Учебник: регулярные выражения (regular expressions)
Содержание:
- Модификаторы¶
- preg_match()
- Регулярные выражения в PHP
- Как правильно писать регулярные выражения ¶
- Методы Javascript для работы с регулярными выражениями
- 2 Практический раздел. Ссылки
- Основной синтаксис регулярных выражений в PHP
- Группировка
- Привязки
- Об ограничении «жадности»
- Повторения (квантификаторы)
- Символы¶
- Прочие конструкции
- Конструкции чередования
- Буквы, цифры, символы
- Строковые методы, поиск и замена
- Метасимволы
- Подстановки
- Конструкции группирования
Модификаторы¶
Синтаксис для одного модификатора: чтобы включить, и чтобы выключить. Для большого числа модификаторов используется синтаксис: .
Можно использовать внутри регулярного выражения. Это может быть особенно удобно, поскольку оно имеет локальную область видимости. Оно влияет только на ту часть регулярного выражения, которая следует за оператором .
И если оно находится внутри подвыражения, оно будет влиять только на это подвыражение, а именно на ту часть подвыражения, которая следует за оператором. Таким образом, в это влияет только на подвыражение , поэтому оно будет соответствовать , но не .
preg_match()
Функция preg_match() ищет в заданной строке совпадение для шаблона. Если совпадение найдено, возвращается TRUE, в противном случае возвращается FALSE.
Синтаксис функции preg_match():
int pregjnatch(string шаблон, string строка [, array совпадения})
При передаче необязательного параметра совпадения массив заполняется совпадениями различных подвыражений, входящих в основное регулярное выражение. В следующем примере функция preg_match() используется для проведения поиска без учета регистра:
$linе = "Vi is the greatest word processor ever created!";
// Выполнить поиск слова "Vi" без учета регистра символов:
if(preg_match("/\bVi\b\i", $line, $matcn)) :
print "Match found!";
endif;
// Команда if в этом примере возвращает TRUE
Регулярные выражения в PHP
PHP имеет встроенные функции, которые позволяют нам работать с регулярными выражениямии. Давайте теперь посмотрим на часто используемые функции регулярных выражений в PHP.
— эта функция используется для сопоставления с образцом в строке. Она возвращает истину, если совпадение найдено, и ложь, если совпадение не найдено. — эта функция используется для сопоставления с образцом в строке, а затем разбивает результаты в числовой массив. — эта функция используется для сопоставления с образцом строки и затем замены совпадения указанным текстом.Ниже приведен синтаксис функции регулярного выражения, такой как , или :
<?php
function_name('/pattern/',subject);
?>
«function_name (…)» это либо , , либо . «/…/» Косая черта обозначает начало и конец нашего регулярного выражения. «/ pattern /» — это шаблон, который нам нужен. «subject» — текстовая строка, с которой нужно сопоставить.
Давайте теперь посмотрим на практические примеры, которые реализуют вышеупомянутые функции регулярных выражений в PHP.
Как правильно писать регулярные выражения ¶
Прежде, чем садиться и писать регулярно выраженного кракена, подумайте, что именно вы хотите сделать. Регулярное выражение должно начинаться с мысли «Я хочу найти/заменить/удалить то-то и то-то». Затем вам нужен исходный текст, который содержит как ПРАВИЛЬНЫЕ, так и НЕправильные данные. Затем вы открываете https://regex101.com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
Для примера возьмём валидацию ip-адреса. Первая мысль должна быть: «Я хочу валидировать ip-адрес. А что такое ip-адрес? Из чего он состоит?». Затем нужен список валидных и невалидных адресов:
Валидный адрес должен содержать четыре числа (байта) от 0 до 255. Если он содержит число больше 255, это уже ошибка. Если бы мы делали валидацию на каком-либо языке программирования, то можно было бы разбить выражение на четыре части и проверить каждое число отдельно. Но регулярные выражения не поддерживают проверки больше или меньше, поэтому придётся делать по-другому.
Для начала упростим задачу: будем валидировать не весь ip-адрес, а только один байт. А байт это всегда есть либо одно-, либо дву-, либо трёхзначное число. Для одно- и двузначного числа шаблон очень простой — любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
Теперь, зная все диапазоны байта, можно объединить их в одно выражение через вертикальную палочку | (ИЛИ):
Обратите внимание, что я использовал границу слова \b, чтобы искать полные байты. Пробуем регулярку в деле:
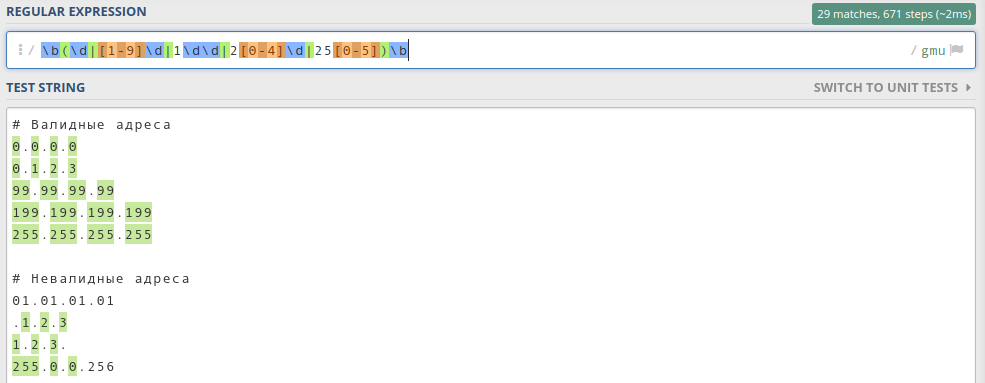
Как видим, все байты стали зелёненькими. Это значит, что мы на верном пути.
Осталось дело за малым: сделать так, чтобы искать четыре байта, а не один. Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
Результат выглядит так:

Подсветились только валидные ip-адреса, значит регулярное выражение работает корректно.
Если бы я сразу начал писать валидацию всего адреса, а не отдельного байта, то с большой долей вероятности допустил бы ошибку. Скопления скобочек, палочек и точечек трудно воспринимаются на глаз, поэтому задачу надо обязательно упрощать.
Методы Javascript для работы с регулярными выражениями
В Javascript Существует 6 методов для работы с регулярными выражениями. Чаще всего мы будем использовать только половину из них.
Метод exec()
Метод RegExp, который выполняет поиск совпадения в строке. Он возвращает массив данных. Например:
var str = 'Some fruit: Banana - 5 pieces. For 15 monkeys.'; var re = /(\w+) - (\d) pieces/ig; var result = re.exec(str); window.console.log(result); // result = // Так же мы можем посмотреть позицию совпадения - result.index
В результате мы получим массив, первым элементом которого будет вся совпавшая по паттерну строка, а дальше содержимое скобочных групп. Если совпадений с паттерном нету, то .
Метод test()
Метод RegExp, который проверяет совпадение в строке, возвращает либо true, либо false. Очень удобен, когда нам необходимо проверить наличие или отсутствие паттерна в тексте. Например:
var str = 'Balance: 145335 satoshi'; var re = /Balance:/ig; var result = re.test(str); window.console.log(result); // true
В данном примере, есть совпадение с паттерном, поэтому получаем true.
Метод search()
Метод String, который тестирует на совпадение в строке. Он возвращет индекс совпадения, или -1 если совпадений не будет найдено. Очень похож на метод indexOf() для работы со строками. Минус этого метода — он ищет только первое совпадение. Для поиска всех совпадений используйте метод match().
var str = "Умея автоматизировать процессы, можно зарабатывать миллионы"; window.console.log(str.search(/можно/igm)); // 60 window.console.log(str.search(/атата/igm)); // -1
Метод match()
Метод String, который выполняет поиск совпадения в строке. Он возвращет массив данных либо null если совпадения отсутствуют.
// Без использования скобочных групп
var str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
var regexp = //gi;
var matches_array = str.match(regexp);
window.console.log(matches_array); //
// С использованием скобочных групп без флага g
var str = 'Fruits quantity: Apple - 5, Banana - 7, Orange - 12. I like fruits.';
var found = str.match(/(\d{1,2})/i);
window.console.log(found); // Находит первое совпадение и возвращает объект
// {
// 0: "5"
// 1: "5"
// index: 25
// input: "Fruits quantity: Apple -...ge - 12. I like fruits."
// }
// С использованием скобочных групп с флагом g
var found = str.match(/(\d{1,2})/igm);
window.console.log(found); //
Если совпадений нету — возвращает null.
Метод replace()
Метод String, который выполняет поиск совпадения в строке, и заменяет совпавшую подстроку другой подстрокой переданной как аргумент в этот метод. Мы уже использовали эту функцию для работы о строками, регулярные выражения привносят новые возможности.
// Обычная замена var str = 'iMacros is awesome, and iMacros is give me profit!'; var newstr = str.replace(/iMacros/gi, 'Javascript'); window.console.log(newstr); // Javascript is awesome, and Javascript is give me profit! // Замена, используя параметры. Меняем слова местами: var re = /(\w+)\s(\w+)/; var str = 'iMacros JS'; var newstr = str.replace(re, '$2, $1'); // в переменных $1 и $2 находятся значения из скобочных групп window.console.log(newstr); // JS iMacros
У метода replace() есть очень важная особенность — он имеет свой каллбэк. То есть, в качестве аргумента мы можем подавать функцию, которая будет обрабатывать каждое найденное совпадение.
Нестандартное применение метода replace():
var str = `
I have some fruits:
Orange - 5 pieces
Banana - 7 pieces
Apple - 15 pieces
It's all.
`;
var arr = []; // Сюда складируем данные о фруктах и их количестве
var newString = str.replace(/(\w+) - (\d) pieces/igm, function (match, p1, p2, offset, string) {
window.console.log(arguments);
arr.push({
name: p1,
quantity: p2
});
return match;
});
window.console.log(newString); // Текст не изменился, как и было задумано
window.console.log(arr); // Мы получили удобный массив объектов, с которым легко и приятно работать
Как вы видите, мы использовали этот метод для обработки каждого совпадения. Мы вытащили из паттерна название фрукта и количество и поместили эти значения в массив объектов, как мы уже делали ранее
Обратите внимание на аргумент функции offset — это будет индекс начала совпадения, этот параметр нам потом пригодится. В нашем случае, мы имеем 2 скобочные группы в паттерне, поэтому у нас в функции 5 аргументов, но их там может быть и больше
Метод split()
Метод String, который использует регулярное выражение или фиксированую строку чтобы разбить строку на массив подстрок.
var str = "08-11-2016";
// Разбиваем строку по разделителю
window.console.log(str.split('-')); //
// Такой же пример с регэкспом
window.console.log(str.split(/-/)); //
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
Основной синтаксис регулярных выражений в PHP
Чтобы использовать регулярные выражения, сначала вам нужно изучить синтаксис шаблонов. Мы можем сгруппировать символы внутри шаблона следующим образом:
- Обычные символы, которые следуют один за другим, например,
- Индикаторы начала и окончания строки в виде и
- Индикаторы подсчета, такие как , ,
- Логические операторы, такие как
- Группирующие операторы, такие как , ,
Пример шаблона регулярного выражения для проверки правильности адреса электронного ящика выглядит следующим образом:
^+@+\.{2,5}$
Код PHP для проверки электронной почты с использованием Perl-совместимого регулярного выражения выглядит следующим образом:
<?php
$pattern = "/^+@+\.{2,5}$/";
$email = "some-email@test.com";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Теперь давайте посмотрим на подробный разбор синтаксиса шаблона при регулярном выражении:
| Регулярное выражение (шаблон) | Проходит проверку (объект) | Не проходит проверку (объект) | Комментарий |
| Hello world | Hello Ivan | Проходит, если шаблон присутствует где-либо в объекте | |
| world class | Hello world | Проходит, если шаблон присутствует в начале объекта | |
| Hello world | world class | Проходит, если шаблон присутствует в конце объекта | |
| This WoRLd | Hello Ivan | Выполняет поиск в нечувствительном к регистру режиме | |
| world | Hello world | Строка содержит только «world» | |
| worl, world, worlddd | wor | Присутствует 0 или больше «d» после «worl» | |
| world, worlddd | worl | Присутствует по крайней мере одна «d» после «worl» | |
| worl, world, worly | wor, wory | Присутствует 0 или 1 «d» после «worl» | |
| world | worly | Присутствует одна «d» после «worl» | |
| world, worlddd | worly | Присутствует одна или больше «d» после «worl» | |
| worldd, worlddd | world | Присутствует 2 или 3 «d» после «worl» | |
| wo, world, worldold | wa | Присутствует 0 или больше «rld» после «wo» | |
| earth, world | sun | Строка содержит «earth» или «world» | |
| world, wwrld | wrld | Содержит любой символ вместо точки | |
| world, earth | sun | Строка содержит ровно 5 символов | |
| abc, bbaccc | sun | В строке есть «a», или «b» или «c» | |
| world | WORLD | В строке есть любые строчные буквы | |
| world, WORLD, Worl12 | 123 | В строке есть любые строчные или прописные буквы | |
| earth | w, W | Фактический символ не может быть «w» или «W» |
Теперь перейдем к более сложному регулярному выражению с подробным объяснением.
Группировка
Группы (подмаски) в регулярных выражениях делаются с помощью метасимвола группировки .
Например в выражении xyz+ знак плюс относится только к букве и это выражение ищет слова типа , , . Но если поставить скобки то квантифиактор относится уже к последовательности и регулярка ищет слова , , .
Пример
Поробуй сам
Результат выполнения кода:
1
Ещё примеры:
| Выражение | Описание |
|---|---|
| ^{1,}$ | Любое слово, хотя бы одна буква, число или |
| +@ | Соответствует строке с символом @ в начале, за которым следует любая буква нижнего регистра, число от 0 до 9 или буква верхнего регистра. |
| ()() | wy, wz, xy, или xz |
| + | Один или более символов нижнего регистра |
Практические упражнения по регулярным выражениям PHP.
Назад
Вперёд
Освойте PHP и MySQL с нуля в игровой форме
На рынке не хватает веб-разработчиков
На рынке не хватает веб-разработчиков
Освойте популярный PHP-фреймворк
На рынке не хватает fullstack-разработчиков!
Обучение в рассрочку
Учитесь сейчас, платите потом!
Учитесь сейчас, платите потом!
Привязки
Привязки, или атомарные утверждения нулевой ширины, приводят к успеху или сбою сопоставления, в зависимости от текущей позиции в строке, но не предписывают обработчику перемещаться по строке или обрабатывать символы. Метасимволы, приведенные в следующей таблице, являются привязками. Дополнительные сведения см. в разделе Привязки.
| Утверждение | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| По умолчанию соответствие должно начинаться в начале строки. В многострочном режиме соответствие должно начинаться в начале линии. | в | ||
| По умолчанию соответствие должно обнаруживаться в конце строки или перед символом в конце строки. В многострочном режиме соответствие должно обнаруживаться до конца линии или перед символом в конце линии. | в | ||
| Соответствие должно обнаруживаться в начале строки. | в | ||
| Соответствие должно обнаруживаться в конце строки или до символа в конце строки. | в | ||
| Соответствие должно обнаруживаться в конце строки. | в | ||
| Соответствие должно обнаруживаться в той точке, где заканчивается предыдущее соответствие. | , , в | ||
| Соответствие должно обнаруживаться на границе между символом (алфавитно-цифровым) и символом (не алфавитно-цифровым). | , в | ||
| Соответствие не должно обнаруживаться на границе . | , в |
Об ограничении «жадности»
Для понимания, о чем идет речь, лучше сначала ознакомиться с примером:

Здесь шаблон поиска выглядит следующим образом: ‘a’, любой символ один и больше раз, ‘x’. Но выражение сработало не так, как ожидал разработчик: было захвачено максимально возможное число символов, т. е. закончилась не на первом ‘x’, а на последнем.
Данное поведение операторов повторения называют жадностью, т. к. они стремятся забрать как можно больше. Это особенность полезна, но не всегда, поэтому ее можно отменить, ограничив жадность. Для этого надо добавить к оператору повторения знак ‘?’: вместо жадных ‘+’ и » следует написать ‘+?’ и ‘?’, что ограничит эту самую жадность:

В примере выше шаблон поиска выглядит так: ‘a’, потом любой символ один либо больше раз (с ограничением жадности) и ‘x’.
Посредством ‘?’ была ограничена жадность плюсу, поэтому теперь поиск осуществляется до первого совпадения.
Жадность можно ограничивать для всех операторов повторения, включая ‘?’, ‘{}’ — выглядеть это будет так: ‘??’ и ‘{}?’.

Повторения (квантификаторы)
Комбинация типа означает, что цифра должна повторяться два раза. Но бывают задачи, когда повторений очень много или мы не знаем, сколько именно. В таких члучаях нужно использовать специальные метасимволы.
Повторения символов или комбинаций описываются с помощью квантификаторов (метасимволов, которые задают количественные отношения). Есть два типа квантификаторов: общие (задаются с помощью фигурных скобок ) и сокращенные (сокращения наиболее распространенных квантификаторов). Фигурные скобки задают число повторений предыдущего символа (в этом случае выражение ищет от 1 до 7 идущих подряд букв «x»).
| Квантификатор | Описанте |
|---|---|
| a+ | Один и более раз a |
| a* | Ноль и более раз a |
| a? | Одна a или пусто |
| a{3} | 3 раза a |
| a{3,5} | От 3 до 5 раз a |
| a{3,} | 3 и более раз a |
Примечание: Если в выражении требуется поиск одного из метасимволов, вы можете использовать обратный слэш . Например, для поиска одного или нескольких вопросительных знаков можно использовать следующее выражение:
Символы¶
Серия символов соответствует этой серии символов во входной строке.
| RegEx | Находит |
|---|---|
Непечатные символы (escape-коды)
Для представления непечатаемого символа в регулярном выражении используется с шестнадцатеричным кодом. Если код длиннее 2 цифр (более U+00FF), то он обрамляется в фигурные скобки.
RegEx
Находит
символ с 2-значным шестнадцатеричным кодом
символ с 1-4 значным шестнадцатеричным кодом
(обратите внимание на пробел в середине)
Существует ряд предопределенных для непечатных символов, как в языке :
| RegEx | Находит |
|---|---|
| tab (HT/TAB), тоже что | |
| символ новой строки (LF), то же что | |
| возврат каретки (CR), тоже что | |
| form feed (FF), то же что | |
| звонок (BEL), тоже что | |
| escape (ESC), то же что | |
| … |
chr(0) по chr(25). |
Прочие конструкции
Прочие конструкции либо изменяют шаблон регулярных выражений, либо предоставляют сведения о нем. В следующей таблице перечислены все прочие конструкции, поддерживаемые .NET. Для получения дополнительной информации см. Прочие конструкции.
| Конструкция | Определение | Пример |
|---|---|---|
| Устанавливает или отключает такие параметры, как учет регистра в середине шаблона. Дополнительные сведения см. в статье Параметры регулярных выражений. | соответствует , в | |
| comment | Встроенное примечание. Примечание заканчивается первой закрывающей скобкой. | |
| Комментарий режима X. Примечание начинается от знака без обратной косой черты и продолжается до конца строки. |
Конструкции чередования
Конструкции изменения модифицируют регулярное выражение, включая сопоставление по принципу «либо-либо». Такие конструкции состоят из языковых элементов, приведенных в следующей таблице. Дополнительные сведения см. в разделе Конструкции чередования.
| Конструкция изменения | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| Соответствует любому элементу, разделенному вертикальной чертой (). | , в | ||
| expression yes no | Соответствует да в случае соответствия шаблона регулярного выражения, определяемого выражением; в противном случае соответствует дополнительной части нет. Выражение интерпретируется как утверждение нулевой ширины. | , в | |
| name yes no | Соответствует да в случае соответствия именованной или нумерованной группы захвата имя; в противном случае соответствует дополнительной части нет. | , в |
Буквы, цифры, символы
В регулярных выражениях существуют два вида символов: обозначающие сами себя и символы, которые называют командами (спецсимволы).
Цифры и буквы обозначают сами себя, зато точка — спецсимвол, обозначающий «любой символ». Смотрим примеры:
По сути, в коде выше не существует разницы между функциями preg_replace и str_replace – функционируют они одинаково, разница заключается лишь в ограничителях.
В следующем примере можно увидеть, как использовался спецсимвол «точка» — такое уже нельзя сделать с помощью str_replace:
Раз точка — любой символ, то под регулярку подпадут все подстроки, причем по следующему шаблону: буква ‘x’, потом любой символ, потом снова ‘x’. Первые четыре подстроки попали под данный шаблон (xax xsx x&x x-x), поэтому они заменились на ‘!’. Последняя подстрока (xaax) не подпала по той причине, что внутри (между буквами ‘x’) находится не один, а два символа.
Раз точка — любой символ, а в регулярке мы видим 2 точки подряд, то под регулярку подпадут все подстроки по следующему шаблону: буква ‘x’, потом 2 любых символа, потом снова ‘x’. Первая подстрока не подпадет, т. к. она содержит лишь один символ между буквами ‘x’, в то время как последняя подстрока (xabx) шаблону соответствует.
Что тут важно запомнить: цифры и буквы обозначают сами себя, точка же заменяет любой символ. Также важно следующее: для функции preg_match точка на деле обозначает любой символ за исключением перевода строки
Дабы точка обозначала и его, необходим модификатор s.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Метасимволы
В приведенных выше примерах использовались очень простые шаблоны. Метасимволы позволяют нам выполнять более сложные сопоставления с образцом, например проверять правильность адреса электронной почты. Давайте теперь посмотрим на часто используемые метасимволы.
| Метасимвол | Описание | Пример |
|---|---|---|
| . | Соответствует любому отдельному символу, кроме новой строки | /./ соответствует всему, что имеет один символ |
| ^ | Соответствует началу или строке/исключает символы | /^PH/ соответствует любой строке, начинающейся с PH |
| $ | Соответствует шаблону в конце строки | /ru$/ соответствует it-blog.ru и т.д. |
| * | Соответствует любому нулю (0) или более символов | /com*/ соответствует computer, communication и т. д. |
| + | Требуется, чтобы предшествующие символы появлялись хотя бы раз | /yah+oo/ соответствует yahoo |
| \ | Используется для экранирования метасимволов | /yahoo+\.com/ трактует точку как буквальное значение |
| Символы внутри скобках | // соответствует abc | |
| a-z | Соответствует строчным буквам | /a-z/ соответствует cool, happy и т.д. |
| A-Z | Соответствует заглавным буквам | /A-Z/ соответствует WHAT, HOW, WHY и т.д. |
| 0-9 | Соответствует любому числу от 0 до 9 | /0-4/ соответствует 0,1,2,3,4 |
Приведенный выше список содержит только наиболее часто используемые метасимволы в регулярных выражениях.
Давайте теперь рассмотрим довольно сложный пример, который проверяет действительность адреса электронной почты.
<?php
$my_email = "name@company.com
";
if (preg_match("/^+@+\.{2,5}$/", $my_email)) {
echo "$my_email это действительный адрес электронной почты";
}
else
{
echo "$my_email это не действительный адрес электронной почты";
}
?>
Подстановки
Подстановки — это языковые элементы регулярных выражений, которые поддерживаются в шаблонах замены. Для получения дополнительной информации см. Подстановки. Приведенные в следующей таблице метасимволы являются атомарными утверждениями нулевой ширины.
| Знак | Описание | Шаблон | Шаблон замены | Входная строка | Результирующая строка |
|---|---|---|---|---|---|
| число | Замещает часть строки, соответствующую группе число. | ||||
| имя | Замещает часть строки, соответствующую именованной группе имя. | ||||
| Подставляет литерал «$». | |||||
| Замещает копией полного соответствия. | |||||
| Замещает весь текст входной строки до соответствия. | |||||
| Замещает весь текст входной строки после соответствия. | |||||
| Замещает последнюю захваченную группу. | |||||
| Замещает всю входную строку. |
Конструкции группирования
Конструкции группирования отображают части выражений регулярных выражений и обычно захватывают части строки входной строки. Конструкции группирования состоят из языковых элементов, приведенных в следующей таблице. Для получения дополнительной информации см. Конструкции группирования.
| Конструкция группирования | Описание | Шаблон | Число соответствий |
|---|---|---|---|
| subexpression | Захватывает соответствующую часть выражения и назначает ей порядковый номер, отсчитываемый от единицы. | в | |
| name subexpression или name subexpression | Выделяет соответствующую часть выражения в именованную группу. | в | |
| name1 name2 subexpression или name1 name2 subexpression | Задает сбалансированное определение группы. Дополнительные сведения см. в разделе «Сбалансированное определение группы» статьи Конструкции группирования. | в | |
| subexpression | Определяет невыделяемую группу. | в в | |
| subexpression | Применяет или отключает указанные параметры в части выражения. Для получения дополнительной информации см. Параметры регулярных выражений. | , в | |
| subexpression | Утверждение положительного просмотра вперед нулевой ширины. | , и в | |
| subexpression | Утверждение отрицательного просмотра вперед нулевой ширины. | , в | |
| subexpression | Утверждение положительного просмотра назад нулевой ширины. | , , в | |
| subexpression | Утверждение отрицательного просмотра назад нулевой ширины. | , в | |
| subexpression | Атомарная группа. | , и в |









