получить настройка парсинга. Для этого в фильтрах нужно выбрать «Только ключевые слова без топонимов» и прописать вручную слова, которые требуется очистить из выдачи. Перед каждым таким словом необходимо поставить знак минуса. После нажатия кнопки «Применить» выходит уже гораздо меньшее количество ключевых фраз.
- Переход во вкладку «Только вопросы» поможет увидеть список фраз, которые состоят только из вопросов. Их можно использовать для написания статьи, релевантной запросам пользователей.
- Функция «пакетный экспорт» позволит просмотреть поисковые подсказки по нескольким ключевым фразам. Сервис дает возможность ввести до 200 таких фраз и получить поисковые подсказки в Яндексе по каждой в виде отчета. Для этого ключевые фразы вводятся в нужное поле, результаты фильтруются по топонимам и выбираются лишь вопросительные варианты.
Использование этой возможности в создании или расширении существующего семантического ядра позволяет получить список релевантных и актуальных фраз, которые обязательно приведут на сайт трафик. Ведь это именно те запросы, что используют для нахождения товаров и/или услуг реальные пользователи.
По работе с поисковыми подсказками вышла не так давно книга, нашего соотечественника Скорых Михаила. Для того, чтобы вникнуть в суть работы подсказок, как работать с негативными подсказками, формирование их для длинных запросов, какие бонусы это может принести, рекомендуем начать с нее.
Что делать с подсказками дальше
Итак, вы получили файл с поисковыми подсказками. Ваши дальнейшие действия:
- Пройдитесь по списку и удалите нерелевантные фразы.
- Оставшиеся запросы объедините с исходными фразами на одном листе в файле XLSX.
- Загрузите этот файл в инструмент кластеризации, и вы получите готовое семантическое ядро.
Если вы решите предварительно собрать частотности полученных из подсказок ключей, чтобы отсечь «нули», советуем быть внимательными: статистика Wordstat не поспевает за актуальными трендами, поэтому вы можете случайно удалить запросы с низкой конкуренцией и высоким спросом (просто они еще не попали в базу Wordstat).
Инструмент парсинга поисковых подсказок от Click.ru
Собирать поисковые подсказки вручную долго. Для решения этой задачи в Click.ru есть инструмент сбора поисковых подсказок. Он парсит поисковые подсказки из Яндекса, Google и YouTube.
Для решения каких задач подходит этот инструмент:
- Сбор дополнительной семантики для рекламной кампании.
- Сбор семантики для расширения семантического ядра сайта.
- Определение интересов аудитории.
- Формирование тегов для роликов в YouTube.
- Поиск новых тем для написания контента и съемки видео.
Основные возможности парсера Click.ru:
Преимущества инструмента:
- Самая низкая цена на рынке — в 3-5 раз ниже, чем у конкурентов.
- Инструмент работает «в облаке» — не нужно скачивать и устанавливать софт;
- Парсинг осуществляется в фоновом режиме, не нужно держать браузер открытым;
- Нет необходимости создавать фейковые аккаунты в поисковиках и вводить капчу;
- Результаты парсинга хранятся на удаленном сервере и доступны для скачивания в формате XLSX в любое время.
Что это
Являются удобным инструментом систем Яндекс и Гугл, позволяющим упростить и ускорить работу пользователей по поиску нужной информации среди множества запросов. При введении своего слова в строку поиска юзер видит все возможные варианты предложений по данной теме. При этом возможные варианты сменяются в зависимости от следующего введенного в поисковую строку браузера слова.
Первой их ввел Google. Произошло это в 2004 году. Еще через 4 года эти возможности системы были усовершенствованы. В 2010 году функционал стал еще лучше — теперь можно видеть загрузку результатов по мере того, как вводят каждое слово.
Механизм представляет только актуальные, то есть начальные, введенные фразы, навел SEO-оптимизаторов на мысль, что это можно использовать для создания семантического ядра сайта. При таком подходе контент сайта будет максимально релевантен запросу пользователей.
Определение LSI-копирайтинга
LSI, латентное семантическое индексирование, основано на технологии LSA, латентном семантическом анализе. Эта методика используется для автоматической индексации текста и проверки семантической структуры на наличие логических связей.
LSA задействует обновленные алгоритмы обработки данных с целью обнаружить в тексте не просто шквал ключевых слов, соответствующих поисковому запросу пользователя, а уловить общий смысл материала. С помощью LSA Яндекс, Google и другие поисковые машины могут находить для людей релевантный и полезный контент.
Подробнее о LSA
Ключевая задача LSA как метода – выявить логические связи в тексте. Поисковые боты используют эту методику для анализа естественного языка и формирования общей идеи текста, чтобы выдать статью в результатах поиска при вводе соответствующего запроса (в тот же Google или Яндекс).
Механизм LSA представляет собой систему сопоставления запроса с встречающимися в статьях терминами, а также модель анализа часто встречающихся в тексте слов с их определениями (проверка на соответствие фразы конкретной теме). Этот процесс позволяет «понять» тематику материала и оценить его качество без оглядки на плотность используемых ключевых слов.
Кратакая история индексации статей в интернете (появление тематического ядра)
В нулевых поиск работал примерно следующим образом:
-
Вы вводите какой-то поисковой запрос. Например, «купить гитара Москва недорого».
-
Получаете на первой странице десятки статей, которые идеально подогнаны под SEO благодаря огромному количеству ключей в тексте. Но смысла и пользы в этих статьях никакой.
На ранжирование влияли именно ключи. Они вставлялись даже в том случае, если не вписывались в текст логически и визуально. Тексты трудно было читать, они не несли внятной смысловой нагрузки, но все равно были в топ-10 статей по запросу.
С появлением новых алгоритмов (после 2011 года) поисковики научились анализировать содержимое текстов и фильтровать некачественные материалы, содержащие избыток ключей в груде исковерканного текста.
В ход пошли синонимы, ассоциации, гиперонимы, любые связанные текстовые элементы. В общем, некое тематическое ядро, напрямую не зависящее от выбранных ключевых слов. Именно тематическое ядро стало главным критерием при определении релевантности и качества текстов.
Пример тематического ядра
Блогер Koma Live в своей публикации на Medium описал наглядный пример использования тематического ядра и его влияния на результаты поиска.
Представим себе часто используемый поисковой запрос – «гольф». И вы взялись писать текст на эту тему, используя только одно ключевое слово. Основываясь только на нем, поисковик не сможет понять, о чем ваша статья. Об игре? Об автомобиле? Или о длинных носках? Поэтому робот будет пытаться проанализировать контекст (то самое тематическое ядро).
По этой причине копирайтерам в ТЗ часто указывают не только основные ключевые запросы, но и дополнительные слова, которые нужно использовать, чтобы сыграть на LSI-факторе (помимо SEO).
Проблема ключевых слов с длинным хвостом
Любой запрос в интернете, даже самый длинный, является ключом. Даже что-то в духе «обзор на лучшие ноутбуки 2020 года для программистов: HP, Lenovo, MSI, Samsung». Такие фразы не видны при поиске в подсказках Google, но они существуют и могут быть использованы для оптимизации.
Проблема таких ключей заключается в их избыточном количестве. И оптимизировать текст под каждый из них не получится. Отсюда возникает вопрос: оптимизировать текст под длинные ключи или просто упомянуть эти слова в контексте всего материала? На практике, при прочих равных, лучше работает второй метод.
LSI-копирайтинг на том и построен, что автор текста без определенных намерений адаптирует текст под бесконечное множество «хвостатых ключей», создавая тематическое ядро, которое поможет поисковику найти статью и закинуть ее в топ. Главное, чтобы сам материал оставался качественным.
Как происходит формирование поисковых подсказок (ПП) в Яндексе и Гугле
Формирование подобных фраз происходит путем работы сложных алгоритмов при влиянии многих факторов. К ним относятся:
- Частота фраз в поиске. ПС предлагают пользователю наиболее популярные хвосты к введенному запросу.
- Регионы для коммерческого запроса. Если посетитель ищет окна в Воронеже, ПС, как правило, не дает ему хвост из других регионов.
- Ориентация на пользователя. ПС ориентируются на часто запрашиваемые этим пользователем слова, на историю его поиска и другую персональную информацию.
- Обновление. Относится к новостным вопросам, поэтому окно с подсказками обновляется постоянно.
- Фильтр. Удаляются нецензурные слова, запросы с ошибками и опечатками, низкопопулярные фразы.
IMPORTRANGE — импортируем данные из других таблиц
Функция позволяет вставить в текущий файл данные из других таблиц.
Синтаксис:
Пример:
Пример. Вы продвигаете сайт клиента. Над проектом работает три специалиста: линкбилдер, SEO-специалист и копирайтер. Каждый ведет свой отчет. Клиент заинтересован отслеживать процесс в режиме онлайн. Вы формируете для него один отчет с вкладками: «Ссылки», «Позиции», «Тексты». На эти вкладки с помощью функции IMPORTRANGE подтягиваются данные по каждому направлению.
Преимущество функции в том, что вы открываете доступ только к конкретным листам. При этом внутренние части отчетов специалистов остаются недоступны для клиентов.
Примеры запросов#
форекс
написать реферат
рефераты онлайн
купить машину в Москве
новости
Скопировать
Подстановки запросов
Вы можете использовать для автоматической подстановки подзапросов из файлов, например мы хотим к кажому запросу добавить какой-то список других слов, укажем несколько основных запросов:
essay
article
thesis
Скопировать
В формате запросов укажем макрос подстановки дополнительных слов из файла Keywords.txt, данный метод позволяет увеличить вариативность запросов многократно:
{subs:Keywords} $query
Скопировать
Данный макрос создаст столько же дополнительных запросов сколько их находится в файле на каждый исходный поисковый запрос, что в сумме даст в результате работы макроса.
Например, если в файл Keywords.txt будет содержать:
buy
cheap
Скопировать
В итоге макрос подстановок превратит 3 основных запроса в 6:
buy essay
cheap essay
buy article
cheap article
buy thesis
cheap thesis
Скопировать
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
1 Зарегистрируйтесь на Click.ru и перейдите на страницу парсера.
2 Добавьте запросы из эксель-файла или вставьте их списком.
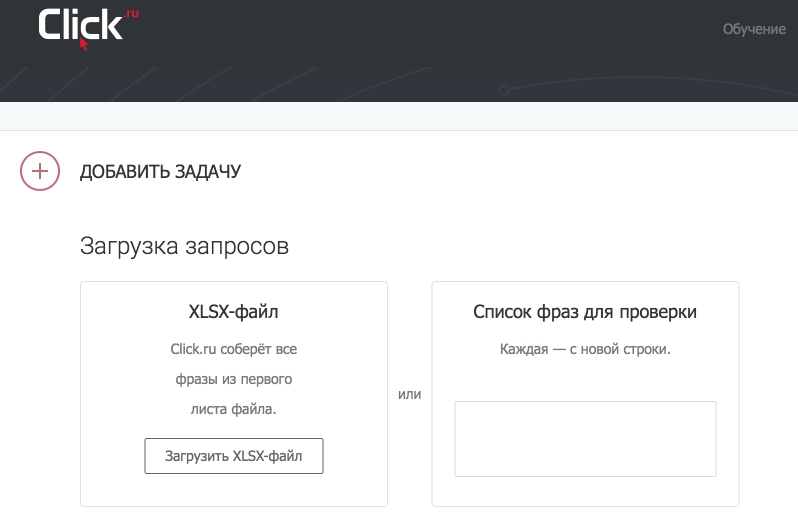 Этап загрузки запросов
Этап загрузки запросов
3 Выберите нужную поисковую систему и настройте региональность.
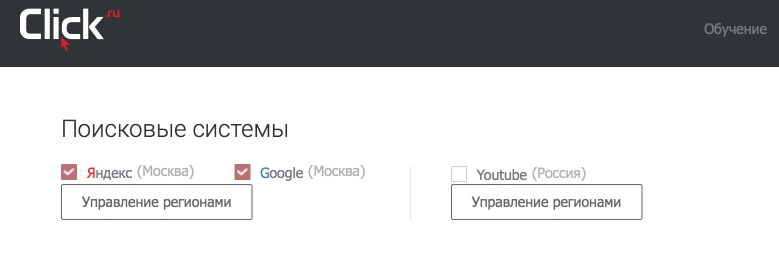 Выбор поисковых систем и управление регионами
Выбор поисковых систем и управление регионами
4 Выберите способы сбора подсказок.По умолчанию подсказки собираются только по заданным запросам. Если нужно собрать семантическое ядро по максимуму, то следует включить дополнительные опции: перебор и/или и/или .
 Просто подсказки по запросу
Просто подсказки по запросу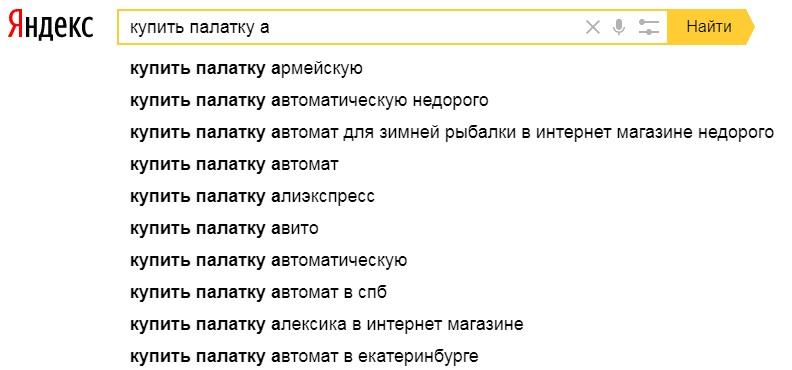 А это подсказки по запросу + первая буква алфавита. Большая разница
А это подсказки по запросу + первая буква алфавита. Большая разница
5 Укажите глубину сбора.
Если оставить первую глубину, то будут собраны подсказки по умолчанию + подсказки, полученные в результате автоподстановок и/или и/или . Если же включить вторую глубину, то вы также получите дополнительные подсказки, собранные по всем словам и фразам первого результата.
 Процесс выбора способа и глубины сбора подсказок
Процесс выбора способа и глубины сбора подсказок
6. Запустите проверку.По окончании парсинга отчет можно будет изучить в интерфейсе Click.ru или же скачать на компьютер в эксель-формате.
Стоимость сбора подсказок зависит от количества ТЗ (внутренняя валюта Click.ru). 1 ТЗ — это сбор подсказок в 1 поисковой системе в 1 регионе по 1 фразе. Чтобы сначала попробовать инструмент, платить ничего не надо, так как при регистрации в Click.ru в подарок дается 50 ТЗ.
Сетевые истории
Мы уже поняли, что скорость ввода складывается из качества данных и качества представления. Однако оказалось, что есть ещё один аспект проблемы – сетевой.
Исторически источник поисковых подсказок жил на домене , к которому поисковая вёрстка осуществляла асинхронные запросы в процессе пользовательского ввода.
К концу лета 2016 года стало понятно, что эта схема устарела. Многие сервисы уже жили за «единым доменом» : например, картинки , видео и так далее. Зачем? Чтобы экономить сетевые взаимодействия. У нас один единый балансер для всех сервисов, доступных на домене . Это означает, что, не покидая этого домена, пользователю достаточно лишь однажды установить сетевое соединение. В случае с саджестом это было не так: для похода за саджестом с домена требовалось установить новое сетевое соединение, что на 2G-интернете иногда стоило нескольких секунд ожидания.
Другим интересным моментом является поведение блокировщиков рекламы. Оказалось, некоторые из них блокируют кросс-доменные запросы. В нашем случае это привело к тому, что у некоторых пользователей саджест на несколько дней оказался полностью нефункциональным!
Поэтому мы решили провести эксперимент, в котором саджест переносится за единый для сервисов Яндекса балансер.
Тут стоит отметить, чем саджест отличается от других сервисов. Дело в том, что каждый поисковый запрос требует приблизительно столько же запросов в саджестовый источник, сколько в нём символов. Поэтому неудивительно, что типиный RPS для саджестового источника на порядки превосходит RPS других сервисов, в т.ч. большого Поиска. 100k RPS – это норма, саджест является одним из самых высоконагруженных сервисов Яндекса, непосредственно взаимодействующих с пользователями (некоторые внутренние сервисы выдерживают миллионы RPS).
Для единого балансера это означает очень существенный рост нагрузки, так что для удовлетворения нужд поисковых подсказок пришлось значительно вложиться в железо, и мы не хотели этого делать без подтверждения гипотезы о пользе для пользователей.
В результате эксперимент оказался одним из самых успешных за всё время. Его крутизна проявлялась даже в том, что пользователи начинали чаще задавать запросы в поисковую систему, не говоря уже о росте используемости саджеста и скорости ввода на единицы процентов.